Ralph Kimball’s dimensionele gegevensmodellering definieert drie soorten feitentabellen. Dit zijn:
- Transaction fact tables.
- Periodic snapshot tables, en
- Accumulating snapshot tables.
In deze post gaan we door elk van deze soorten fact tables, en dan reflecteren op hoe ze niet zijn veranderd in de jaren sinds Kimball voor het laatst de Data Warehouse Toolkit heeft bijgewerkt. Als je bekend bent met deze drie categorieën van feitentabellen, spring dan door naar de analyse aan het eind; als je dat niet bent, beschouw dit dan als een beknopt uitstapje door een van de basiscomponenten van Kimball-achtige gegevensmodellering.
Twee korte opmerkingen voordat we beginnen: ten eerste, dit stuk gaat uit van bekendheid met het sterrenschema. Lees dit als je een inleiding nodig hebt – ik ga ervan uit dat je feiten- en dimensietabellen op zijn minst begrijpt. Ten tweede zal ik opmerken dat Kimball een vierde type feitentabel erkent – de timespan feitentabel – maar die wordt alleen gebruikt in speciale omstandigheden. We laten dat hier buiten beschouwing.
Transaction Fact Tables
Transaction fact tables zijn gemakkelijk te begrijpen: een klant of bedrijfsproces doet iets; je wilt het optreden van dat ding vastleggen, en dus leg je een transactie vast in je data warehouse en je bent klaar om te gaan.
Dit kan het best worden geïllustreerd met een eenvoudig voorbeeld. Laten we ons voorstellen dat u een buurtwinkel runt, en u hebt een elektronisch verkooppuntsysteem (POS) dat elke verkoop registreert die u doet.
In een typisch Kimball-sterschema zou de feitentabel die in het centrum van uw schema staat, bestaan uit gegevens over ordertransacties. Dit zijn voornamelijk numerieke maten, zoals het totaal van de bestelling, de bedragen van de artikelen, de kosten van de verkochte goederen, de toegepaste kortingen, enzovoort.
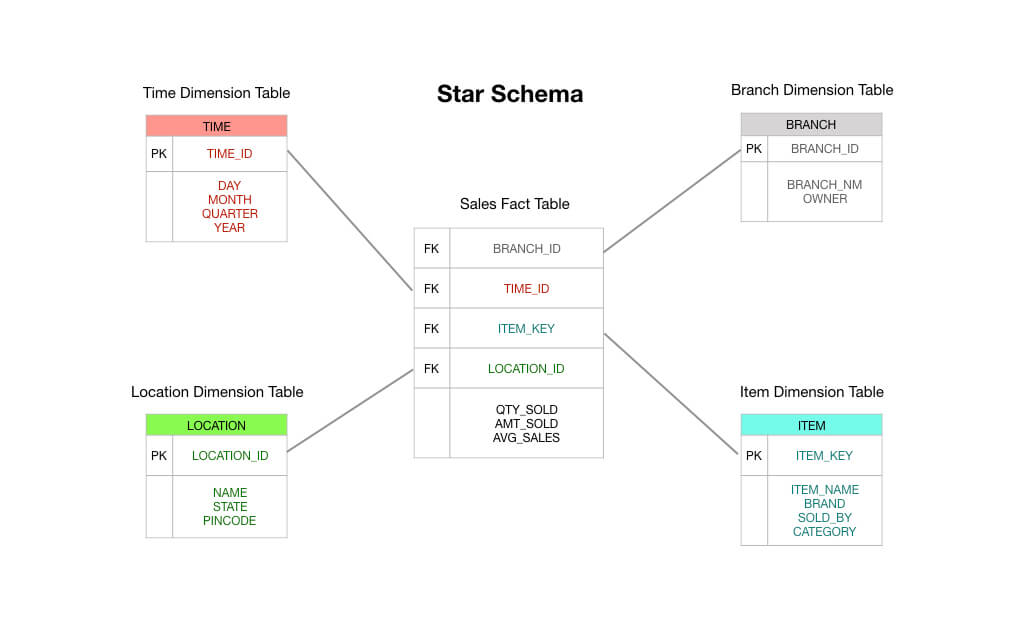
En zo zie je maar dat een feitentabel voor transacties precies is wat er op het plaatje staat: je ontvangt een transactie, je legt de transactie vast in je feitentabel, en dit wordt de basis van je rapportage. In veel opzichten is een transactie feitentabel het standaardtype feitentabel waaraan we gewend zijn te denken.
