Ralph Kimballs dimensionelle datamodellering definerer tre typer af faktatabeller. Disse er:
- Transaction fact tables.
- Periodic snapshot tables, og
- Accumulating snapshot tables.
I dette indlæg vil vi gennemgå hver af disse typer af faktatabeller og derefter reflektere over, hvordan de ikke har ændret sig i de år, der er gået, siden Kimball sidst opdaterede Data Warehouse Toolkit. Hvis du er bekendt med disse tre kategorier af faktatabeller, kan du springe videre til analysen til sidst; hvis du ikke er det, kan du betragte dette som en kortfattet gennemgang af en af de grundlæggende komponenter i Kimball-stil datamodellering.
To hurtige bemærkninger, før vi begynder: For det første forudsætter dette stykke kendskab til stjerneskemaet. Læs dette, hvis du har brug for en grundbog – jeg vil antage, at du som et absolut minimum forstår fakta- og dimensionstabeller. For det andet vil jeg bemærke, at Kimball anerkender en fjerde type faktatabel – timespan-faktabellen – men den bruges kun under særlige omstændigheder. Vi udelukker den fra vores diskussion her.
Transaktionsfaktatabeller
Transaktionsfaktatabeller er nemme at forstå: En kunde eller forretningsproces gør noget; du ønsker at registrere forekomsten af denne ting, og derfor registrerer du en transaktion i dit datawarehouse, og så er du klar.
Dette illustreres bedst med et simpelt eksempel. Lad os forestille os, at du driver en nærbutik, og du har et elektronisk POS-system (Point of Sales), der registrerer hvert salg, du foretager.
I et typisk stjerneskema i Kimball-stil ville den faktatabel, der er i centrum af dit skema, bestå af data om bestillingstransaktioner. Det er primært numeriske mål som ordresummen, beløb for enkeltposter, omkostninger ved solgte varer, anvendte rabatbeløb osv.
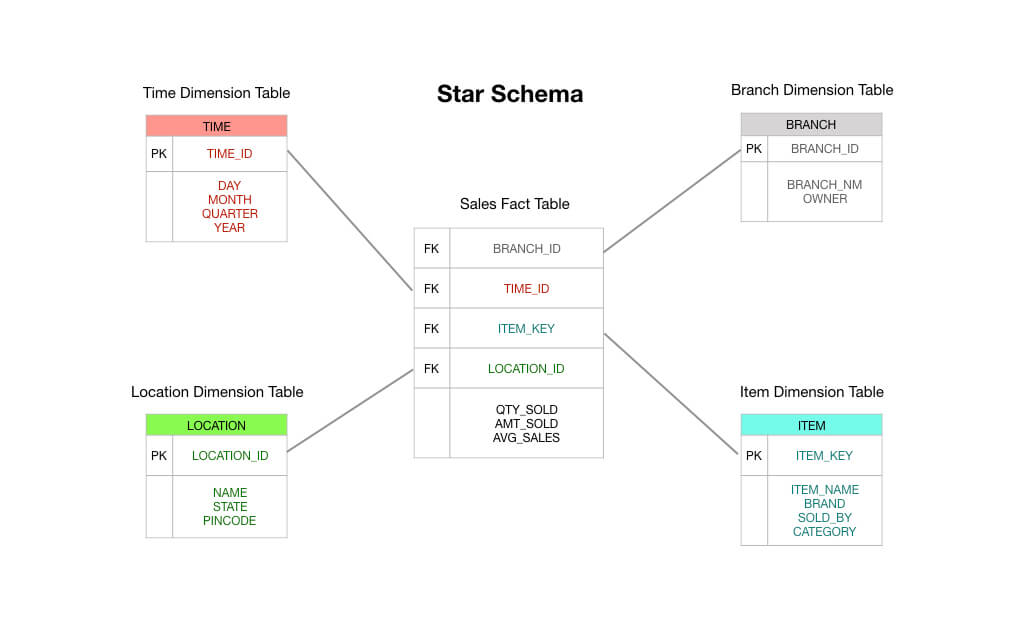
Så du kan se, at en transaktionsfaktualtabel er præcis, som der står på dåsen: Du modtager en transaktion, du registrerer transaktionen i din faktatabel, og dette bliver grundlaget for din rapportering. På mange måder er en transaktionsfaktattabel den standardtype faktatabel, som vi er vant til at tænke på.
