A modelagem de dados dimensionais do Ralph Kimball define três tipos de tabelas de fatos. Estes são:
- Tabelas de fatos de transação.
- Tabelas de snapshot periódicas, e
- Aumular tabelas de snapshot.
Neste post, vamos analisar cada um desses tipos de tabelas de fatos, e depois refletir sobre como elas não mudaram nos anos desde a última atualização do Data Warehouse Toolkit do Kimball. Se você está familiarizado com essas três categorias de tabelas de fatos, pule para a análise no final; se não estiver, considere isso como uma brincadeira concisa através de um dos componentes básicos da modelagem de dados no estilo Kimball-.
Duas notas rápidas antes de começarmos: primeiro, esta peça assume a familiaridade com o esquema estelar. Leia isto se você precisar de um primer – vou assumir que você entende as tabelas de fatos e dimensões como um mínimo. Segundo, vou notar que Kimball reconhece um quarto tipo de tabela de fatos – a tabela de fatos de intervalo de tempo – mas só é usada para circunstâncias especiais. Vamos deixar isso fora de nossa discussão aqui.
Tabelas de fatos de transação
As tabelas de fatos de transação são fáceis de entender: um cliente ou processo comercial faz alguma coisa; você quer capturar a ocorrência dessa coisa, e então você registra uma transação em seu data warehouse e está pronto para ir.
Isso é melhor ilustrado com um exemplo simples. Vamos imaginar que você está rodando uma loja de conveniência, e você tem um sistema eletrônico de ponto de venda (POS) que registra cada venda que você faz.
Em um típico esquema de estrela estilo Kimball-, a tabela de fatos que está no centro do seu esquema consistiria em dados de transação de pedidos. Essas são principalmente medidas numéricas como total do pedido, montantes de partidas individuais, custo de produtos vendidos, montantes de desconto aplicados e assim por diante.
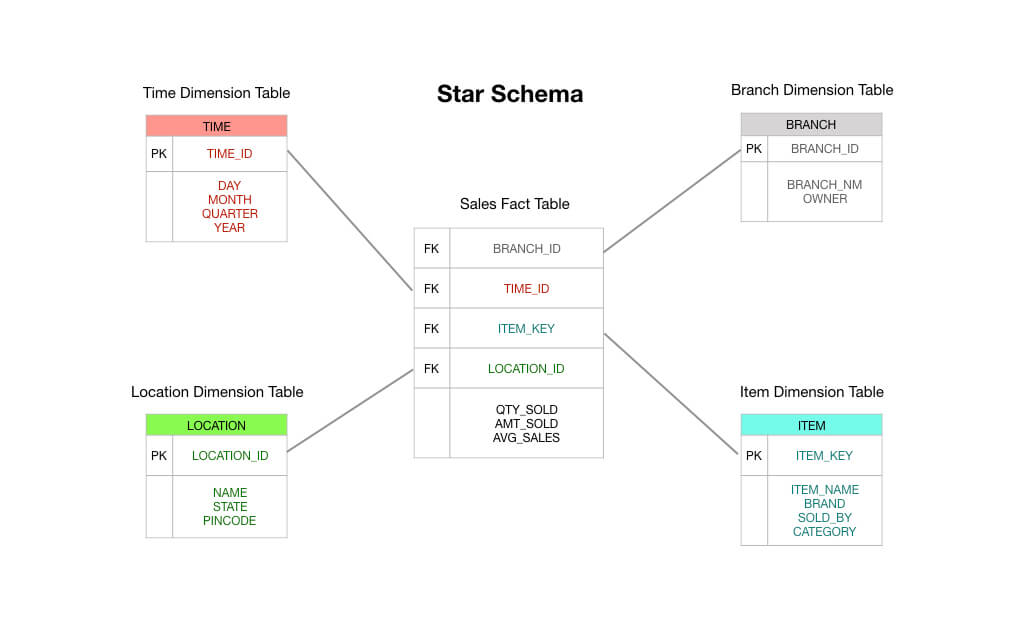
E assim você pode ver que uma tabela de fatos de transação é exatamente como diz na lata: você recebe uma transação, registra a transação na sua tabela de fatos, e isso se torna a base do seu relatório. De muitas maneiras, uma tabela de fatos sobre transações é o tipo padrão de tabela de fatos que estamos acostumados a pensar.
Periodic Snapshot Tables
Periodic snapshot fact tables are a logical extension to the plain vanilla fact tables that we’ve just covered above. Uma linha em uma tabela de fatos periódicos captura algum tipo de dado periódico – por exemplo, um instantâneo diário de métricas financeiras, ou talvez um resumo semanal de contas a receber, ou uma contagem mensal de números de inventário.
