Ralph Kimballs dimensionella datamodellering definierar tre typer av faktatabeller. Dessa är:
- Transaction fact tables.
- Periodic snapshot tables, och
- Accumulating snapshot tables.
I det här inlägget kommer vi att gå igenom var och en av de här typerna av faktatabeller och sedan reflektera över hur de inte har förändrats under de år som gått sedan Kimball senast uppdaterade Data Warehouse Toolkit. Om du är bekant med dessa tre kategorier av faktatabeller kan du hoppa fram till analysen i slutet; om du inte är bekant kan du betrakta det här som en kortfattad genomgång av en av de grundläggande komponenterna i Kimballs datamodellering.
Två snabba anteckningar innan vi börjar: för det första förutsätter det här inlägget att du är bekant med stjärnschemat. Läs det här om du behöver en grundkurs – jag utgår från att du åtminstone förstår fakta- och dimensionstabeller. För det andra vill jag notera att Kimball erkänner en fjärde typ av faktatabell – timespan fact table – men den används endast under speciella omständigheter. Vi lämnar den utanför vår diskussion här.
Transaktionsfaktatabeller
Transaktionsfaktatabeller är lätta att förstå: en kund eller en affärsprocess gör en sak; du vill fånga upp förekomsten av den saken, och därför registrerar du en transaktion i ditt datalager, och så är du klar.
Detta illustreras bäst med ett enkelt exempel. Låt oss föreställa oss att du driver en närbutik och att du har ett elektroniskt kassasystem som registrerar varje försäljning som du gör.
I ett typiskt Kimball-stjärnskema skulle den faktatabell som står i centrum för ditt schema bestå av uppgifter om beställningstransaktioner. Det rör sig främst om numeriska mått som beställningssumma, belopp för enskilda artiklar, kostnad för sålda varor, tillämpade rabatter och så vidare.
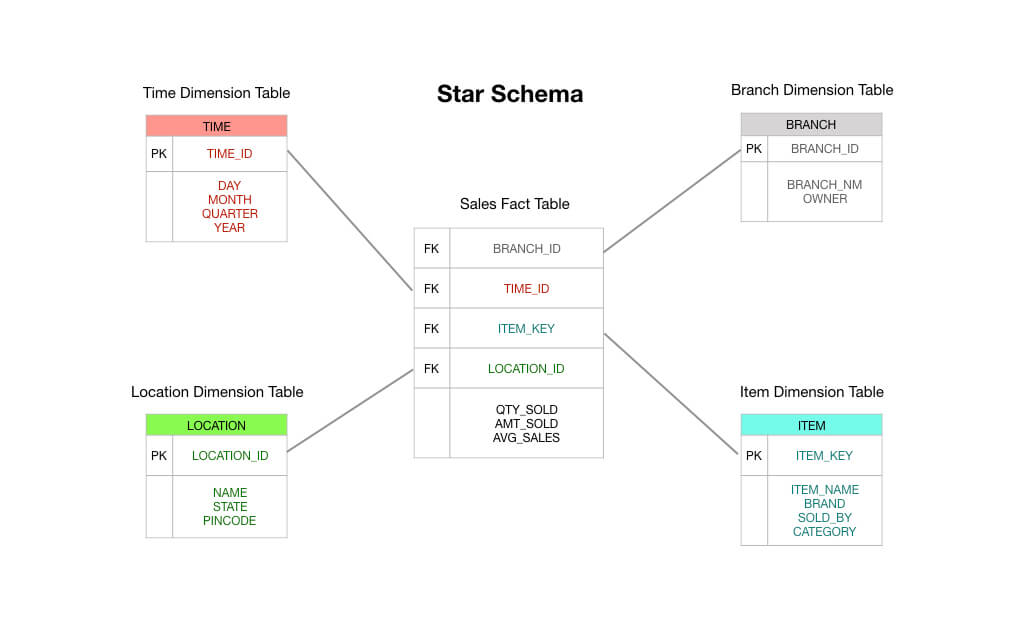
Så du kan se att en transaktionsfaktatabell är precis som det står på burken: du tar emot en transaktion, du registrerar transaktionen i din faktatabell, och detta blir grunden för din rapportering. På många sätt är en transaktionsfaktatabell den standardtyp av faktatabell som vi är vana att tänka på.
Periodiska ögonblicksbildstabeller
Periodiska ögonblicksbildsfaktatabeller är en logisk förlängning av de vanliga vanilla-faktatabellerna som vi just har behandlat ovan. En rad i en periodisk snapshot-faktabell fångar någon typ av periodiska data – till exempel en daglig ögonblicksbild av finansiella mätvärden, eller kanske en veckosammanfattning av kundfordringar, eller en månatlig sammanställning av lagersiffror.