Periodic Snapshot Tables
Periodic snapshot feitentabellen zijn een logische uitbreiding op de gewone vanilla feitentabellen die we zojuist hierboven hebben behandeld. Een rij in een periodieke snapshot feitentabel legt een soort periodieke gegevens vast – bijvoorbeeld een dagelijkse snapshot van financiële statistieken, of misschien een wekelijks overzicht van debiteuren, of een maandelijks overzicht van voorraadaantallen.
Met andere woorden, de ‘korrel’ of het ‘resolutieniveau’ is de periode, niet de individuele transactie. Merk op dat als er in een bepaalde periode geen transacties plaatsvinden, een nieuwe rij in de periodieke snapshot-tabel moet worden ingevoegd, zelfs als elk feit dat wordt opgeslagen een nul is!
Periodieke snapshot-tabellen hebben de neiging een ongelooflijk groot aantal velden te bevatten. Dit komt omdat elke redelijk interessante metriek in de periodentabel kan worden geschoven. U kunt zich een scenario voorstellen waarin u begint met geaggregeerde verkopen, opbrengsten en kosten van verkochte goederen op een wekelijkse periode, maar naarmate de tijd verstrijkt, vraagt het management u om andere feiten toe te voegen, zoals voorraadniveaus, crediteuren metrics, en andere interessante metingen.
Waarom zijn periodieke snapshot tabellen nuttig? Nou, dit is vrij eenvoudig voor te stellen. Als u een overzicht wilt hebben van de trendlijnen in de belangrijkste prestatie-indicatoren in uw bedrijf, helpt het om query’s uit te voeren tegen een periodieke feitentabel.
Accumulating Snapshot Tables
In tegenstelling tot periodieke snapshot-tabellen, zijn accumulating snapshot-tabellen een beetje moeilijker uit te leggen. Om te begrijpen waarom Kimball en zijn collega’s met deze aanpak op de proppen kwamen, helpt het om iets te begrijpen van het soort vragen dat in de jaren ’90 aan het bedrijfsleven werd gesteld, de tijd waarin de Data Warehouse Toolkit voor het eerst werd geschreven.
In de late jaren ’80 begonnen Japanse fabrikanten hun Amerikaanse tegenhangers op allerlei vervelende, maar niet voor de hand liggende manieren te verslaan. De belangrijkste daarvan was een focus op uitvoeringssnelheid.
Fabricage kan worden gezien als een reeks stappen. Je neemt ruw materiaal aan de ene kant van de fabriek, en maakt er auto’s, telefoons en widgets van aan de andere kant. Elke stap van het fabricageproces kan worden gemeten – hoe lang duurt het bijvoorbeeld om staalblokken om te zetten in staalkorrels? Hoe lang wachten ze op voorraad in de fabriek? En vanaf daar, hoe lang voordat de pellets worden verwerkt tot auto-onderdelen? Hoe lang voordat ze daadwerkelijk in auto’s worden gebruikt?
Eind jaren ’70 begonnen Japanse bedrijven zich te realiseren dat deze ‘reeks stappen’-opvatting van waardecreatie tot een serieus concurrentievoordeel kon leiden als ze de tijd tussen elke stap konden verkorten. Meer concreet: als ze het aantal stappen konden verminderen die nodig zijn om elk product te produceren en als ze de tijd konden verkorten die binnen elke stap werd doorgebracht, leerden Japanse fabrikanten dat ze materiaalverspilling konden verminderen, het aantal defecten konden terugdringen en de levertijd konden verkorten, terwijl ze tegelijkertijd de productiviteit van werknemers konden verhogen, het productievolume konden vergroten, de productvariëteit konden uitbreiden en de prijzen konden verlagen – en dat allemaal tegelijkertijd.
