Modelarea dimensională a datelor de către Ralph Kimball definește trei tipuri de tabele de date. Acestea sunt:
- Tabele de fapte de tranzacție.
- Tabele de instantanee periodice și
- Tabele de instantanee de acumulare.
În această postare, vom trece în revistă fiecare dintre aceste tipuri de tabele de fapte și apoi vom reflecta asupra modului în care acestea nu s-au schimbat în anii care au trecut de când Kimball a actualizat ultima dată Data Warehouse Toolkit. Dacă sunteți familiarizați cu aceste trei categorii de tabele de date, săriți la analiza de la sfârșit; dacă nu, considerați acest articol ca fiind o plimbare concisă prin una dintre componentele de bază ale modelării datelor în stil Kimball.
Două note rapide înainte de a începe: în primul rând, acest articol presupune familiarizarea cu schema în stea. Citiți acest lucru dacă aveți nevoie de o introducere – voi presupune că înțelegeți tabelele de date și tabelele de dimensiuni ca un minim necesar. În al doilea rând, voi remarca faptul că Kimball recunoaște un al patrulea tip de tabel de date – tabelul de date timespan – dar acesta este utilizat doar în situații speciale. Îl vom lăsa în afara discuției noastre de aici.
Tabele de date de tranzacție
Tabele de date de tranzacție sunt ușor de înțeles: un client sau un proces de afaceri face un anumit lucru; doriți să capturați apariția acelui lucru și, astfel, înregistrați o tranzacție în depozitul de date și sunteți gata.
Acest lucru este cel mai bine ilustrat cu un exemplu simplu. Să ne imaginăm că administrați un magazin de proximitate și aveți un sistem electronic de puncte de vânzare (POS) care înregistrează fiecare vânzare pe care o faceți.
Într-o schemă tipică de tip Kimball în formă de stea, tabelul de fapte care se află în centrul schemei dvs. ar consta în date privind tranzacțiile de comandă. Acestea sunt, în principal, măsuri numerice, cum ar fi totalul comenzii, valoarea articolelor, costul bunurilor vândute, valoarea reducerilor aplicate și așa mai departe.
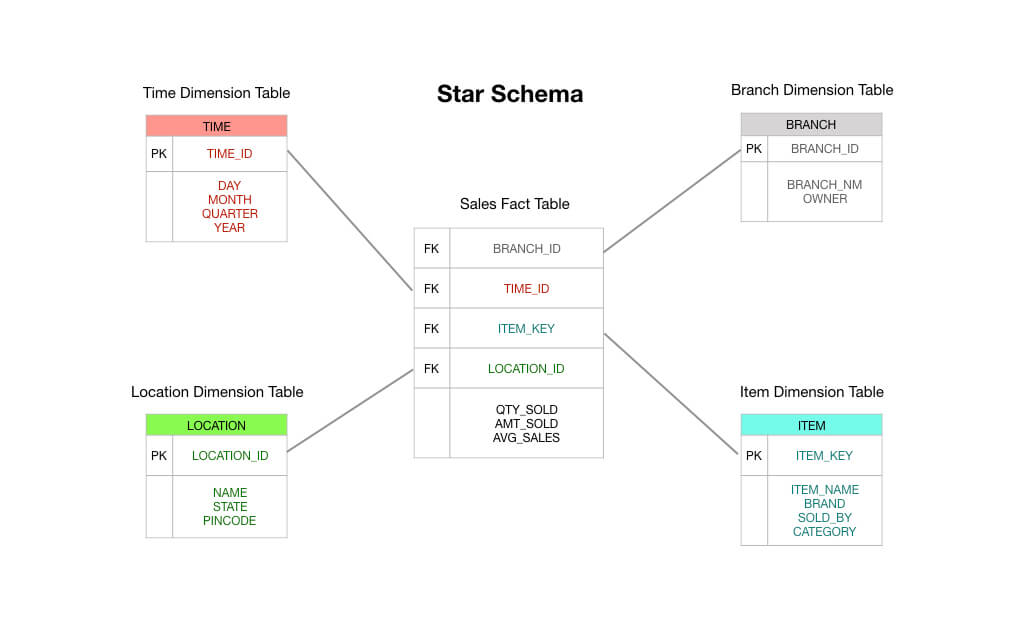
Și, astfel, puteți vedea că o tabelă de date a tranzacțiilor este exact ceea ce scrie pe cutie: primiți o tranzacție, înregistrați tranzacția în tabelul de date, iar aceasta devine baza raportării dumneavoastră. În multe privințe, un tabel de date de tranzacție este tipul implicit de tabel de date la care suntem obișnuiți să ne gândim.
