La modélisation dimensionnelle des données de Ralph Kimball définit trois types de tables de faits. Ce sont :
- Tables de faits de transactions.
- Tables d’instantanés périodiques, et
- Tables d’instantanés d’accumulation.
Dans ce billet, nous allons passer en revue chacun de ces types de tables de faits, puis réfléchir à la façon dont elles n’ont pas changé depuis la dernière mise à jour du Data Warehouse Toolkit de Kimball. Si vous êtes familier avec ces trois catégories de tables de faits, passez directement à l’analyse à la fin ; si vous ne l’êtes pas, considérez ceci comme une promenade concise à travers l’un des composants de base de la modélisation de données de style Kimball.
Deux notes rapides avant de commencer : premièrement, cette pièce suppose une familiarité avec le schéma en étoile. Lisez ceci si vous avez besoin d’une amorce – je vais supposer que vous comprenez les tables de faits et de dimensions comme un strict minimum. Deuxièmement, je note que Kimball reconnaît un quatrième type de table de faits – la table de faits temporels – mais elle n’est utilisée que dans des circonstances particulières. Nous laisserons cela en dehors de notre discussion ici.
Tables de faits de transaction
Les tables de faits de transaction sont faciles à comprendre : un client ou un processus d’affaires fait quelque chose ; vous voulez capturer l’occurrence de cette chose, et donc vous enregistrez une transaction dans votre entrepôt de données et vous êtes prêt à partir.
Cela est mieux illustré avec un exemple simple. Imaginons que vous dirigez une supérette, et que vous avez un système électronique de point de vente (POS) qui enregistre chaque vente que vous faites.
Dans un schéma en étoile typique de Kimball, la table de faits qui est au centre de votre schéma serait constituée de données de transaction de commande. Il s’agit principalement de mesures numériques comme le total de la commande, les montants des articles de ligne, le coût des marchandises vendues, les montants des remises appliquées, et ainsi de suite.
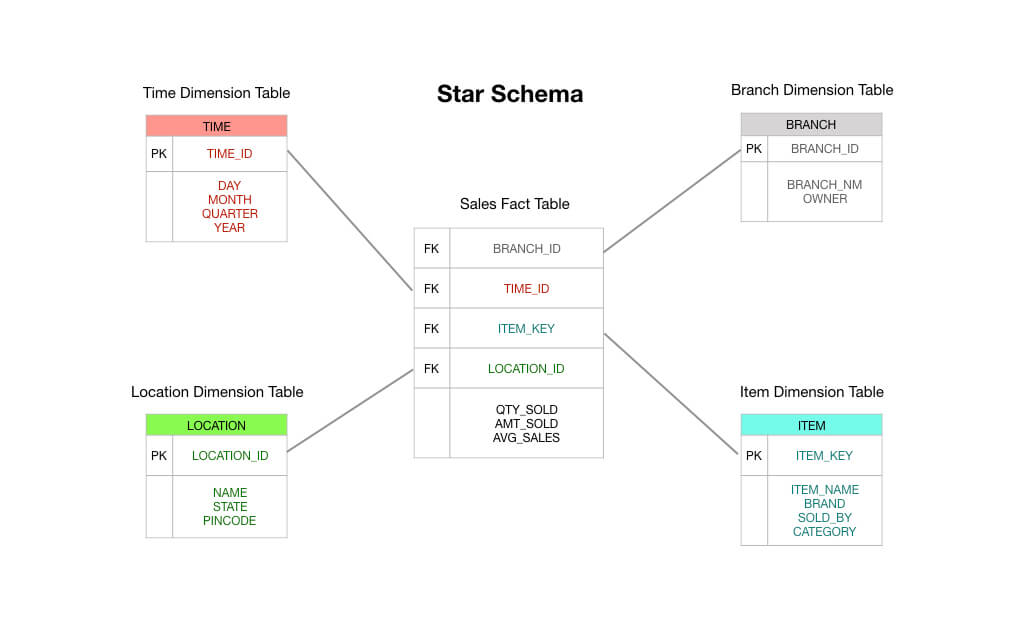
Et donc vous pouvez voir qu’une table de faits de transaction est exactement ce qu’elle dit sur la boîte : vous recevez une transaction, vous enregistrez la transaction dans votre table de faits, et cela devient la base de votre reporting. À bien des égards, une table de faits de transaction est le type de table de faits par défaut auquel nous avons l’habitude de penser.
