Ralph Kimball v rámci dimenzionálního modelování dat definuje tři typy tabulek faktů. Jsou to:
- Transakční tabulky faktů.
- Tabulky periodických snímků a
- Akumulační tabulky snímků.
V tomto příspěvku si projdeme každý z těchto typů tabulek faktů a poté se zamyslíme nad tím, jak se nezměnily za roky, které uplynuly od poslední aktualizace Kimballova souboru nástrojů pro datové sklady. Pokud jste s těmito třemi kategoriemi tabulek faktů obeznámeni, přeskočte na analýzu na konci; pokud ne, považujte tento článek za stručné projití jedné ze základních součástí datového modelování ve stylu Kimball.
Dvě krátké poznámky, než začneme: zaprvé, tento článek předpokládá znalost hvězdicového schématu. Přečtěte si jej, pokud potřebujete základní informace – budu předpokládat, že rozumíte minimálně tabulkám faktů a dimenzí. Za druhé poznamenám, že Kimball rozeznává čtvrtý typ tabulky faktů – tabulku faktů timespan – ale používá se pouze za zvláštních okolností. Tu zde z naší diskuse vynecháme.
Tabulky faktů o transakcích
Tabulky faktů o transakcích jsou snadno pochopitelné: zákazník nebo obchodní proces provede nějakou věc; vy chcete zachytit výskyt této věci, a tak zaznamenáte transakci do datového skladu a můžete začít.
To nejlépe ilustruje jednoduchý příklad. Představme si, že provozujete obchod se smíšeným zbožím a máte elektronický pokladní systém, který zaznamenává každý uskutečněný prodej.
V typickém hvězdicovém schématu Kimballova typu by se tabulka faktů, která je středem vašeho schématu, skládala z údajů o transakcích s objednávkami. Jedná se především o číselné údaje, jako je celková částka objednávky, částky za jednotlivé položky, náklady na prodané zboží, částky uplatněných slev a podobně.
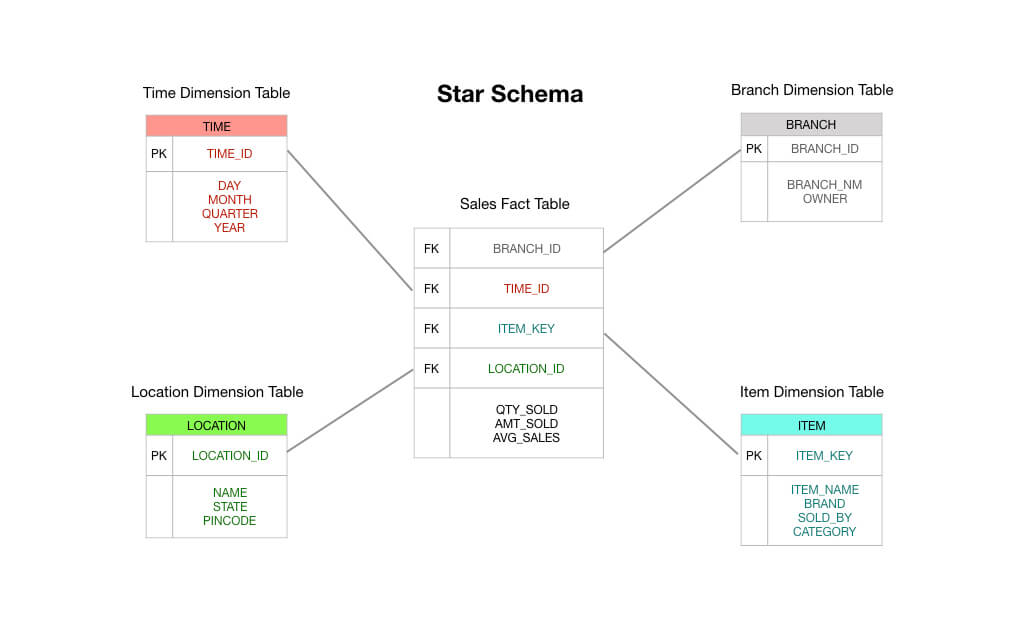
A tak vidíte, že tabulka faktů transakcí je přesně taková, jak je uvedeno na obalu: obdržíte transakci, zaznamenáte ji do tabulky faktů a ta se stane základem vašeho výkaznictví. V mnoha ohledech je tabulka faktů transakcí výchozím typem tabulky faktů, o kterém jsme zvyklí uvažovat.
Tabulky periodických snímků
Tabulky faktů periodických snímků jsou logickým rozšířením obyčejných tabulek faktů, které jsme právě popsali výše. Řádek v tabulce faktů s periodickými snímky zachycuje nějaký druh periodických dat – například denní snímek finančních ukazatelů nebo třeba týdenní přehled pohledávek či měsíční součet skladových čísel.
