El modelado dimensional de datos de Ralph Kimball define tres tipos de tablas de hechos. Estas son:
- Tablas de hechos de transacción.
- Tablas de instantáneas periódicas, y
- Tablas de instantáneas de acumulación.
En este post, vamos a repasar cada uno de estos tipos de tablas de hechos, y luego reflexionar sobre cómo no han cambiado en los años transcurridos desde que Kimball actualizó por última vez el Data Warehouse Toolkit. Si está familiarizado con estas tres categorías de tablas de hechos, pase al análisis del final; si no lo está, considere esto como un paseo conciso a través de uno de los componentes básicos del modelado de datos al estilo Kimball.
Dos notas rápidas antes de empezar: en primer lugar, este artículo asume la familiaridad con el esquema de estrella. Lea esto si necesita una introducción – voy a asumir que usted entiende las tablas de hechos y dimensiones como mínimo. En segundo lugar, observaré que Kimball reconoce un cuarto tipo de tabla de hechos, la tabla de hechos de duración, pero sólo se utiliza en circunstancias especiales. Lo dejaremos fuera de nuestra discusión aquí.
Tablas de hechos de transacciones
Las tablas de hechos de transacciones son fáciles de entender: un cliente o un proceso de negocio hace algo; usted quiere capturar la ocurrencia de esa cosa, y entonces registra una transacción en su almacén de datos y ya está listo.
Esto se ilustra mejor con un ejemplo simple. Imaginemos que diriges una tienda de conveniencia y que tienes un sistema de punto de venta electrónico que registra cada venta que realizas.
En un típico esquema de estrella estilo Kimball, la tabla de hechos que está en el centro de tu esquema consistiría en datos de transacciones de pedidos. Se trata principalmente de medidas numéricas como el total del pedido, los importes de las partidas, el coste de las mercancías vendidas, los importes de los descuentos aplicados, etc.
Así que puede ver que una tabla de hechos de transacciones es exactamente lo que dice en la lata: usted recibe una transacción, registra la transacción en su tabla de hechos y ésta se convierte en la base de sus informes. En muchos sentidos, una tabla de hechos de transacciones es el tipo de tabla de hechos por defecto en el que estamos acostumbrados a pensar.
Tablas de instantáneas periódicas
Las tablas de hechos de instantáneas periódicas son una extensión lógica de las tablas de hechos simples que acabamos de cubrir. Una fila en una tabla de hechos de instantáneas periódicas captura algún tipo de datos periódicos – por ejemplo, una instantánea diaria de las métricas financieras, o tal vez un resumen semanal de las cuentas por cobrar, o un recuento mensual de los números de inventario.
En otras palabras, el «grano» o «nivel de resolución» es el período, no la transacción individual. Tenga en cuenta que si no hay transacciones durante un período determinado, se debe insertar una nueva fila en la tabla de instantáneas periódicas, incluso si cada hecho que se guarda es un nulo.
Las tablas de instantáneas periódicas tienden a contener un número increíblemente grande de campos. Esto se debe a que cualquier métrica razonablemente interesante puede ser metida en la tabla de períodos. Usted puede imaginar un escenario donde usted comienza con las ventas agregadas, los ingresos y el costo de los bienes vendidos en un período semanal, pero a medida que pasa el tiempo, la gestión le pide que agregue otros hechos como los niveles de inventario, las métricas de cuentas por pagar, y otras medidas interesantes.
¿Por qué son útiles las tablas periódicas de instantáneas? Bueno, esto es bastante sencillo de imaginar. Si quiere tener una visión general de las líneas de tendencia en los indicadores clave de rendimiento en su negocio, le ayuda a consultar contra una tabla de hechos periódicos.