Tables d’instantanés périodiques
Les tables de faits d’instantanés périodiques sont une extension logique des tables de faits plain vanilla que nous venons de couvrir ci-dessus. Une ligne dans une table de faits d’instantanés périodiques capture une sorte de données périodiques – par exemple, un instantané quotidien des métriques financières, ou peut-être un résumé hebdomadaire des comptes clients, ou un décompte mensuel des numéros de stock.
En d’autres termes, le « grain » ou le « niveau de résolution » est la période, et non la transaction individuelle. Notez que si aucune transaction ne se produit pendant une certaine période, une nouvelle ligne doit être insérée dans la table d’instantanés périodiques, même si chaque fait sauvegardé est un null!
Les tables d’instantanés périodiques ont tendance à contenir un nombre incroyablement grand de champs. C’est parce que toute métrique raisonnablement intéressante peut être poussée dans la table périodique. Vous pouvez en quelque sorte imaginer un scénario où vous commencez avec des ventes agrégées, des revenus et le coût des marchandises vendues sur une période hebdomadaire, mais au fil du temps, la direction vous demande d’ajouter d’autres faits comme les niveaux d’inventaire, les métriques des comptes fournisseurs et d’autres mesures intéressantes.
Pourquoi les tables d’instantanés périodiques sont-elles utiles ? Eh bien, c’est assez simple à imaginer. Si vous voulez avoir une vue d’ensemble des lignes de tendance des indicateurs clés de performance dans votre entreprise, il est utile d’effectuer une requête contre une table de faits périodique.
Tables d’instantanés accumulatifs
Contrairement aux tables d’instantanés périodiques, les tables d’instantanés accumulatifs sont un peu plus difficiles à expliquer. Pour comprendre pourquoi Kimball et ses pairs ont imaginé cette approche, il est utile de comprendre un peu le genre de questions que l’on posait aux entreprises dans les années 90, c’est-à-dire au moment où le Data Warehouse Toolkit a été écrit pour la première fois.
À la fin des années 80, les fabricants japonais ont commencé à battre leurs homologues américains sur toutes sortes de façons méchantes mais non évidentes. Le principal d’entre eux était de se concentrer sur la vitesse d’exécution.
La fabrication peut être considérée comme une série d’étapes. Vous prenez de la matière première à une extrémité de l’usine, et vous la transformez en voitures, téléphones et gadgets à l’autre extrémité. Chaque étape du processus de fabrication peut être mesurée – combien de temps faut-il pour transformer des blocs d’acier en granulés d’acier, par exemple ? Combien de temps attendent-elles dans les stocks de l’usine ? Et à partir de là, combien de temps avant que les boulettes ne soient transformées en pièces automobiles ? Combien de temps avant qu’elles ne soient utilisées dans de véritables automobiles ?
À la fin des années 70, les entreprises japonaises ont commencé à réaliser que cette vision de la création de valeur en » séries d’étapes » pouvait conduire à un sérieux avantage concurrentiel si elles réduisaient le temps de latence entre chaque étape. Plus concrètement : s’ils pouvaient réduire le nombre d’étapes nécessaires à la production de chaque article et s’ils pouvaient réduire la durée de chaque étape, les fabricants japonais ont appris qu’ils pouvaient réduire les déchets de matériaux, diminuer les taux de défauts et réduire les délais de livraison, tout en augmentant la productivité des travailleurs, en augmentant le volume de fabrication, en élargissant la variété des produits et en réduisant les prix – tout cela en même temps.