Jinými slovy, „zrnem“ nebo „úrovní rozlišení“ je období, nikoli jednotlivé transakce. Všimněte si, že pokud v určitém období nedojde k žádné transakci, musí být do tabulky periodických snímků vložen nový řádek, i když každý uložený fakt je nulový!
Tabulky periodických snímků obvykle obsahují neuvěřitelně velký počet polí. Je to proto, že do tabulky period lze strčit jakoukoli rozumně zajímavou metriku. Tak nějak si můžete představit scénář, kdy začínáte s agregovanými tržbami, výnosy a náklady na prodané zboží za týdenní období, ale postupem času vás vedení požádá o přidání dalších faktů, jako jsou úrovně zásob, metriky závazků a další zajímavá měření.
Proč jsou tabulky periodických snímků užitečné? No, to je poměrně jednoduché si představit. Pokud chcete mít přehled o trendových liniích klíčových ukazatelů výkonnosti ve vaší firmě, pomůže vám dotazování proti periodické tabulce faktů.
Kumulativní tabulky snímků
Na rozdíl od periodických tabulek snímků se kumulativní tabulky snímků vysvětlují trochu obtížněji. Abychom pochopili, proč Kimball a jeho kolegové přišli s tímto přístupem, pomůže nám pochopit něco málo o typech otázek, které byly kladeny podnikům v 90. letech, tedy v době, kdy byl poprvé napsán Data Warehouse Toolkit.
Na konci 80. let začali japonští výrobci porážet své americké protějšky na všechny možné nepříjemné, ale ne zjevné způsoby. Hlavním z nich bylo zaměření na rychlost provedení.
Výrobu lze vnímat jako řadu kroků. Na jednom konci továrny vezmete suroviny a na druhém konci z nich uděláte auta, telefony a widgety. Každý krok výrobního procesu lze měřit – jak dlouho například trvá přeměna ocelových bloků na ocelové pelety? Jak dlouho čekají v továrních zásobách? A jak dlouho trvá, než se z pelet vyrobí automobilové díly? Jak dlouho trvá, než se použijí ve skutečných automobilech?
Na konci 70. let si japonské společnosti začaly uvědomovat, že tento pohled na tvorbu hodnoty „v řadě kroků“ může vést k vážné konkurenční výhodě, pokud zkrátí dobu prodlevy mezi jednotlivými kroky. Konkrétněji řečeno: pokud se jim podaří snížit počet kroků potřebných k výrobě každé položky a pokud se jim podaří zkrátit dobu strávenou v rámci každého kroku, japonští výrobci zjistili, že mohou snížit plýtvání materiálem, snížit míru vad a zkrátit dodací lhůty a zároveň zvýšit produktivitu pracovníků, zvýšit objem výroby, rozšířit sortiment výrobků a snížit ceny – to vše současně.
Když přišla 90. léta, západní společnosti se toho chytily. Řada manažerských konzultantů – mezi nimi především George Stalk Jr. z Boston Consulting Group – začala prosazovat tempo realizace jako zdroj konkurenční výhody. Tito konzultanti nařídili společnostem, aby zaznamenávaly čas strávený v každém kroku výrobního procesu. Když přišla objednávka, jak dlouho se čekalo na její zpracování? Poté, co byla zpracována, jak dlouho trvalo, než byla objednávka odeslána do továrny? Jak dlouho trvalo, než byl výrobek v továrně dokončen? A jak dlouho pak čekal ve skladu? A nakonec, jak dlouho trvalo, než zákazník výrobek obdržel a získal z něj hodnotu?“
Podniky v 90. letech tak byly tlačeny k tomu, aby měřily doby zpoždění v celém procesu dodání podniku. Byly k tomu nuceny, protože japonská konkurence pronikala do mnoha odvětví, kterým dříve dominovaly západní společnosti – v některých případech způsobila bankroty a narušila celé dodavatelské řetězce. Právě v tomto prostředí Kimball pracoval.