Tablas instantáneas de acumulación
A diferencia de las tablas instantáneas periódicas, las tablas instantáneas de acumulación son un poco más difíciles de explicar. Para entender por qué Kimball y sus compañeros idearon este enfoque, ayuda a comprender un poco el tipo de preguntas que se hacían a las empresas en los años 90, que fue cuando se escribió por primera vez el Data Warehouse Toolkit.
A finales de los años 80, los fabricantes japoneses empezaron a superar a sus homólogos estadounidenses en todo tipo de aspectos desagradables pero no evidentes. El principal de ellos era el enfoque en la velocidad de ejecución.
La fabricación puede verse como una serie de pasos. Se toma la materia prima en un extremo de la fábrica y se convierte en coches, teléfonos y aparatos en el otro extremo. Cada paso del proceso de fabricación puede medirse: ¿cuánto tiempo se tarda en convertir los bloques de acero en pellets de acero, por ejemplo? ¿Cuánto tiempo esperan en el inventario de la fábrica? Y a partir de ahí, ¿cuánto tiempo pasa antes de que los gránulos se conviertan en piezas de automóvil? ¿Cuánto tiempo pasa antes de que se utilicen en los automóviles reales?
A finales de los años 70, las empresas japonesas empezaron a darse cuenta de que esta visión de la creación de valor en «serie de pasos» podía suponer una gran ventaja competitiva si reducían el tiempo de espera entre cada paso. Más concretamente: si podían reducir el número de pasos necesarios para producir cada artículo y si podían reducir el tiempo empleado en cada paso, los fabricantes japoneses aprendieron que podían reducir el desperdicio de material, disminuir las tasas de defectos y recortar el tiempo de entrega, al tiempo que aumentaban la productividad de los trabajadores, aumentaban el volumen de fabricación, ampliaban la variedad de productos y reducían los precios, todo ello al mismo tiempo.
Para cuando llegaron los años 90, las empresas occidentales se habían dado cuenta. Una serie de consultores de gestión -el principal de ellos, George Stalk Jr, del Boston Consulting Group- empezaron a defender el ritmo de ejecución como fuente de ventaja competitiva. Estos consultores instruyeron a las empresas para que registraran el tiempo empleado en cada paso del proceso de producción. Cuando llegaba un pedido, ¿cuánto tiempo esperaba para ser procesado? Una vez procesado, ¿cuánto tardaba en enviarse el pedido a la fábrica? En la fábrica, ¿cuánto tiempo transcurrió hasta que se completó el producto? Y luego, ¿cuánto tiempo esperó en el inventario? Y, por último, ¿cuánto tiempo pasó antes de que el cliente recibiera el producto y obtuviera valor de él?
Las empresas de los años 90 se vieron así presionadas para medir los tiempos de espera a lo largo de todo el proceso de entrega de su negocio. Se vieron obligadas a hacerlo porque los competidores japoneses estaban haciendo incursiones en muchas industrias anteriormente dominadas por las empresas occidentales, en algunos casos, provocando quiebras y perturbando cadenas de suministro enteras. Fue en este entorno en el que trabajó Kimball.