Em outras palavras, o ‘grão’ ou ‘nível de resolução’ é o período, não a transação individual. Note que se nenhuma transação ocorrer durante um determinado período, uma nova linha deve ser inserida na tabela de snapshot periódica, mesmo se cada fato que for salvo for um nulo!
As tabelas de snapshot periódicas tendem a conter um número incrivelmente grande de campos. Isto é porque qualquer métrica razoavelmente interessante pode ser inserida na tabela de períodos. Você pode imaginar um cenário onde você começa com vendas agregadas, receita e custo do bem vendido em um período semanal, mas com o passar do tempo, a gerência pede que você adicione outros fatos como níveis de estoque, métricas de contas a pagar e outras medidas interessantes.
Por que as tabelas de snapshot periódicas são úteis? Bem, isto é bastante simples de imaginar. Se você quiser ter uma visão geral das linhas de tendência nos indicadores-chave de desempenho do seu negócio, isso ajuda a consultar uma tabela periódica de fatos.
Acumular tabelas de instantâneos
Não se parece com tabelas periódicas de instantâneos, acumular tabelas de instantâneos é um pouco mais difícil de explicar. Para entender porque Kimball e seus pares inventaram essa abordagem, ajuda a entender um pouco sobre os tipos de perguntas que eram feitas aos negócios nos anos 90, que foi quando o Data Warehouse Toolkit foi escrito pela primeira vez.
No final dos anos 80, os fabricantes japoneses começaram a bater seus homólogos americanos em todos os tipos de maneiras desagradáveis, mas não óbvias. O foco principal foi a velocidade de execução.
A fabricação pode ser vista como uma série de passos. Você pega a matéria prima em uma ponta da fábrica, e a transforma em carros, telefones e widgets na outra ponta. Cada etapa do processo de fabricação pode ser medida – quanto tempo leva para transformar blocos de aço em pellets de aço, por exemplo? Quanto tempo eles esperam no inventário da fábrica? E a partir daí, quanto tempo até que as pelotas sejam fabricadas em peças de automóveis? Quanto tempo antes de serem utilizados em automóveis reais?
No final dos anos 70, as empresas japonesas começaram a perceber que esta visão de “série de passos” de criação de valor poderia levar a uma séria vantagem competitiva se reduzissem o tempo de atraso entre cada passo. Mais concretamente: se conseguissem reduzir o número de passos dados para produzir cada item e se conseguissem reduzir o tempo gasto em cada passo, os fabricantes japoneses aprenderam que podiam reduzir o desperdício de material, diminuir as taxas de defeitos e diminuir o tempo de entrega, ao mesmo tempo que aumentavam a produtividade dos trabalhadores, aumentavam o volume de produção, expandiam a variedade de produtos e reduziam os preços – tudo ao mesmo tempo.
Quando a década de 90 chegou, as empresas ocidentais já tinham percebido. Vários consultores de gestão – entre eles George Stalk Jr do Boston Consulting Group – começaram a defender o tempo de execução como uma fonte de vantagem competitiva. Esses consultores instruíram as empresas a registrar o tempo gasto em cada etapa do processo de produção. Quando um pedido chegava, quanto tempo esperava para ser processado? Depois de processado, muito antes do pedido ser enviado para a fábrica? Na fábrica, quanto tempo antes de o produto ser concluído? E depois, quanto tempo esperou no inventário? E finalmente, quanto tempo demorou até o cliente receber o produto e obter o valor do mesmo?
Os negócios nos anos 90 foram assim pressionados a medir os tempos de atraso ao longo de todo o seu processo de entrega comercial. Eles foram forçados a fazer isso porque os concorrentes japoneses estavam fazendo incursões em muitas indústrias anteriormente dominadas por empresas ocidentais – em alguns casos, causando falências e perturbando cadeias de fornecimento inteiras. Foi nesse ambiente que a Kimball estava trabalhando.