Med andra ord är ”kornet” eller ”upplösningsnivån” perioden, inte den enskilda transaktionen. Observera att om inga transaktioner sker under en viss period måste en ny rad sättas in i den periodiska ögonblicksbildstabellen, även om alla fakta som sparas är noll!
Periodiska ögonblicksbildstabeller tenderar att innehålla ett otroligt stort antal fält. Detta beror på att alla någorlunda intressanta mått kan läggas in i periodtabellen. Du kan föreställa dig ett scenario där du börjar med aggregerad försäljning, intäkter och kostnad för sålda varor för en veckoperiod, men med tiden ber ledningen dig att lägga till andra fakta som lagernivåer, betalningsmottagningar och andra intressanta mätningar.
Varför är periodiska ögonblicksbildstabeller användbara? Det är ganska enkelt att föreställa sig. Om du vill ha en överblick över trendlinjerna i nyckeltal i ditt företag hjälper det att fråga mot en periodisk faktatabell.
Ackumulerande ögonblicksbildstabeller
Till skillnad från periodiska ögonblicksbildstabeller är ackumulerande ögonblicksbildstabeller lite svårare att förklara. För att förstå varför Kimball och hans kollegor kom på detta tillvägagångssätt hjälper det att förstå lite om den typ av frågor som ställdes till företagen på 90-talet, vilket var när Data Warehouse Toolkit först skrevs.
I slutet av 80-talet började japanska tillverkare att slå sina amerikanska motsvarigheter på alla möjliga obehagliga men icke uppenbara sätt. Det viktigaste av dessa var ett fokus på utförandehastighet.
Förtillverkning kan ses som en serie steg. Man tar råmaterial i ena änden av fabriken och förvandlar det till bilar, telefoner och prylar i den andra änden. Varje steg i tillverkningsprocessen kan mätas – hur lång tid tar det till exempel att förvandla stålblock till stålpellets? Hur länge väntar de i fabrikens lager? Och hur lång tid tar det innan pelletsen tillverkas till bildelar? Hur lång tid tar det innan de används i verkliga bilar?
I slutet av 70-talet började japanska företag inse att denna syn på värdeskapande i flera steg kunde leda till en allvarlig konkurrensfördel om de minskade fördröjningstiden mellan varje steg. Mer konkret: om de kunde minska antalet steg som krävs för att tillverka varje produkt och om de kunde minska tiden inom varje steg, lärde sig de japanska tillverkarna att de kunde minska materialspillet, sänka antalet defekter och korta leveranstiderna, samtidigt som de kunde öka arbetstagarnas produktivitet, öka tillverkningsvolymen, utöka produktutbudet och sänka priserna – allt på en och samma gång.
När 90-talet kom hade de västerländska företagen fattat detta. Ett antal företagskonsulter – främst George Stalk Jr från Boston Consulting Group – började förespråka utförandehastighet som en källa till konkurrensfördelar. Dessa konsulter instruerade företagen att registrera den tid som spenderades i varje steg i produktionsprocessen. När en order kom in, hur länge väntade den på att behandlas? Hur lång tid tog det innan beställningen skickades till fabriken? Hur lång tid tog det i fabriken innan produkten var färdig? Och hur länge väntade den sedan i lagret? Och slutligen, hur lång tid tog det innan kunden fick produkten och fick ett värde av den?
Företagen på 90-talet pressades alltså att mäta fördröjningstider i hela leveransprocessen. De var tvungna att göra detta eftersom japanska konkurrenter gjorde intrång i många branscher som tidigare dominerats av västerländska företag – i vissa fall orsakade de konkurser och störde hela leveranskedjor. Det var i denna miljö som Kimball arbetade.