Tegen de jaren ’90 hadden de westerse bedrijven dit begrepen. Een aantal managementconsultants – waaronder George Stalk Jr van de Boston Consulting Group – begon uitvoeringssnelheid te bepleiten als een bron van concurrentievoordeel. Deze consultants instrueerden bedrijven de tijd te registreren die aan elke stap van het productieproces werd besteed. Wanneer een order binnenkwam, hoe lang moest die dan worden verwerkt? Nadat het was verwerkt, hoe lang duurde het voordat de order naar de fabriek werd gestuurd? In de fabriek, hoe lang duurde het voordat het product klaar was? En hoe lang wachtte het dan in de voorraad? En tenslotte, hoe lang duurde het voordat de klant het product ontving en er waarde aan ontleende?
Ze werden in de jaren ’90 dus onder druk gezet om vertragingen te meten in het hele leveringsproces van hun bedrijf. Zij werden hiertoe gedwongen omdat Japanse concurrenten binnendrongen in veel industrieën die voorheen door westerse bedrijven werden gedomineerd – in sommige gevallen veroorzaakten zij faillissementen en ontwrichtten zij hele toeleveringsketens. Het was in deze omgeving dat Kimball aan het werk was.
De accumulating snapshot fact table is dus een methode om de snelheid binnen het bedrijfsproces te meten. Neem bijvoorbeeld deze bedrijfspijplijn, die Kimball presenteerde in de tweede editie van The Data Warehouse Toolkit:
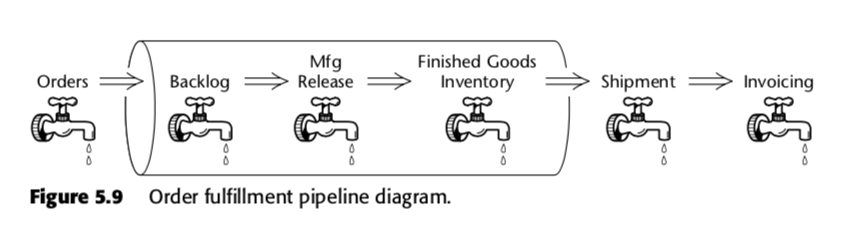
Voor dat proces stelde Kimball de volgende accumulating snapshot tabel voor:
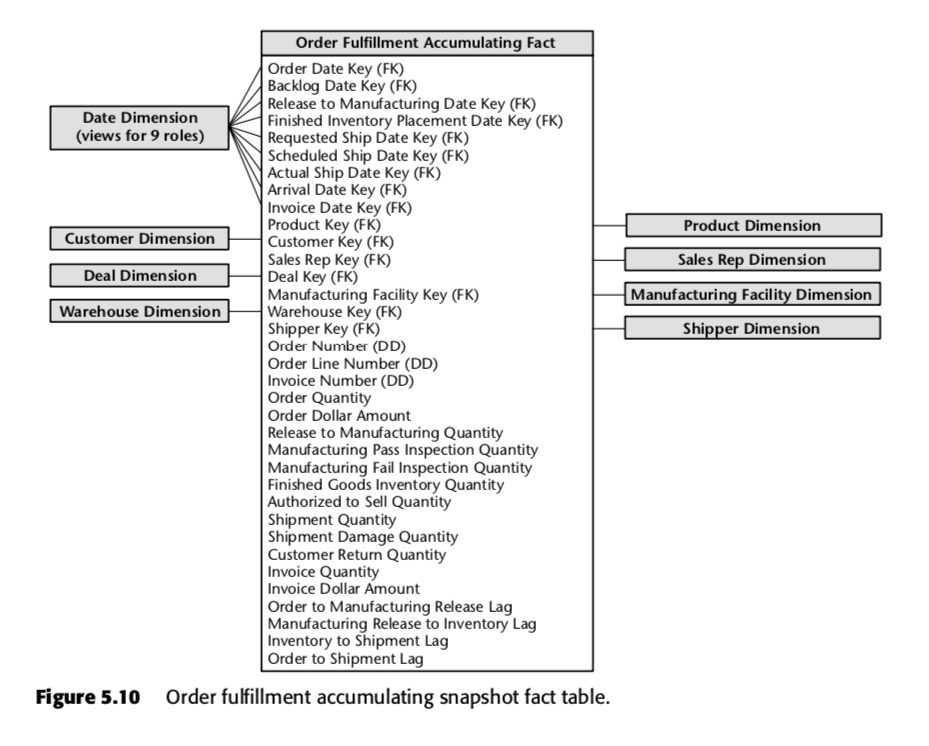
Elke rij in deze tabel vertegenwoordigt een order of een batch van orders. Verwacht wordt dat elk van deze rijen meerdere keren wordt bijgewerkt naarmate ze door de orderverwerkingspijplijn gaan. Let in het bijzonder op het enorme aantal datumvelden bovenaan in het schema. Wanneer een rij voor het eerst wordt aangemaakt in deze tabel, zullen de meeste van deze data beginnen als nullen, maar zullen uiteindelijk worden opgevuld naarmate de tijd verstrijkt. (Opmerking: Kimball gebruikt hier een datum dimensie tabel, in plaats van het ingebouwde SQL datum data type, omdat dit The Kimball Way ™ is – het stelt je in staat om meer informatie over datums vast te leggen dan alleen de naïeve datum types.)