Au moment où les années 90 sont arrivées, les entreprises occidentales avaient compris. Un certain nombre de consultants en gestion – au premier rang desquels George Stalk Jr du Boston Consulting Group – ont commencé à défendre le rythme d’exécution comme source d’avantage concurrentiel. Ces consultants ont demandé aux entreprises d’enregistrer le temps passé à chaque étape du processus de production. Lorsqu’une commande arrivait, combien de temps attendait-elle d’être traitée ? Après son traitement, combien de temps avant que la commande ne soit envoyée à l’usine ? À l’usine, combien de temps avant que le produit soit terminé ? Et ensuite, combien de temps a-t-il attendu en stock ? Et enfin, combien de temps a-t-il fallu avant que le client ne reçoive le produit et n’en tire de la valeur ?
Les entreprises des années 90 ont donc été poussées à mesurer les délais tout au long de leur processus de livraison. Elles ont été forcées de le faire parce que les concurrents japonais faisaient des incursions dans de nombreuses industries précédemment dominées par les entreprises occidentales – dans certains cas, en provoquant des faillites et en perturbant des chaînes d’approvisionnement entières. C’est dans cet environnement que Kimball travaillait.
Le tableau de faits d’instantanés cumulés est donc une méthode pour mesurer la vélocité au sein du processus d’affaires. Prenons, par exemple, ce pipeline métier, que Kimball a présenté dans la deuxième édition de The Data Warehouse Toolkit :
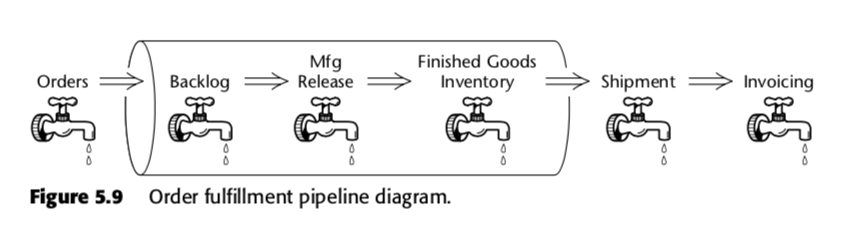
Pour ce processus, Kimball a proposé le tableau d’instantanés cumulés suivant :
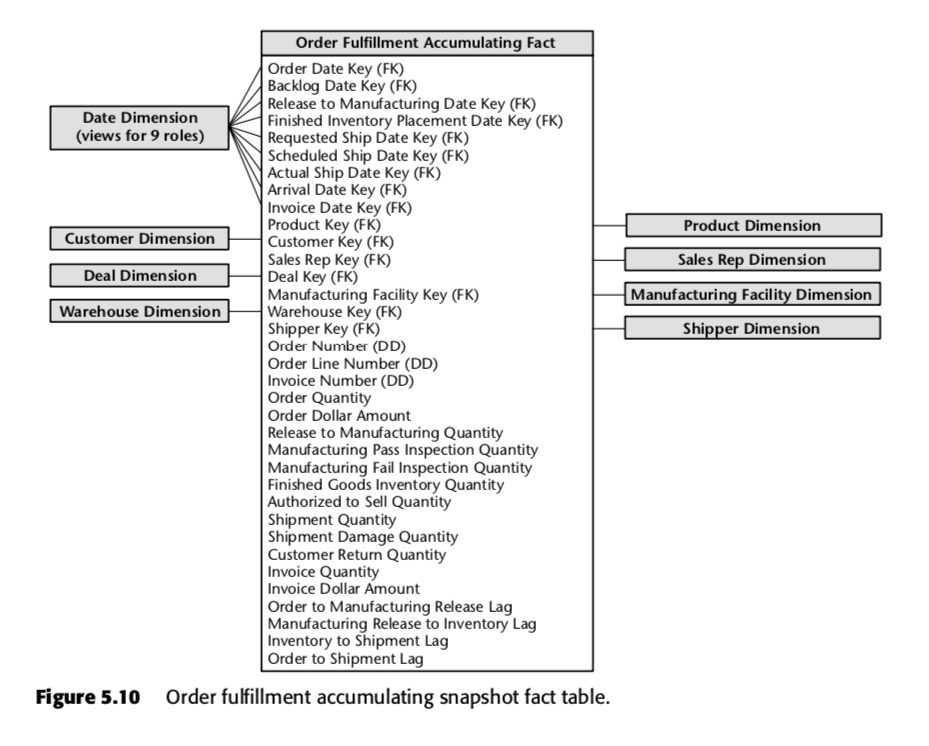
Chaque ligne de ce tableau représente une commande ou un lot de commandes. Chacune de ces lignes est censée être mise à jour plusieurs fois au fur et à mesure qu’elle progresse dans le pipeline d’exécution des commandes. Remarquez en particulier le nombre impressionnant de champs de date en haut du schéma. Lorsqu’une ligne est créée pour la première fois dans cette table, la majorité de ces dates sont nulles au départ, mais elles finissent par être remplies au fil du temps. (Note : Kimball utilise ici un tableau de dimension de date, au lieu du type de données de date SQL intégré, parce que faire ainsi est The Kimball Way ™ – cela vous permet de capturer plus d’informations sur les dates que les types de date naïfs.)