Periodiske snapshot-tabeller
Periodiske snapshot-faktatabeller er en logisk forlængelse af de almindelige vanilla-faktatabeller, som vi lige har behandlet ovenfor. En række i en periodisk snapshot-faktatabel indeholder en eller anden form for periodiske data – f.eks. et dagligt øjebliksbillede af finansielle målinger, eller måske et ugentligt resumé af debitorer eller en månedlig opgørelse af lagernumre.
Med andre ord er “kornet” eller “opløsningsniveauet” perioden, ikke den enkelte transaktion. Bemærk, at hvis der ikke forekommer nogen transaktioner i en bestemt periode, skal der indsættes en ny række i den periodiske snapshottabel, selv om alle de gemte fakta er nul!
Periodiske snapshottabeller har tendens til at indeholde utroligt mange felter. Det skyldes, at enhver rimelig interessant metrik kan skubbes ind i periodetabellen. Du kan ligesom forestille dig et scenarie, hvor du starter med aggregeret salg, omsætning og omkostninger ved solgte varer på en ugentlig periode, men efterhånden som tiden går, beder ledelsen dig om at tilføje andre fakta som lagerniveauer, metrikker for kreditorbetalinger og andre interessante målinger.
Hvorfor er periodiske snapshot-tabeller nyttige? Tja, det er ret ligetil at forestille sig. Hvis du vil have et overblik over trendlinjerne i de vigtigste resultatindikatorer i din virksomhed, hjælper det at forespørge mod en periodisk faktatabel.
Akkumulerende øjebliksbillede tabeller
I modsætning til periodiske øjebliksbillede tabeller er akkumulerende øjebliksbillede tabeller lidt sværere at forklare. For at forstå, hvorfor Kimball og hans kolleger fandt på denne fremgangsmåde, hjælper det at forstå lidt om den slags spørgsmål, der blev stillet til erhvervslivet i 90’erne, hvilket var dengang Data Warehouse Toolkit først blev skrevet.
I slutningen af 80’erne begyndte japanske producenter at slå deres amerikanske kolleger på alle mulige ubehagelige, men ikke indlysende måder. Den vigtigste af disse var et fokus på udførelseshastighed.
Fremstilling kan ses som en række trin. Man tager råmateriale i den ene ende af fabrikken og forvandler det til biler og telefoner og widgets i den anden ende. Hvert trin i fremstillingsprocessen kan måles – hvor lang tid tager det f.eks. at omdanne stålblokke til stålpiller? Hvor længe venter de på fabrikkens lager? Og hvor lang tid går der derfra, før pelletsene fremstilles til bildele? Hvor lang tid går der, før de anvendes i egentlige biler?
I slutningen af 70’erne begyndte japanske virksomheder at indse, at dette syn på værdiskabelse i “en række trin” kunne føre til en alvorlig konkurrencefordel, hvis de reducerede tidsrummet mellem hvert trin. Mere konkret: Hvis de kunne reducere antallet af trin i produktionen af hver enkelt vare, og hvis de kunne reducere tidsforbruget inden for hvert enkelt trin, lærte de japanske producenter, at de kunne reducere materialespild, sænke fejlprocenten og forkorte leveringstiden, samtidig med at de kunne øge arbejdstagernes produktivitet, øge produktionsvolumen, udvide produktsortimentet og sænke priserne – alt sammen på samme tid.