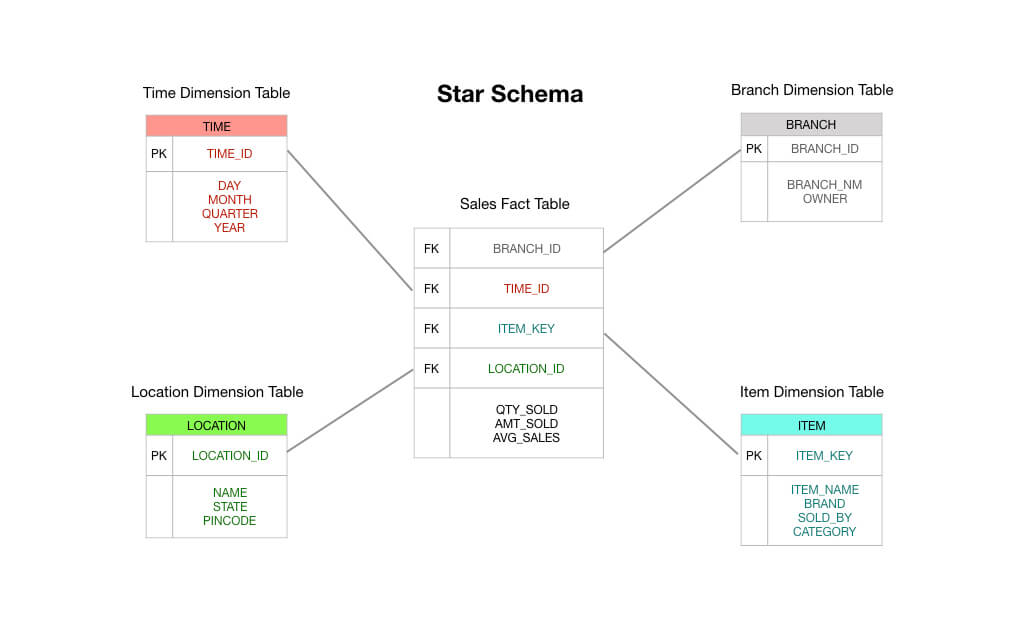
La tabla de hechos de instantáneas acumuladas es, por tanto, un método para medir la velocidad dentro del proceso empresarial. Tomemos, por ejemplo, esta cadena de negocio, que Kimball presentó en la segunda edición de The Data Warehouse Toolkit:
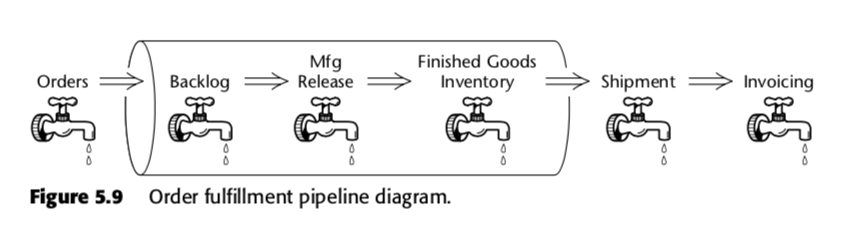
Para ese proceso, Kimball propuso la siguiente tabla de instantáneas acumuladas:
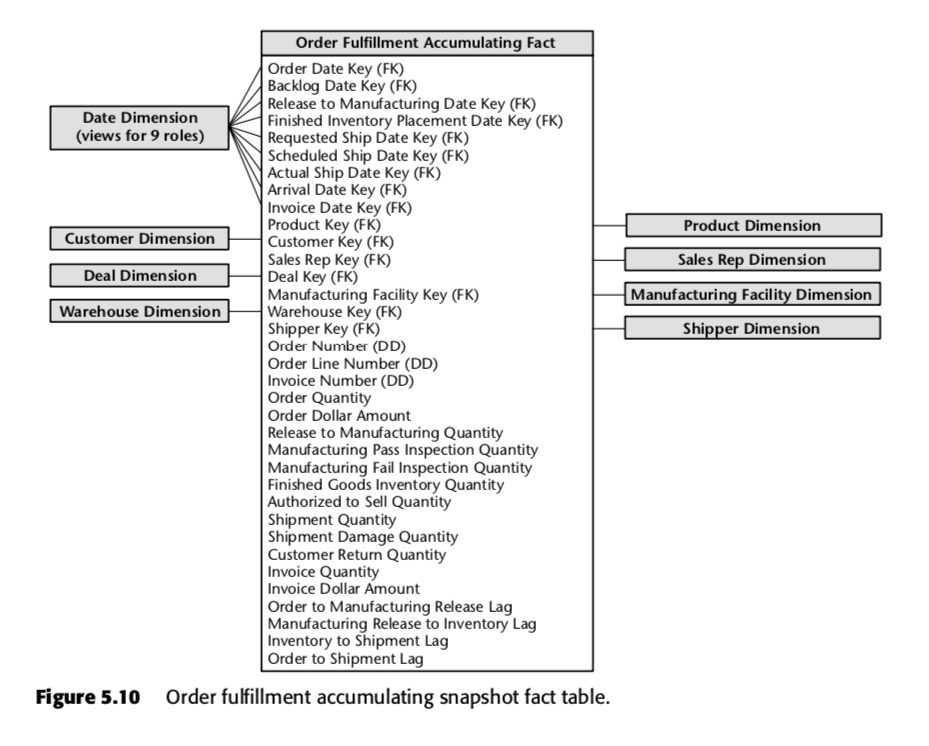
Cada fila de esta tabla representa un pedido o un lote de pedidos. Se espera que cada una de estas filas se actualice varias veces a medida que avanza en el proceso de tramitación de pedidos. Observe en particular el gran número de campos de fecha en la parte superior del esquema. Cuando se crea por primera vez una fila en esta tabla, la mayoría de estas fechas empezarán siendo nulas, pero se irán rellenando a medida que pase el tiempo. (Nota: Kimball utiliza una tabla de dimensión de fecha aquí, en lugar del tipo de datos de fecha incorporado en SQL, porque al hacerlo es The Kimball Way ™ – le permite capturar más información sobre las fechas que sólo los tipos de fecha ingenuos.)
También son importantes los campos en la parte inferior de esa lista. Cada uno de ellos mide un indicador de retraso – es decir, la diferencia entre dos fechas. Así, por ejemplo, Order to Manufacturing Release Lag es el tiempo transcurrido desde Order Date hasta Release to Manufacturing Date; Inventory to Shipment Lag es el tiempo transcurrido desde Finished Inventory Placement Date hasta Actual Ship Date, y así sucesivamente. A medida que pasa el tiempo, cada una de estas fechas será completada por un sistema ERP o quizás por un gruñón de entrada de datos. Los tiempos de retraso para cada orden en particular se calculan a medida que se rellena cada campo.