Ook belangrijk zijn de velden onderaan die lijst. Elk van hen meet een vertragingsindicator – dat wil zeggen, het verschil tussen twee datums. Dus, bijvoorbeeld, Order to Manufacturing Release Lag is de tijd die nodig is van Order Date tot Release to Manufacturing Date; Inventory to Shipment Lag is de tijd die nodig is van Finished Inventory Placement Date tot Actual Ship Date, enzovoort. Naarmate de tijd verstrijkt, zal elk van deze data worden ingevuld door een ERP-systeem of misschien door een data-entry knor. De vertragingstijden voor elke specifieke order zouden dus worden berekend als elk veld wordt ingevuld.
U kunt zien hoe een dergelijke tabel nuttig zou zijn voor een bedrijf dat opereert binnen een op tijd gebaseerde concurrerende omgeving. Met behulp van een enkele tabel zou het management in staat zijn om te zien of de vertragingen in haar productie in de loop van de tijd toenemen of afnemen. Zij kunnen deze bedrijfsinformatie gebruiken om te bepalen welke stappen in hun productieproces de meeste problemen opleveren. En ze kunnen actie ondernemen op de stukjes die hen de meeste zorgen baren.
Side note: deze ideeën zijn aangepast aan de softwarewereld onder de terminologie van ‘lean’; voor meer informatie over het meten van de productie binnen techbedrijven, bekijk onze berichten over het boek Accelerate hier en hier.
Waarom zijn ze niet veranderd?
Het is een bewijs voor Kimball en zijn collega’s dat de drie soorten feitentabellen niet wezenlijk zijn veranderd sinds ze voor het eerst werden verwoord in 1996.
Waarom is dit het geval? Het antwoord ligt, denk ik, in het feit dat het sterrenschema iets fundamenteels over zaken vastlegt. Als u uw gegevens zo modelleert dat ze overeenkomen met uw bedrijfsprocessen, gaat u feitgegevens vrijwel op een van de volgende drie manieren vastleggen: via transacties, met gecollationeerde perioden, en – als uw bedrijf savvy genoeg is op het gebied van tijdgebaseerde concurrentie – door de vertragingstijden te meten tussen elke stap van uw waarde-leveringssysteem.
Kimball zelf zegt iets soortgelijks. In een blogpost uit 2015 schrijft hij:
In plaats van te blijven hangen in religieuze argumenten over logische versus fysieke modellen, moeten we gewoon erkennen dat een dimensionaal model eigenlijk een datawarehouse applications programming interface (API) is. De kracht van deze API ligt in de consistente en uniforme interface die door alle waarnemers, zowel gebruikers als BI-toepassingen, wordt gezien. We zien dat het niet uitmaakt waar de bits zijn opgeslagen of hoe ze worden aangeleverd wanneer een API-verzoek wordt gestart.
Het sterrenschema is beproefd in de tijd. Zoveel is duidelijk.