A tabela de fatos acumulados é, portanto, um método para medir a velocidade dentro do processo de negócios. Tomemos, por exemplo, este pipeline empresarial, que Kimball apresentou na segunda edição do The Data Warehouse Toolkit:
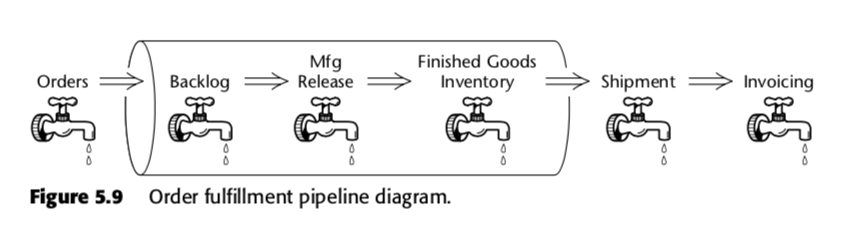
Para esse processo, Kimball propôs a seguinte tabela de instantâneos acumulados:
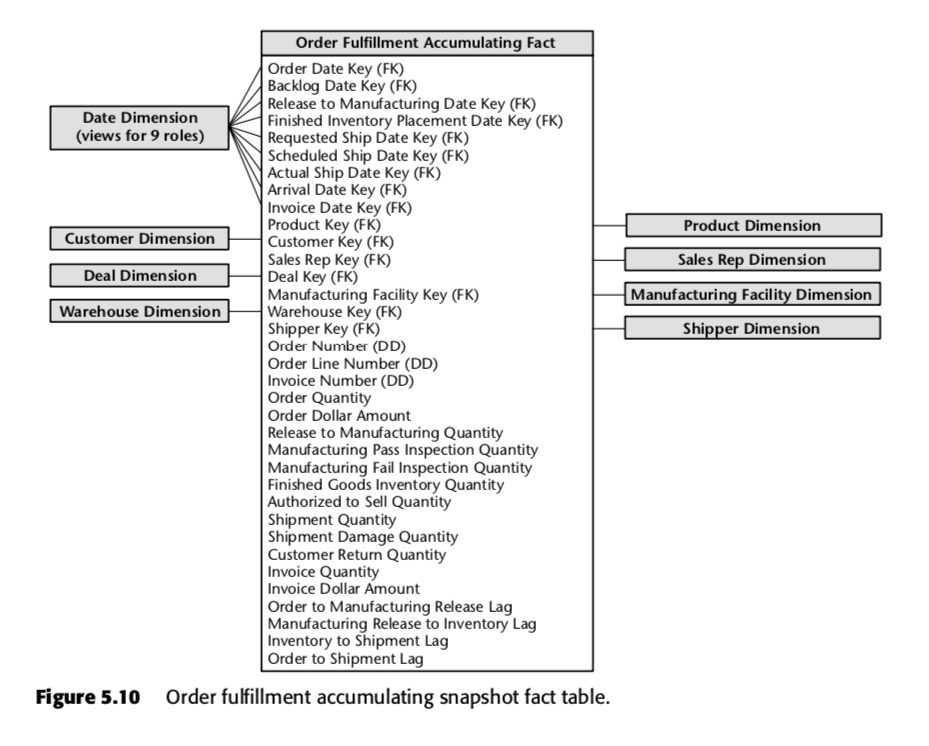
Cada linha desta tabela representa um pedido ou um lote de pedidos. Espera-se que cada uma destas linhas seja actualizada várias vezes à medida que avançam através do pipeline de cumprimento de encomendas. Observe em particular o número absoluto de campos de data no topo do esquema. Quando uma linha é criada pela primeira vez nesta tabela, a maioria destas datas começará como nulos, mas acabará por ser preenchida à medida que o tempo passa. (Nota: o Kimball utiliza aqui uma tabela de dimensões de datas, em vez do tipo de dados de data SQL incorporado, porque ao fazê-lo é The Kimball Way ™ – permite capturar mais informações sobre datas do que apenas os tipos de datas ingénuos.)
Tão importantes são os campos na parte inferior dessa lista. Cada um deles mede um indicador de atraso – ou seja, a diferença entre duas datas. Assim, por exemplo, Order to Manufacturing Release Lag é o tempo decorrido de Order Date a Release to Manufacturing Date; Inventory to Shipment Lag é o tempo decorrido de Finished Inventory Placement Date a Actual Ship Date, e assim por diante. Conforme o tempo passa, cada uma destas datas será preenchida por um sistema ERP ou talvez por um grunt de entrada de dados. Os tempos de atraso para cada ordem em particular seriam assim calculados à medida que cada campo fosse preenchido.
Você pode ver como tal tabela seria útil para uma empresa que opera dentro de um ambiente competitivo baseado no tempo. Usando uma única tabela, a gerência seria capaz de ver se os tempos de retardamento em sua produção estão aumentando ou diminuindo com o tempo. Eles podem usar essa inteligência de negócios para determinar quais etapas são as mais problemáticas em seu processo de produção. E podem agir sobre os bits que lhes são mais preocupantes.
Nota lateral: estas ideias foram adaptadas ao mundo do software sob a terminologia de ‘lean’; para mais informações sobre a medição da produção dentro das empresas de tecnologia, veja os nossos posts sobre o livro Accelerate aqui e aqui.
Por que Não Mudaram?
É uma prova para Kimball e seus pares que os três tipos de tabelas de fatos não mudaram materialmente desde que foram articuladas pela primeira vez em 1996.