Da 90’erne kom, havde de vestlige virksomheder fået øjnene op for det. En række ledelseskonsulenter – først og fremmest George Stalk Jr. fra Boston Consulting Group – begyndte at gøre sig til fortalere for udførelsestempo som en kilde til konkurrencefordele. Disse konsulenter pålagde virksomhederne at registrere den tid, der blev brugt på hvert trin i produktionsprocessen. Når en ordre kom ind, hvor længe ventede den så på at blive behandlet? Efter at den var blevet behandlet, hvor lang tid gik der, før ordren blev sendt til fabrikken? Hvor lang tid gik der på fabrikken, før produktet var færdigt? Og hvor længe ventede det så på lageret? Og til sidst, hvor lang tid gik der, før kunden modtog produktet og fik værdi af det?
Virksomhederne i 90’erne var således presset til at måle forsinkelsestider i hele deres forretnings leveranceproces. De blev tvunget til at gøre dette, fordi japanske konkurrenter var ved at trænge ind i mange brancher, der tidligere var domineret af vestlige virksomheder – i nogle tilfælde med konkurser til følge og med forstyrrelse af hele forsyningskæder til følge. Det var i dette miljø, Kimball arbejdede.
Den akkumulerende snapshot-faktatabel er således en metode til at måle hastigheden i forretningsprocessen. Tag for eksempel denne forretningspipeline, som Kimball præsenterede i anden udgave af The Data Warehouse Toolkit:
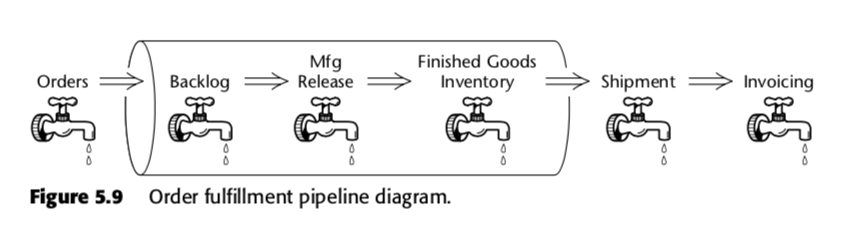
For denne proces foreslog Kimball følgende akkumulerende snapshot-tabelle:
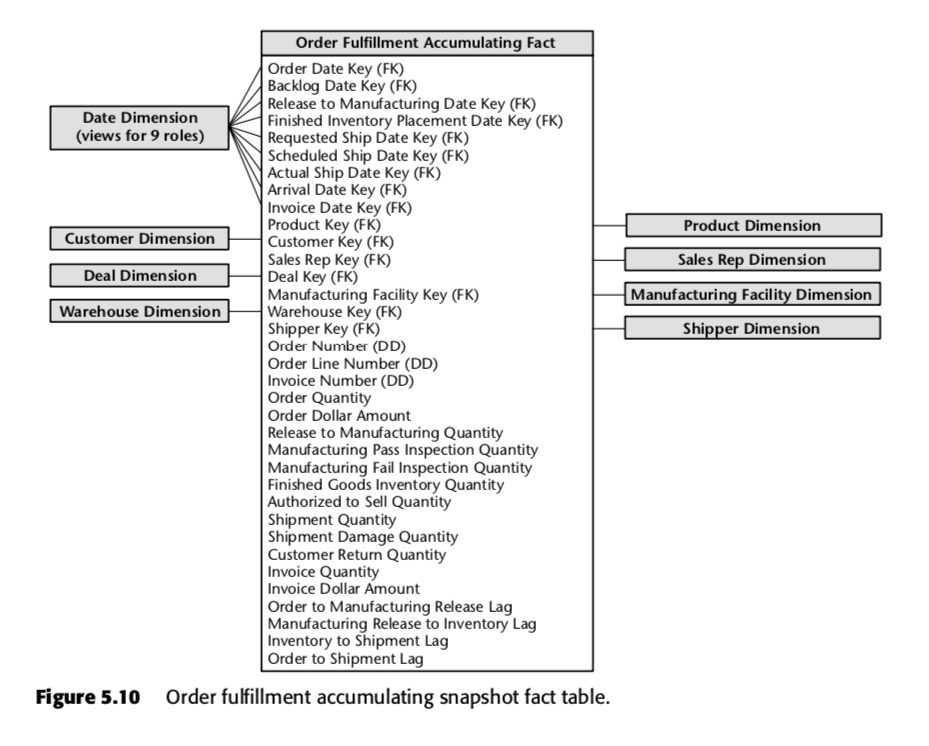
Hver række i denne tabel repræsenterer en ordre eller et parti af ordrer. Hver af disse rækker forventes at blive ajourført flere gange, efterhånden som de passerer gennem ordreopfyldelsespipelinen. Læg især mærke til det store antal datofelter øverst i skemaet. Når en række først oprettes i denne tabel, vil størstedelen af disse datoer starte som nuller, men vil efterhånden blive fyldt op, efterhånden som tiden går. (Bemærk: Kimball bruger en datadimensionstabel her i stedet for den indbyggede SQL-datadatatype, fordi det er The Kimball Way ™ – det giver dig mulighed for at indfange flere oplysninger om datoer end blot de naive datatyper.)