Se puede ver cómo una tabla de este tipo sería útil para una empresa que opera en un entorno competitivo basado en el tiempo. Utilizando una sola tabla, la dirección sería capaz de ver si los tiempos de retraso en su producción están aumentando o disminuyendo con el tiempo. Pueden utilizar esta inteligencia empresarial para determinar qué pasos son los más problemáticos en su proceso de producción. Y pueden tomar medidas en las partes que más les preocupan.
Nota al margen: estas ideas se han adaptado al mundo del software bajo la terminología de ‘lean’; para más información sobre la medición de la producción en las empresas tecnológicas, consulta nuestros posts sobre el libro Accelerate aquí y aquí.
¿Por qué no han cambiado?
Es un testimonio para Kimball y sus compañeros que los tres tipos de tablas de datos no han cambiado materialmente desde que se articularon por primera vez en 1996.
¿Por qué es así? La respuesta, creo, radica en el hecho de que el esquema en estrella capta algo fundamental sobre los negocios. Si modelas tus datos para que coincidan con tus procesos de negocio, prácticamente vas a capturar los datos de los hechos de una de las tres maneras siguientes: a través de las transacciones, con períodos cotejados y -si tu negocio es lo suficientemente inteligente en cuanto a la competencia basada en el tiempo- midiendo los tiempos de retraso entre cada paso de tu sistema de entrega de valor.
El propio Kimball dice algo similar. En una entrada de blog de 2015, escribe:
En lugar de obsesionarse con argumentos religiosos sobre los modelos lógicos frente a los físicos, deberíamos reconocer simplemente que un modelo dimensional es en realidad una interfaz de programación de aplicaciones (API) de almacén de datos. El poder de esta API reside en la interfaz consistente y uniforme que ven todos los observadores, tanto los usuarios como las aplicaciones de BI. Vemos que no importa dónde se almacenan los bits o cómo se entregan cuando se lanza una solicitud de API.