Por que é este o caso? A resposta, eu acho, está no fato de que o esquema estelar captura algo fundamental nos negócios. Se você modelar seus dados para corresponder aos seus processos de negócio, você vai capturar dados de fato de uma de três maneiras: através de transações, com períodos compilados, e – se o seu negócio tem conhecimento suficiente sobre a concorrência baseada no tempo – medindo os tempos de atraso entre cada passo do seu sistema de entrega de valores.
O próprio Kimball diz algo semelhante. Em um post de blog de 2015, ele escreve:
Rather than getting hung up on religious arguments about logical versus physical models, we should simply recognise that a dimensional model is actually a data warehouse applications programming interface (API). O poder dessa API reside na interface consistente e uniforme vista por todos os observadores, tanto usuários quanto aplicações de BI. Vemos que não importa onde os bits são armazenados ou como eles são entregues quando uma requisição API é lançada.
O esquema estelar é testado pelo tempo. Isto é óbvio.
No mesmo post, Kimball argumenta então que mesmo inovações recentes como o data warehouse columnar não mudaram este fato; a maioria das empresas que ele fala ainda acabam com uma estrutura de modelo dimensional no final do dia.
Mas as coisas mudaram. Em todo o Data Warehouse Toolkit são feitas referências curiosas à ‘limitação do número de fatos por tabela’ e ao ‘planejamento de sua estratégia de modelagem de dados com todos os participantes do domínio presentes na reunião’. Estas não reflectem o que estamos a ver na prática na nossa empresa, e nos departamentos de dados dos nossos clientes.
A maior mudança é a velocidade a que as tecnologias actuais nos permitem passar da ‘tabela de factos ingénuos’ para o ‘modelo dimensional estilo Kimball-‘ – o que nos permite saltar a prática da modelação inicial, e em vez disso optar pela modelação tão pouco quanto necessário. Esta prática é permitida por uma série de mudanças tecnológicas que já discutimos neste blog (mais notavelmente, no nosso post sobre A Ascensão e Queda do Cubo OLAP) mas as implicações práticas no nosso uso de tabelas de fatos são as seguintes:
- Tabelas de fatos de transações – estamos perfeitamente felizes em ter tabelas de fatos gordos, com dezenas se não centenas de fatos por linha! Isto não quer dizer que esta seja uma situação ideal, apenas que é um compromisso muito aceitável. Ao contrário do tempo do Kimball, o talento dos dados hoje em dia é proibitivamente caro; o tempo de armazenamento e computação é barato. Portanto, estamos perfeitamente de acordo em deixar certas tabelas de fatos como elas são – na verdade, temos várias com mais de 100 campos nelas, canalizadas diretamente de nossos sistemas de origem! Nossa postura filosófica é: se temos exigências complexas de relatórios, então vale a pena tomar o tempo e modelar os dados corretamente. Mas se os relatórios que precisamos são simples, então aproveitamos o poder computacional disponível e deixamos as tabelas de fatos como estão.
- Tabelas de fatos periódicos – é surpreendente o quanto somos capazes de evitar fazer isso. Como os modernos MPP columnar data warehouses são tão poderosos, nós não criamos tabelas de fatos periódicos para relatórios que não são tão usados regularmente. O tempo de execução da consulta e o custo adicional necessário para gerar relatórios a partir de dados brutos de transações é perfeitamente aceitável, especialmente se soubermos que o relatório só é necessário uma vez por semana ou mais (ou disponibilizado para exploração periódica). Para outros conjuntos de dados, geramos tabelas de snapshot periódicas conforme as recomendações originais do Kimball.
- Acumulando tabelas de snapshot – Isto é quase inalterado em relação ao tempo do Kimball. Mas – como o próprio Kimball diz – o acúmulo de tabelas de instantâneos é raro na prática. Por isso, não pensamos nisso tanto quanto uma empresa mais orientada pelo tempo poderia fazer.
É importante notar aqui que achamos que a modelagem é importante. A diferença é que a nossa prática de análise de dados nos permite revisitar as nossas decisões de modelagem a qualquer momento no futuro. Como é que fazemos isto? Bem, nós carregamos os nossos dados transaccionais brutos para o nosso armazém de dados antes de os transformarmos. Isto é conhecido como ‘ELT’ em oposição a ‘ETL’. Porque fazemos todas as nossas transformações dentro do data warehouse, usando uma camada de modelagem de dados, somos capazes de revisitar nossas escolhas e remodelar nossos dados se a necessidade surgir.
Isso nos permite focar na entrega do valor do negócio primeiro. Isto mantém o trabalho de modelagem de dados ocupado – trabalho baixo.