Tabele de date periodice cu instantanee
Tabele de date periodice cu instantanee sunt o extensie logică a tabelelor de date simple de tip vanilie pe care tocmai le-am acoperit mai sus. Un rând dintr-un tabel de fapte cu instantanee periodice captează un anumit tip de date periodice – de exemplu, o instantanee zilnică a indicatorilor financiari, sau poate un rezumat săptămânal al creanțelor sau o numărătoare lunară a numerelor de inventar.
Cu alte cuvinte, „granulația” sau „nivelul de rezoluție” este perioada, nu tranzacția individuală. Rețineți că, dacă nu are loc nicio tranzacție în timpul unei anumite perioade, trebuie introdus un nou rând în tabelul de instantanee periodice, chiar dacă fiecare fapt salvat este nul!
Tabele de instantanee periodice tind să conțină un număr incredibil de mare de câmpuri. Acest lucru se datorează faptului că orice metrică rezonabil de interesantă poate fi băgată în tabelul de perioadă. Vă puteți oarecum imagina un scenariu în care începeți cu vânzări agregate, venituri și costul bunurilor vândute pe o perioadă săptămânală, dar, pe măsură ce trece timpul, conducerea vă cere să adăugați și alte fapte, cum ar fi nivelurile stocurilor, metrici ale conturilor de plătit și alte măsurători interesante.
De ce sunt utile tabelele de instantanee periodice? Ei bine, acest lucru este destul de simplu de imaginat. Dacă doriți să aveți o imagine de ansamblu a liniilor de tendință ale indicatorilor cheie de performanță din afacerea dumneavoastră, vă ajută să faceți interogări în raport cu un tabel de date periodice.
Tabele de instantanee de acumulare
În comparație cu tabelele de instantanee periodice, tabelele de instantanee de acumulare sunt puțin mai greu de explicat. Pentru a înțelege de ce Kimball și colegii săi au venit cu această abordare, este util să înțelegem puțin despre tipurile de întrebări care se puneau în afaceri în anii ’90, adică atunci când a fost scris pentru prima dată Data Warehouse Toolkit.
La sfârșitul anilor ’80, producătorii japonezi au început să-i bată pe omologii lor americani în tot felul de moduri neplăcute, dar neevidente. Principalul dintre acestea a fost concentrarea pe viteza de execuție.
Fabricarea poate fi văzută ca o serie de etape. Luați materia primă la un capăt al fabricii și o transformați în mașini, telefoane și widget-uri la celălalt capăt. Fiecare etapă a procesului de fabricație poate fi măsurată – cât timp este nevoie pentru a transforma blocurile de oțel în pelete de oțel, de exemplu? Cât timp așteaptă acestea în stocul fabricii? Și de acolo, cât timp trebuie să treacă până când peleții sunt transformați în piese de automobile? Cât timp mai durează până când acestea sunt utilizate în automobilele actuale?
La sfârșitul anilor ’70, companiile japoneze au început să realizeze că această viziune de „serie de etape” a creării de valoare ar putea duce la un avantaj competitiv serios dacă ar reduce timpul de întârziere dintre fiecare etapă. Mai concret: dacă puteau reduce numărul de etape necesare pentru a produce fiecare articol și dacă puteau reduce durata de timp petrecută în cadrul fiecărei etape, producătorii japonezi au învățat că puteau să reducă risipa de materiale, să scadă ratele de defecte și să scurteze timpul de livrare și, în același timp, să crească productivitatea lucrătorilor, să crească volumul de producție, să extindă varietatea produselor și să reducă prețurile – toate în același timp.