Den ackumulerande snapshot-faktabellen är alltså en metod för att mäta hastigheten inom affärsprocessen. Ta till exempel den här affärspipeline som Kimball presenterade i den andra upplagan av The Data Warehouse Toolkit:
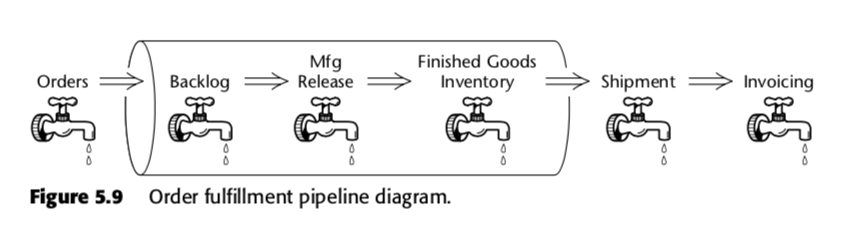
För den processen föreslog Kimball följande ackumulerande ögonblicksbildstabell:
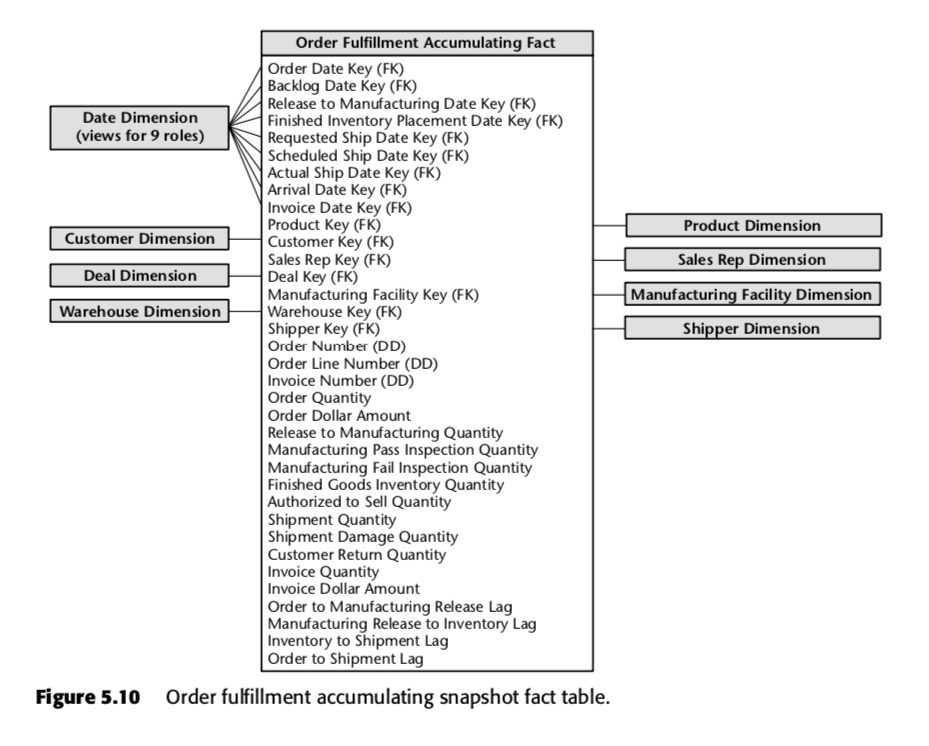
Varje rad i den här tabellen representerar en beställning eller ett parti av beställningar. Var och en av dessa rader förväntas uppdateras flera gånger när de går igenom orderuppfyllandet. Lägg särskilt märke till det stora antalet datumfält högst upp i schemat. När en rad först skapas i den här tabellen kommer majoriteten av dessa datum att börja som nollor, men kommer så småningom att fyllas på med tiden. (Observera: Kimball använder en datumdimensionstabell här, i stället för den inbyggda SQL-datatypen datum, eftersom detta är The Kimball Way ™ – det gör det möjligt att fånga in mer information om datum än bara de naiva datumtyperna.)
Också viktiga är fälten längst ner i den här listan. Var och en av dem mäter en fördröjningsindikator – det vill säga skillnaden mellan två datum. Så till exempel Order to Manufacturing Release Lag är tiden från Order Date till Release to Manufacturing Date; Inventory to Shipment Lag är tiden från Finished Inventory Placement Date till Actual Ship Date, och så vidare. När tiden går kommer vart och ett av dessa datum att fyllas i av ett ERP-system eller kanske av en datainmatare. Fördröjningstiderna för varje enskild order skulle alltså beräknas allteftersom varje fält fylls i.
Du kan se hur en sådan tabell skulle vara användbar för ett företag som verkar i en tidsbaserad konkurrensmiljö. Med hjälp av en enda tabell skulle ledningen kunna se om fördröjningstiderna i dess produktion ökar eller minskar med tiden. De kan använda sådan affärsinformation för att avgöra vilka steg som är de mest problematiska i deras produktionsprocess. Och de kan vidta åtgärder mot de bitar som oroar dem mest.
Notis vid sidan av: Dessa idéer har anpassats till programvaruvärlden under terminologin ”lean”; för mer information om att mäta produktionen inom teknikföretag, se våra inlägg om boken Accelerate här och här.
Varför har de inte förändrats?
Det är ett bevis på Kimball och hans kollegor att de tre typerna av faktatabeller inte har förändrats väsentligt sedan de först artikulerades 1996.