Kumulativní faktografická tabulka snímků je tedy metodou měření rychlosti v rámci podnikového procesu. Vezměme si například tento obchodní řetězec, který Kimball představil ve druhém vydání knihy The Data Warehouse Toolkit:
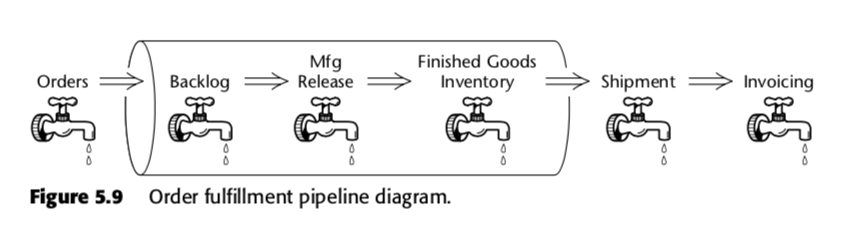
Pro tento proces Kimball navrhl následující tabulku kumulativních snímků:
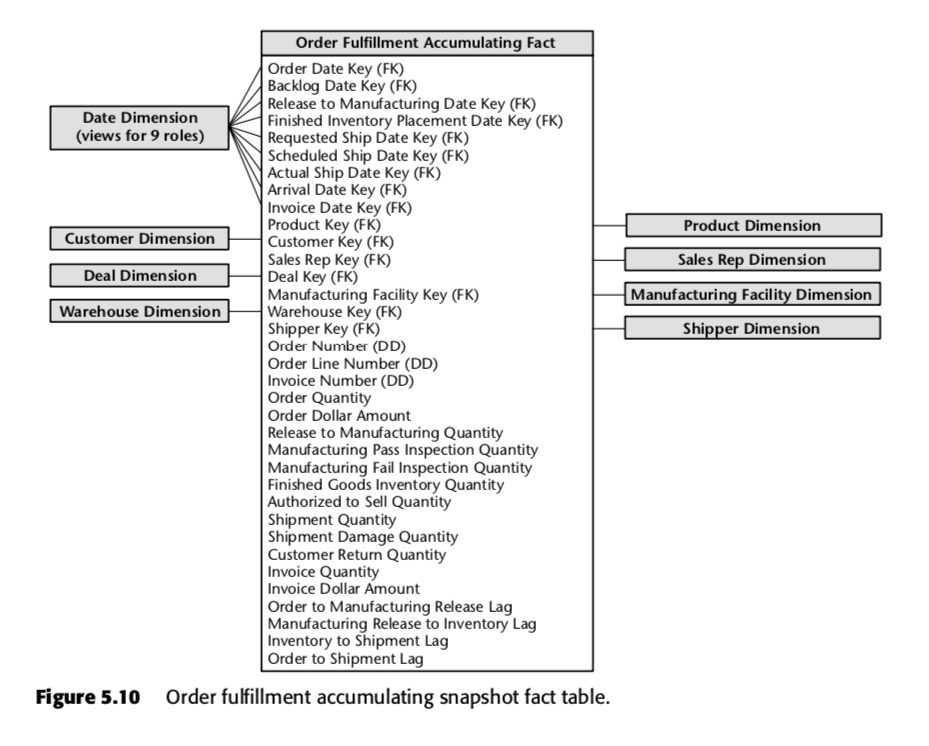
Každý řádek této tabulky představuje objednávku nebo dávku objednávek. Očekává se, že každý z těchto řádků bude několikrát aktualizován, jak budou procházet potrubím plnění objednávek. Všimněte si zejména obrovského množství datových polí v horní části schématu. Při prvním vytvoření řádku v této tabulce bude většina těchto dat začínat jako nuly, ale postupem času by se zaplnila. (Poznámka: Kimball zde místo vestavěného datového typu data SQL používá tabulku dimenze data, protože takový postup je The Kimball Way™ – umožňuje zachytit více informací o datech než jen naivní typy dat)
Důležitá jsou také pole ve spodní části tohoto seznamu. Každé z nich měří ukazatel zpoždění – tedy rozdíl mezi dvěma daty. Tak například Order to Manufacturing Release Lag je doba od Order Date do Release to Manufacturing Date; Inventory to Shipment Lag je doba od Finished Inventory Placement Date do Actual Ship Date atd. Jak čas plyne, každé z těchto dat bude vyplněno systémem ERP nebo třeba pracovníkem pro zadávání dat. Časy zpoždění pro každou konkrétní zakázku by se tedy počítaly tak, jak by se vyplňovala jednotlivá pole.
Dovedete si představit, jak by taková tabulka byla užitečná pro firmu působící v časovém konkurenčním prostředí. Pomocí jediné tabulky by management mohl zjistit, zda se zpožděné časy v jeho výrobě v čase zvyšují nebo snižují. Pomocí takového business intelligence může určit, které kroky jsou v jeho výrobním procesu nejproblematičtější. A mohou přijmout opatření v těch částech, které jim dělají největší starosti.
Poznámka na okraj: tyto myšlenky byly přizpůsobeny softwarovému světu pod terminologií „lean“; další informace o měření výroby v technologických firmách najdete v našich příspěvcích o knize Accelerate zde a zde.
Proč se nezměnily?“
Je důkazem Kimballa a jeho kolegů, že se tyto tři typy tabulek faktů od jejich první formulace v roce 1996 nijak podstatně nezměnily.