Det er også vigtigt at se på felterne nederst på denne liste. Hvert af dem måler en forsinkelsesindikator – det vil sige forskellen mellem to datoer. Så for eksempel er Order to Manufacturing Release Lag den tid, der går fra Order Date til Release to Manufacturing Date; Inventory to Shipment Lag er den tid, der går fra Finished Inventory Placement Date til Actual Ship Date og så videre. Efterhånden som tiden går, vil hver af disse datoer blive udfyldt af et ERP-system eller måske af en dataindtastningstjener. Efterslæbstiderne for hver enkelt ordre vil således blive beregnet, efterhånden som hvert felt udfyldes.
Du kan se, hvordan en sådan tabel vil være nyttig for en virksomhed, der opererer i et tidsbaseret konkurrencemiljø. Ved hjælp af en enkelt tabel ville ledelsen kunne se, om forsinkelsestiderne i dens produktion er stigende eller faldende over tid. De kan bruge en sådan business intelligence til at bestemme, hvilke trin der er de mest problematiske i deres produktionsproces. Og de kan gribe ind over for de dele, der er mest bekymrende for dem.
Side note: Disse idéer er blevet tilpasset til softwareverdenen under terminologien “lean”; for mere information om måling af produktion i teknologivirksomheder, se vores indlæg om bogen Accelerate her og her.
Hvorfor har de ikke ændret sig?
Det er et bevis på Kimball og hans kolleger, at de tre typer af faktatabeller ikke har ændret sig væsentligt, siden de blev formuleret første gang i 1996.
Hvorfor er dette tilfældet? Svaret, tror jeg, ligger i det faktum, at stjerneskemaet indfanger noget grundlæggende om forretning. Hvis du modellerer dine data til at matche dine forretningsprocesser, vil du stort set indfange faktadata på en af tre måder: via transaktioner, med samkørte perioder og – hvis din virksomhed er klog nok på tidsbaseret konkurrence – ved at måle forsinkelsestiderne mellem hvert trin i dit værdileveringssystem.
Kimball siger selv noget lignende. I et blogindlæg fra 2015 skriver han:
I stedet for at hænge sig i religiøse argumenter om logiske versus fysiske modeller, bør vi simpelthen erkende, at en dimensionel model faktisk er en API (Application Programming Interface) til datawarehouse-programmering. Styrken ved denne API ligger i den konsistente og ensartede grænseflade, der ses af alle observatører, både brugere og BI-applikationer. Vi ser, at det er ligegyldigt, hvor bitsene er lagret, eller hvordan de leveres, når en API-forespørgsel lanceres.