In dezelfde post betoogt Kimball vervolgens dat zelfs recente innovaties zoals het kolom-datawarehouse dit feit niet hebben veranderd; de meerderheid van de bedrijven waarmee hij spreekt, eindigt aan het eind van de dag nog steeds met een dimensionale modelstructuur.
Maar de dingen zijn veranderd. Door de hele Data Warehouse Toolkit heen staan vreemde opmerkingen over ‘het beperken van het aantal feiten per tabel’, en ‘het plannen van je datamodelleringsstrategie met alle belanghebbenden in het domein aanwezig bij de vergadering’. Dit komt niet overeen met wat we in de praktijk zien bij ons en in de data-afdelingen van onze klanten.
De grootste verandering is de snelheid waarmee de huidige technologieën ons in staat stellen om over te schakelen van ‘naïeve feitentabel’ naar ‘Kimball-stijl dimensionaal model’ – waarmee we de praktijk van up-front modellering kunnen overslaan, en in plaats daarvan ervoor kiezen om zo weinig mogelijk te modelleren als we nodig hebben. Deze praktijk wordt mogelijk gemaakt door een aantal technologische veranderingen die we al eerder op deze blog hebben besproken (met name in onze post over The Rise and Fall of the OLAP Cube), maar de praktische implicaties voor ons gebruik van feitentabellen zijn als volgt:
- Transactie feitentabellen – we zijn volkomen tevreden met dikke feitentabellen, met tientallen, zo niet honderden feiten per rij! Dat wil niet zeggen dat dit een ideale situatie is, alleen dat het een zeer aanvaardbaar compromis is. Anders dan in Kimballs tijd is datatalent vandaag onbetaalbaar duur; opslag- en rekentijd zijn goedkoop. Wij vinden het dus prima om bepaalde feitentabellen te laten zoals ze zijn – wij hebben er zelfs verschillende met meer dan 100 velden erin, die rechtstreeks uit onze bronsystemen zijn gepijpt! Onze filosofische houding is: als we complexe rapporteringseisen hebben, dan is het de moeite waard om de tijd te nemen en de gegevens goed te modelleren. Maar als de rapporten die we nodig hebben eenvoudig zijn, dan maken we gebruik van de rekenkracht die ons ter beschikking staat en laten we de feitentabellen zoals ze zijn.
- Periodieke snapshot feitentabellen – het is verrassend hoeveel we in staat zijn om dit te vermijden. Omdat moderne MPP-kolomsgewijze datawarehouses zo krachtig zijn, maken we geen periodieke snapshot-feittabellen voor rapporten die niet zo regelmatig worden gebruikt. De query-uitvoeringstijd en de extra kosten die het kost om rapporten te genereren op basis van ruwe transactiegegevens, zijn perfect aanvaardbaar, vooral als we weten dat het rapport slechts een keer per week of zo nodig is (of beschikbaar wordt gesteld voor periodieke verkenning). Voor andere datasets genereren we wel periodieke snapshot tabellen volgens Kimball’s oorspronkelijke aanbevelingen.
- Accumuleren van snapshot tabellen – Dit is vrijwel ongewijzigd ten opzichte van Kimball’s tijd. Maar – zoals Kimball zelf zegt – accumulerende snapshot tabellen zijn zeldzaam in de praktijk. Dus we denken hier niet zo over na als een meer tijd-gedreven bedrijf zou doen.
Het is belangrijk om hier op te merken dat we modellering wel belangrijk vinden. Het verschil is dat onze praktijk van data-analyse ons in staat stelt om onze modelleringsbeslissingen op elk moment in de toekomst te heroverwegen. Hoe doen we dat? Wel, we laden onze ruwe transactionele gegevens in ons data warehouse voordat we transformeren. Dit staat bekend als “ELT” in tegenstelling tot “ETL”. Omdat we al onze transformaties binnen het data warehouse doen, met gebruikmaking van een datamodelleringslaag, zijn we in staat onze keuzes te herzien en onze gegevens te hermodelleren als de noodzaak zich voordoet.
Dit stelt ons in staat ons eerst te richten op het leveren van bedrijfswaarde. Het houdt de data modeling druk-werk laag.