Până în anii ’90, companiile occidentale s-au prins. O serie de consultanți în management – principalul dintre ei fiind George Stalk Jr. de la Boston Consulting Group – au început să susțină ritmul de execuție ca sursă de avantaj competitiv. Acești consultanți au instruit companiile să înregistreze timpul petrecut la fiecare etapă a procesului de producție. Când sosea o comandă, cât timp aștepta să fie procesată? După ce a fost procesată, cu cât timp înainte ca comanda să fie trimisă la fabrică? La fabrică, cât timp a durat până când produsul a fost finalizat? Și apoi cât timp a așteptat în stoc? Și, în cele din urmă, cât timp a durat până când clientul a primit produsul și a obținut valoare de pe urma acestuia?
Afacerile din anii ’90 au fost astfel presate să măsoare timpii de întârziere de-a lungul întregului proces de livrare a afacerii lor. Ele au fost forțate să facă acest lucru deoarece concurenții japonezi făceau incursiuni în multe industrii dominate anterior de companiile occidentale – în unele cazuri, provocând falimente și perturbând întregi lanțuri de aprovizionare. În acest mediu lucra Kimball.
Tabloul de fapt al instantaneelor cumulative este astfel o metodă de măsurare a vitezei în cadrul procesului de afaceri. Să luăm, de exemplu, acest proces de afaceri, pe care Kimball l-a prezentat în cea de-a doua ediție a The Data Warehouse Toolkit:
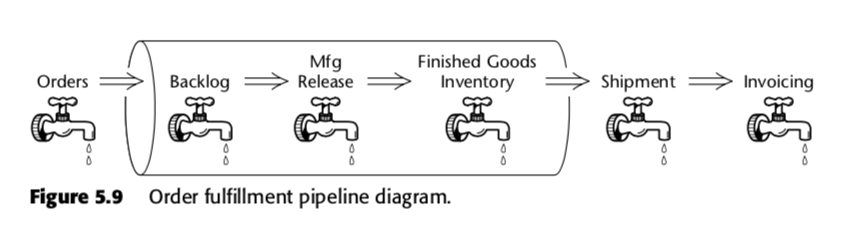
Pentru acest proces, Kimball a propus următorul tabel de instantanee cumulative:
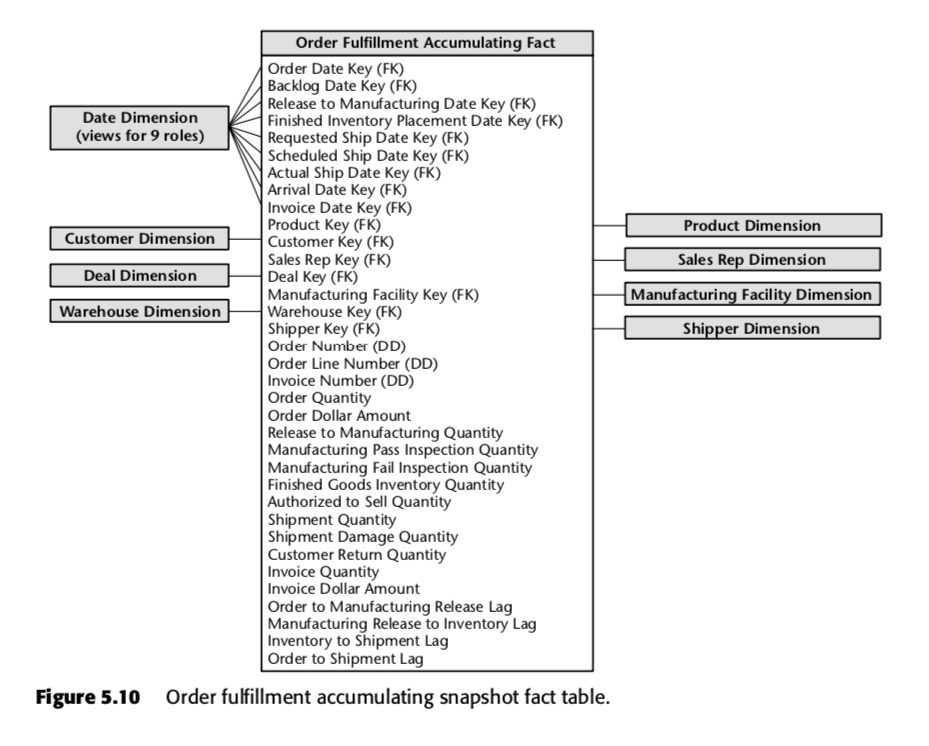
Care rând din acest tabel reprezintă o comandă sau un lot de comenzi. Se preconizează că fiecare dintre aceste rânduri va fi actualizat de mai multe ori pe măsură ce trece prin conducta de îndeplinire a comenzilor. Observați în special numărul mare de câmpuri de date din partea de sus a schemei. Atunci când un rând este creat pentru prima dată în acest tabel, majoritatea acestor date vor fi la început nule, dar în cele din urmă vor fi completate pe măsură ce trece timpul. (Notă: Kimball folosește aici un tabel de dimensiuni de date, în loc de tipul de date SQL încorporat, deoarece acest lucru este The Kimball Way ™ – vă permite să capturați mai multe informații despre date decât doar tipurile naive de date.)