Stjerneskemaet er tidstestet. Så meget er indlysende.
I samme indlæg fortsætter Kimball så med at hævde, at selv nyere innovationer som columnar data warehouse ikke har ændret dette faktum; størstedelen af de virksomheder, han taler med, ender stadig med en dimensionel modelstruktur i sidste ende.
Men tingene har ændret sig. I hele Data Warehouse Toolkit er der mange maleriske omtaler af “begrænsning af antallet af fakta pr. tabel” og “planlægning af datamodelleringsstrategien med alle interessenter fra domænet til stede på mødet”. Dette afspejler ikke, hvad vi ser i praksis i vores virksomhed og i vores kunders dataafdelinger.
Den største ændring er den hastighed, hvormed de nuværende teknologier gør det muligt for os at gå fra “naiv faktatabel” til “dimensionel model i Kimball-stil” – hvilket gør det muligt for os at springe over den forudgående modellering og i stedet vælge at modellere så lidt, som vi har brug for. Denne praksis er muliggjort af en række teknologiske ændringer, som vi har diskuteret på denne blog før (især i vores indlæg om The Rise and Fall of the OLAP Cube), men de praktiske konsekvenser for vores brug af faktatabeller er som følger:
- Transaktionsfaktatabeller – vi er helt tilfredse med at have fede faktatabeller med dusinvis, hvis ikke hundredevis af fakta pr. række! Dermed ikke sagt, at dette er en ideel situation, men blot at det er et meget acceptabelt kompromis. I modsætning til på Kimballs tid er datatalenter i dag uoverkommeligt dyre; lager- og beregningstid er billig. Så vi er helt ok med at lade visse faktatabeller være som de er – faktisk har vi flere med mere end 100 felter i dem, som er hentet direkte fra vores kildesystemer! Vores filosofiske holdning er: Hvis vi har komplekse rapporteringskrav, er det det værd at tage sig tid til at modellere dataene ordentligt. Men hvis de rapporter, vi har brug for, er enkle, så udnytter vi den computerkraft, vi har til rådighed, og lader faktabellerne være som de er.
- Periodiske snapshot-faktatabeller – det er overraskende, hvor meget vi er i stand til at undgå at gøre dette. Fordi moderne MPP-søjleformede datawarehouses er så kraftfulde, opretter vi ikke periodiske snapshot-faktatabeller for rapporter, der ikke bruges så regelmæssigt. Den tid, det tager at udføre forespørgsler, og de ekstra omkostninger, det kræver at generere rapporter fra rå transaktionsdata, er helt acceptabelt, især hvis vi ved, at rapporten kun er nødvendig en gang om ugen eller deromkring (eller gøres tilgængelig til periodisk udforskning). For andre datasæt genererer vi periodiske snapshot-tabeller i overensstemmelse med Kimballs oprindelige anbefalinger.
- Akkumulering af snapshot-tabeller – Dette er næsten uændret i forhold til Kimballs tid. Men – som Kimball selv siger – er akkumulerende snapshot-tabeller sjældne i praksis. Så vi tænker ikke så meget over dette, som en mere tidsstyret virksomhed måske ville gøre.
Det er vigtigt at bemærke her, at vi mener, at modellering er vigtig. Forskellen er, at vores praksis med dataanalyser gør det muligt for os at genoverveje vores modelleringsbeslutninger på et hvilket som helst tidspunkt i fremtiden. Hvordan gør vi det? Jo, vi indlæser vores rå transaktionsdata i vores datawarehouse, før vi transformerer dem. Dette er kendt som “ELT” i modsætning til “ETL”. Fordi vi foretager alle vores transformationer i datawarehouset ved hjælp af et datamodelleringslag, er vi i stand til at genoverveje vores valg og omforme vores data, hvis behovet opstår.
Dette giver os mulighed for at fokusere på at levere forretningsværdi først. Det holder datamodelleringens travle arbejde lavt.