Les champs au bas de cette liste sont également importants. Chacun d’entre eux mesure un indicateur de décalage – c’est-à-dire la différence entre deux dates. Ainsi, par exemple, Order to Manufacturing Release Lag est le temps mis entre Order Date et Release to Manufacturing Date ; Inventory to Shipment Lag est le temps mis entre Finished Inventory Placement Date et Actual Ship Date, et ainsi de suite. Au fur et à mesure que le temps passe, chacune de ces dates sera renseignée par un système ERP ou peut-être par un grunt de saisie de données. Les délais pour chaque commande particulière seraient donc calculés au fur et à mesure que chaque champ est rempli.
Vous pouvez voir comment un tel tableau serait utile à une entreprise opérant dans un environnement concurrentiel basé sur le temps. En utilisant un seul tableau, la direction serait en mesure de voir si les délais de sa production augmentent ou diminuent au fil du temps. Elle peut utiliser cette intelligence d’affaires pour déterminer les étapes qui posent le plus de problèmes dans son processus de production. Et ils peuvent prendre des mesures sur les bits qui les inquiètent le plus.
Note annexe : ces idées ont été adaptées au monde du logiciel sous la terminologie de » lean » ; pour plus d’informations sur la mesure de la production au sein des entreprises technologiques, consultez nos posts sur le livre Accelerate ici et ici.
Pourquoi n’ont-ils pas changé ?
C’est un témoignage de Kimball et de ses pairs que les trois types de tableaux de faits n’ont pas changé matériellement depuis qu’ils ont été articulés pour la première fois en 1996.
Pourquoi est-ce le cas ? La réponse, je pense, réside dans le fait que le schéma en étoile capture quelque chose de fondamental sur les affaires. Si vous modélisez vos données pour qu’elles correspondent à vos processus d’affaires, vous allez à peu près capturer les données factuelles de l’une des trois façons suivantes : via des transactions, avec des périodes collationnées et – si votre entreprise est assez avisée en matière de concurrence basée sur le temps – en mesurant les temps de latence entre chaque étape de votre système de prestation de valeur.
Kimball lui-même dit quelque chose de similaire. Dans un billet de blog de 2015, il écrit :
Plutôt que de s’accrocher à des arguments religieux sur les modèles logiques par rapport aux modèles physiques, nous devrions simplement reconnaître qu’un modèle dimensionnel est en fait une interface de programmation d’applications (API) d’entrepôt de données. La puissance de cette API réside dans l’interface cohérente et uniforme vue par tous les observateurs, tant les utilisateurs que les applications de BI. Nous voyons que l’endroit où les bits sont stockés ou la façon dont ils sont livrés lorsqu’une demande d’API est lancée n’a pas d’importance.
Le schéma en étoile est éprouvé par le temps. Cela est évident.