De asemenea, sunt importante și câmpurile din partea de jos a acestei liste. Fiecare dintre ele măsoară un indicator de decalaj – adică diferența dintre două date. Astfel, de exemplu, Order to Manufacturing Release Lag este timpul scurs de la Order Date la Release to Manufacturing Date; Inventory to Shipment Lag este timpul scurs de la Finished Inventory Placement Date la Actual Ship Date, și așa mai departe. Pe măsură ce trece timpul, fiecare dintre aceste date va fi completată de un sistem ERP sau, poate, de către un grunt de introducere a datelor. Timpii de întârziere pentru fiecare comandă în parte ar fi astfel calculați pe măsură ce fiecare câmp este completat.
Vezi cum un astfel de tabel ar fi util unei companii care operează într-un mediu concurențial bazat pe timp. Folosind un singur tabel, conducerea ar putea vedea dacă timpii de decalaj din producția sa cresc sau scad în timp. Aceștia pot utiliza astfel de informații de afaceri pentru a determina care etape sunt cele mai problematice în procesul lor de producție. Și pot lua măsuri cu privire la bucățile care îi îngrijorează cel mai mult.
Nota laterală: aceste idei au fost adaptate la lumea software sub terminologia „lean”; pentru mai multe informații despre măsurarea producției în cadrul companiilor de tehnologie, consultați postările noastre despre cartea Accelerate aici și aici.
De ce nu s-au schimbat?
Este o dovadă a lui Kimball și a colegilor săi că cele trei tipuri de tabele de date nu s-au schimbat material de când au fost articulate pentru prima dată în 1996.
De ce se întâmplă acest lucru? Răspunsul, cred eu, se află în faptul că schema stea captează ceva fundamental despre afaceri. Dacă vă modelați datele pentru a se potrivi cu procesele dvs. de afaceri, veți capta datele de fapt într-unul din cele trei moduri: prin intermediul tranzacțiilor, cu perioade colaționate și – dacă afacerea dvs. este suficient de pricepută în ceea ce privește concurența bazată pe timp – prin măsurarea timpilor de decalaj între fiecare etapă a sistemului dvs. de livrare a valorii.
Kimball însuși spune ceva similar. Într-o postare pe blog din 2015, el scrie:
În loc să ne agățăm de argumente religioase despre modelele logice versus modelele fizice, ar trebui să recunoaștem pur și simplu că un model dimensional este de fapt o interfață de programare a aplicațiilor (API) a depozitului de date. Puterea acestei API constă în interfața consistentă și uniformă văzută de toți observatorii, atât de utilizatori, cât și de aplicațiile BI. Vedem că nu contează unde sunt stocați biții sau cum sunt livrați atunci când este lansată o cerere API.
Schema stea este testată în timp. Acest lucru este evident.