El esquema de estrella está probado en el tiempo. Esto es obvio.
En el mismo post, Kimball pasa a argumentar que incluso las innovaciones recientes como el almacén de datos en columnas no han cambiado este hecho; la mayoría de las empresas con las que habla todavía terminan con una estructura de modelo dimensional al final del día.
Pero las cosas han cambiado. En todo el Data Warehouse Toolkit hay menciones pintorescas de «limitar el número de hechos por tabla», y «planificar su estrategia de modelado de datos con todos los interesados del dominio presentes en la reunión». Esto no refleja lo que vemos en la práctica en nuestra empresa y en los departamentos de datos de nuestros clientes.
El mayor cambio es la velocidad a la que las tecnologías actuales nos permiten pasar de la «tabla de hechos ingenua» al «modelo dimensional estilo Kimball», lo que nos permite omitir la práctica del modelado inicial y optar por modelar lo mínimo necesario. Esta práctica es posible gracias a una serie de cambios tecnológicos de los que ya hemos hablado en este blog (sobre todo, en nuestro post sobre El auge y la caída del cubo OLAP), pero las implicaciones prácticas en nuestro uso de las tablas de hechos son las siguientes:
- Tablas de hechos de transacción – ¡nosotros estamos perfectamente contentos de tener tablas de hechos gordas, con docenas si no cientos de hechos por fila! Esto no quiere decir que sea una situación ideal, sino que es un compromiso muy aceptable. A diferencia de la época de Kimball, hoy en día el talento de los datos es prohibitivo; el almacenamiento y el tiempo de computación son baratos. Por lo tanto, no tenemos ningún problema en dejar algunas tablas de datos tal y como están; de hecho, tenemos varias con más de 100 campos, que proceden directamente de nuestros sistemas de origen. Nuestra postura filosófica es la siguiente: si tenemos necesidades complejas de elaboración de informes, vale la pena tomarse el tiempo y modelar los datos adecuadamente. Pero si los informes que necesitamos son sencillos, entonces aprovechamos la potencia de cálculo de que disponemos y dejamos las tablas de hechos tal y como están.
- Tablas de hechos de instantáneas periódicas – es sorprendente lo mucho que podemos evitar hacer esto. Dado que los almacenes de datos columnares MPP modernos son tan potentes, no creamos tablas de hechos de instantáneas periódicas para los informes que no se utilizan con tanta regularidad. El tiempo de ejecución de la consulta y el coste adicional que supone generar informes a partir de datos de transacciones en bruto es perfectamente aceptable, especialmente si sabemos que el informe sólo se necesita una vez a la semana aproximadamente (o se pone a disposición para su exploración periódica). Para otros conjuntos de datos, generamos tablas de instantáneas periódicas según las recomendaciones originales de Kimball.
- Acumulación de tablas de instantáneas – Esto no ha cambiado prácticamente desde la época de Kimball. Pero -como dice el propio Kimball- acumular tablas de instantáneas es poco frecuente en la práctica. Así que no pensamos tanto en esto como podría hacerlo una empresa más orientada al tiempo.
Es importante señalar aquí que sí creemos que el modelado es importante. La diferencia es que nuestra práctica de análisis de datos nos permite revisar nuestras decisiones de modelado en cualquier momento en el futuro. ¿Cómo lo hacemos? Bueno, cargamos nuestros datos transaccionales en bruto en nuestro almacén de datos antes de transformarlos. Esto se conoce como «ELT» en contraposición a «ETL». Dado que realizamos todas nuestras transformaciones dentro del almacén de datos, utilizando una capa de modelado de datos, podemos revisar nuestras elecciones y remodelar nuestros datos si surge la necesidad.
Esto nos permite centrarnos en ofrecer primero el valor empresarial. Mantiene el trabajo de modelado de datos bajo.