Proč tomu tak je? Odpověď podle mě spočívá v tom, že hvězdicové schéma vystihuje něco zásadního o podnikání. Pokud modelujete svá data tak, aby odpovídala vašim obchodním procesům, budete v podstatě zachycovat faktografické údaje jedním ze tří způsobů: prostřednictvím transakcí, pomocí srovnaných období a – pokud je vaše firma dostatečně důvtipná v oblasti časové konkurence – měřením časových prodlev mezi jednotlivými kroky systému poskytování hodnot.
Sám Kimball říká něco podobného. V příspěvku na blogu z roku 2015 píše:
Namísto toho, abychom se zabývali náboženskými spory o logických a fyzických modelech, měli bychom jednoduše uznat, že dimenzionální model je vlastně aplikační programové rozhraní (API) datového skladu. Síla tohoto API spočívá v konzistentním a jednotném rozhraní, které vidí všichni pozorovatelé, uživatelé i aplikace BI. Vidíme, že nezáleží na tom, kde jsou bity uloženy nebo jak jsou doručeny při spuštění požadavku API.
Hvězdicové schéma je prověřené časem. To je zřejmé.
V témže příspěvku pak Kimball dále tvrdí, že ani nedávné inovace, jako je sloupcový datový sklad, tuto skutečnost nezměnily; většina společností, s nimiž hovoří, nakonec stále končí u dimenzionální struktury modelu.
Ale věci se změnily. V celém souboru nástrojů datového skladu se objevují kuriózní zmínky o „omezení počtu faktů na jednu tabulku“ a „plánování strategie datového modelování za účasti všech zainteresovaných stran z dané oblasti“. To neodráží to, co vidíme v praxi v naší společnosti a v datových odděleních našich zákazníků.
Největší změnou je rychlost, s jakou nám současné technologie umožňují přejít od „naivní tabulky faktů“ k „dimenzionálnímu modelu Kimballova stylu“ – což nám umožňuje vynechat praxi předběžného modelování a místo toho se rozhodnout modelovat tak málo, jak je třeba. Tuto praxi umožňuje řada technologických změn, které jsme na tomto blogu probírali již dříve (především v příspěvku Vzestup a pád OLAP kostky), ale praktické důsledky na naše používání tabulek faktů jsou následující:
- Transakční tabulky faktů – jsme naprosto spokojeni s tlustými tabulkami faktů, s desítkami, ne-li stovkami faktů na řádek! To neznamená, že je to ideální situace, pouze to, že je to velmi přijatelný kompromis. Na rozdíl od Kimballovy doby je dnes datový talent neúměrně drahý; úložiště a výpočetní čas jsou levné. Proto nám naprosto nevadí, když některé tabulky faktů ponecháme tak, jak jsou – ve skutečnosti máme několik tabulek s více než 100 poli, které se do nich dostávají přímo ze zdrojových systémů! Náš filozofický postoj je následující: pokud máme komplexní požadavky na výkaznictví, pak se vyplatí věnovat čas a data řádně namodelovat. Ale pokud jsou reporty, které potřebujeme, jednoduché, pak využijeme výpočetní výkon, který máme k dispozici, a necháme tabulky faktů tak, jak jsou.
- Tabulky faktů s periodickými snímky – je překvapivé, jak moc se tomu dokážeme vyhnout. Protože moderní sloupcové datové sklady MPP jsou tak výkonné, nevytváříme periodické snapshotové tabulky faktů pro sestavy, které nejsou tak pravidelně používány. Doba provádění dotazů a dodatečné náklady, které si vyžádá generování sestav ze surových transakčních dat, jsou naprosto přijatelné, zejména pokud víme, že sestavu potřebujeme jen jednou za týden nebo podobně (nebo ji zpřístupníme pro periodické zkoumání). Pro ostatní datové sady generujeme periodické tabulky snímků podle původních Kimballových doporučení.
- Akumulace tabulek snímků – To se oproti Kimballově době téměř nezměnilo. Ale – jak říká sám Kimball – akumulační snapshotové tabulky jsou v praxi vzácné. Proto tomu nevěnujeme tolik pozornosti, jako by tomu mohla věnovat společnost, která se více řídí časem.
Je důležité zde poznamenat, že si myslíme, že modelování je důležité. Rozdíl je v tom, že naše praxe analýzy dat nám umožňuje kdykoli v budoucnu přehodnotit naše rozhodnutí o modelování. Jak to děláme? Inu, před transformací načítáme naše surová transakční data do našeho datového skladu. Tomu se říká „ELT“ na rozdíl od „ETL“. Protože všechny transformace provádíme v rámci datového skladu pomocí vrstvy datového modelování, můžeme se v případě potřeby k našim rozhodnutím vrátit a data předělat.
To nám umožňuje soustředit se především na poskytování obchodní hodnoty. Díky tomu je práce s datovým modelováním méně náročná.