În aceeași postare, Kimball continuă apoi să argumenteze că nici măcar inovațiile recente, cum ar fi depozitul de date columnar, nu au schimbat acest fapt; majoritatea companiilor cu care vorbește încă ajung la finalul zilei cu o structură de model dimensional.
Dar lucrurile s-au schimbat. Împrăștiate de-a lungul setului de instrumente Data Warehouse Toolkit sunt mențiuni pitorești despre „limitarea numărului de fapte pe tabel” și „planificarea strategiei de modelare a datelor cu toate părțile interesate din domeniu prezente la întâlnire”. Acestea nu reflectă ceea ce vedem în practică în compania noastră și în departamentele de date ale clienților noștri.
Cea mai mare schimbare este viteza cu care tehnologiile actuale ne permit să trecem de la ‘tabel naiv de fapte’ la ‘model dimensional de tip Kimball’ – ceea ce ne permite să sărim peste practica modelării inițiale și, în schimb, să optăm pentru a modela atât de puțin cât este necesar. Această practică este permisă de o serie de schimbări tehnologice pe care le-am mai discutat pe acest blog (mai ales în postarea noastră despre The Rise and Fall of the OLAP Cube), dar implicațiile practice asupra utilizării noastre a tabelelor de fapte sunt următoarele:
- Tabele de fapte tranzacționale – suntem perfect fericiți să avem tabele de fapte mari, cu zeci, dacă nu sute de fapte pe rând! Aceasta nu înseamnă că aceasta este o situație ideală, ci doar că este un compromis foarte acceptabil. Spre deosebire de vremea lui Kimball, talentul datelor este astăzi prohibitiv de scump; timpul de stocare și de calcul este ieftin. Așadar, suntem perfect de acord să lăsăm anumite tabele de date așa cum sunt – de fapt, avem câteva tabele cu peste 100 de câmpuri în ele, introduse direct din sistemele noastre sursă! Poziția noastră filosofică este următoarea: dacă avem cerințe complexe de raportare, atunci merită să ne luăm timp și să modelăm datele în mod corespunzător. Dar dacă rapoartele de care avem nevoie sunt simple, atunci profităm de puterea de calcul pe care o avem la dispoziție și lăsăm tabelele de date așa cum sunt.
- Tabele de date cu instantanee periodice – este surprinzător cât de mult reușim să evităm să facem acest lucru. Deoarece depozitele de date columnare MPP moderne sunt atât de puternice, nu creăm tabele de date periodice de tip snapshot fact tables pentru rapoartele care nu sunt utilizate atât de regulat. Timpul de execuție a interogării și costurile suplimentare necesare pentru a genera rapoarte din datele de tranzacție brute sunt perfect acceptabile, mai ales dacă știm că raportul este necesar doar o dată pe săptămână sau cam așa ceva (sau este pus la dispoziție pentru explorare periodică). Pentru alte seturi de date, generăm periodic tabele de instantanee, conform recomandărilor inițiale ale lui Kimball.
- Acumularea tabelelor de instantanee – Acest lucru este aproape neschimbat de pe vremea lui Kimball. Dar – așa cum spune însuși Kimball – tabelele snapshot de acumulare sunt rare în practică. Așa că nu ne gândim la acest lucru atât de mult pe cât s-ar putea gândi o companie mai orientată spre timp.
Este important de menționat aici că noi credem că modelarea este importantă. Diferența este că practica noastră de analiză a datelor ne permite să ne revizuim deciziile de modelare în orice moment în viitor. Cum facem acest lucru? Ei bine, încărcăm datele noastre tranzacționale brute în depozitul nostru de date înainte de a le transforma. Acest lucru este cunoscut sub numele de „ELT”, spre deosebire de „ETL”. Deoarece efectuăm toate transformările noastre în cadrul depozitului de date, folosind un strat de modelare a datelor, suntem capabili să ne revizuim alegerile și să remodelăm datele noastre dacă este nevoie.
Aceasta ne permite să ne concentrăm mai întâi pe furnizarea de valoare de afaceri. Menține munca de modelare a datelor la un nivel scăzut.
.