Varför är detta fallet? Svaret tror jag ligger i det faktum att stjärnschemat fångar något grundläggande om affärsverksamhet. Om du modellerar dina data för att matcha dina affärsprocesser kommer du i stort sett att fånga faktauppgifter på ett av tre sätt: via transaktioner, med sammanställda perioder och – om ditt företag är tillräckligt kunnigt när det gäller tidsbaserad konkurrens – genom att mäta fördröjningstiderna mellan varje steg i ditt system för värdeskapande.
Kimball själv säger något liknande. I ett blogginlägg från 2015 skriver han:
Istället för att fastna i religiösa argument om logiska kontra fysiska modeller bör vi helt enkelt inse att en dimensionell modell i själva verket är ett programgränssnitt (API) för datalager. Styrkan i detta API ligger i det konsekventa och enhetliga gränssnittet som ses av alla observatörer, både användare och BI-applikationer. Vi ser att det inte spelar någon roll var bitarna lagras eller hur de levereras när en API-förfrågan inleds.
Stjärnschemat är beprövat. Detta är uppenbart.
I samma inlägg fortsätter Kimball att hävda att inte ens de senaste innovationerna, som kolumnformade datalager, har förändrat detta faktum; majoriteten av de företag som han pratar med slutar fortfarande med en struktur med en dimensionell modell i slutändan.
Men saker och ting har förändrats. I Data Warehouse Toolkit finns det många pittoreska omnämnanden om att ”begränsa antalet fakta per tabell” och att ”planera strategin för datamodellering med alla intressenter inom domänen närvarande vid mötet”. Detta återspeglar inte vad vi ser i praktiken på vårt företag och på våra kunders dataavdelningar.
Den största förändringen är den snabbhet med vilken den nuvarande tekniken gör det möjligt för oss att övergå från ”naiv faktatabell” till ”dimensionell modell i Kimball-stil” – vilket gör det möjligt för oss att hoppa över modelleringen i förväg och i stället välja att modellera så lite som vi behöver. Denna praxis möjliggörs av ett antal tekniska förändringar som vi har diskuterat på den här bloggen tidigare (framför allt i vårt inlägg om The Rise and Fall of the OLAP Cube), men de praktiska konsekvenserna för vår användning av faktatabeller är följande:
- Transaktionsfaktatabeller – vi är helt nöjda med att ha feta faktatabeller, med dussintals, om inte hundratals fakta per rad! Därmed inte sagt att detta är en idealisk situation, bara att det är en mycket godtagbar kompromiss. Till skillnad från på Kimballs tid är datakompetens i dag oöverkomligt dyrt; lagrings- och beräkningstid är billig. Därför är det helt okej för oss att låta vissa faktatabeller vara som de är – i själva verket har vi flera tabeller med mer än 100 fält i dem, som vi har fått in direkt från våra källsystem! Vår filosofi är följande: Om vi har komplexa rapporteringskrav är det värt att ta sig tid och modellera data på rätt sätt. Men om rapporterna vi behöver är enkla så drar vi nytta av den beräkningskraft som finns tillgänglig för oss och låter faktatabellerna vara som de är.
- Periodiska ögonblicksbilder av faktatabeller – det är förvånande hur mycket vi kan undvika att göra detta. Eftersom moderna MPP-kolumnariska datalager är så kraftfulla skapar vi inte periodiska snapshot-faktatabeller för rapporter som inte används lika regelbundet. Den tid det tar att utföra frågor och den extra kostnad det innebär att generera rapporter från råa transaktionsdata är helt acceptabel, särskilt om vi vet att rapporten bara behövs en gång i veckan eller så (eller görs tillgänglig för periodisk utforskning). För andra datamängder genererar vi periodiska ögonblicksbildstabeller enligt Kimballs ursprungliga rekommendationer.
- Ackumulering av ögonblicksbildstabeller – Detta är nästan oförändrat sedan Kimballs tid. Men – som Kimball själv säger – ackumulerande snapshottabeller är sällsynta i praktiken. Så vi ägnar inte detta lika mycket uppmärksamhet som ett mer tidsstyrt företag kanske skulle göra.
Det är viktigt att notera här att vi anser att modellering är viktigt. Skillnaden är att vår praxis för dataanalys gör att vi kan ompröva våra modelleringsbeslut när som helst i framtiden. Hur gör vi detta? Jo, vi laddar in våra råa transaktionsdata i vårt datalager innan vi transformerar dem. Detta kallas ”ELT” i motsats till ”ETL”. Eftersom vi gör alla våra omvandlingar i datalagret med hjälp av ett datamodelleringsskikt, kan vi se över våra val och omforma våra data om behovet uppstår.
Detta gör att vi kan fokusera på att leverera affärsnytta först. Det håller datamodelleringsarbetet nere.