Dans le même post, Kimball poursuit ensuite en affirmant que même les innovations récentes comme l’entrepôt de données en colonnes n’ont pas changé ce fait ; la majorité des entreprises auxquelles il s’adresse se retrouvent toujours avec une structure de modèle dimensionnel à la fin de la journée.
Mais les choses ont changé. Dans le Data Warehouse Toolkit, on trouve des mentions pittoresques de » limitation du nombre de faits par table » et de » planification de votre stratégie de modélisation des données avec toutes les parties prenantes du domaine présentes à la réunion « . Ces mentions ne reflètent pas ce que nous observons dans la pratique au sein de notre entreprise, et dans les départements de données de nos clients.
Le plus grand changement est la vitesse à laquelle les technologies actuelles nous permettent de passer de la » table de faits naïve » au » modèle dimensionnel de style Kimball » – ce qui nous permet de sauter la pratique de la modélisation initiale, et d’opter plutôt pour une modélisation aussi faible que nécessaire. Cette pratique est rendue possible par un certain nombre de changements technologiques dont nous avons déjà parlé sur ce blog (notamment dans notre billet sur The Rise and Fall of the OLAP Cube), mais les implications pratiques sur notre utilisation des tables de faits sont les suivantes :
- Tables de faits transactionnelles – nous sommes parfaitement heureux d’avoir de grosses tables de faits, avec des dizaines, voire des centaines de faits par ligne ! Cela ne veut pas dire que c’est une situation idéale, simplement que c’est un compromis très acceptable. Contrairement à l’époque de Kimball, le talent des données est aujourd’hui prohibitif ; le stockage et le temps de calcul sont bon marché. Nous sommes donc tout à fait d’accord pour laisser certains tableaux de données tels quels – en fait, nous en avons plusieurs qui contiennent plus de 100 champs, provenant directement de nos systèmes sources ! Notre position philosophique est la suivante : si nous avons des exigences complexes en matière de rapports, il vaut la peine de prendre le temps de modéliser les données correctement. Mais si les rapports dont nous avons besoin sont simples, alors nous profitons de la puissance de calcul dont nous disposons et laissons les tables de faits telles quelles.
- Tables de faits à instantanés périodiques – il est surprenant de constater à quel point nous sommes capables d’éviter de faire cela. Parce que les entrepôts de données colonnaires MPP modernes sont si puissants, nous ne créons pas de tables de faits snapshot périodiques pour les rapports qui ne sont pas aussi régulièrement utilisés. Le temps d’exécution des requêtes et le coût supplémentaire qu’il faut pour générer des rapports à partir de données transactionnelles brutes sont parfaitement acceptables, surtout si nous savons que le rapport n’est nécessaire qu’une fois par semaine environ (ou qu’il est disponible pour une exploration périodique). Pour d’autres ensembles de données, nous générons des tableaux d’instantanés périodiques conformément aux recommandations originales de Kimball.
- Accumulation de tableaux d’instantanés – Ceci est presque inchangé depuis l’époque de Kimball. Mais – comme Kimball le dit lui-même – l’accumulation de tables d’instantanés est rare en pratique. Nous n’y réfléchissons donc pas autant qu’une entreprise plus axée sur le temps pourrait le faire.
Il est important de noter ici que nous pensons effectivement que la modélisation est importante. La différence est que notre pratique de l’analyse des données nous permet de revoir nos décisions de modélisation à tout moment dans le futur. Comment faisons-nous cela ? Eh bien, nous chargeons nos données transactionnelles brutes dans notre entrepôt de données avant de les transformer. C’est ce qu’on appelle « ELT », par opposition à « ETL ». Parce que nous effectuons toutes nos transformations au sein de l’entrepôt de données, en utilisant une couche de modélisation de données, nous sommes en mesure de revoir nos choix et de remodeler nos données si le besoin s’en fait sentir.
Cela nous permet de nous concentrer d’abord sur la fourniture de valeur métier. Cela permet de maintenir le travail de modélisation des données à un faible niveau.