Ralph Kimball氏のディメンション・データ・モデリングでは、ファクト・テーブルを3つのタイプに分けて定義している。 これらは、
- Transaction fact tables、
- Periodic snapshot tables、および
- Accumulating snapshot tablesです。
この投稿では、これらの各ファクト テーブルの種類を見ていき、次に Kimball が Data Warehouse Toolkit を最後に更新してから数年間、これらがどのように変化していないかに思いを巡らせてみたいと思います。 そうでない場合は、Kimball スタイルのデータ モデリングの基本コンポーネントの 1 つを簡潔に説明するものだと考えてください。 入門が必要な場合はこれを読んでください。最低限、ファクトおよびディメンジョン テーブルを理解していると仮定しています。 第2に、Kimballは第4のタイプのファクト・テーブルであるタイムスパンファクトテーブルを認識していますが、これは特殊な状況でのみ使用されることに留意してください。 顧客またはビジネス プロセスが何らかの処理を行った場合、その処理の発生をキャプチャする必要があるため、データ ウェアハウスにトランザクションを記録します。 典型的な Kimball スタイルのスター型スキーマでは、スキーマの中心にあるファクト テーブルは、注文トランザクション データで構成されます。 これらは主に、注文合計、明細金額、売上原価、適用された割引額などの数値メジャーです。
したがって、トランザクション ファクト テーブルは、その説明のとおり、トランザクションを受け取り、ファクト テーブルにトランザクションを記録し、これが報告の基礎となることがおわかりいただけると思います。 多くの点で、トランザクション ファクト テーブルは、私たちが考えるのに慣れているファクト テーブルのデフォルト タイプです。
期間スナップショット テーブル
期間スナップショット ファクト テーブルは、上記で説明した単純なファクト テーブルの論理的拡張です。 たとえば、財務指標の日次スナップショット、売掛金の週次サマリー、または在庫数の月次集計などです。
言い換えれば、「粒度」または「解決レベル」は期間であり、個々のトランザクションではありません。 ある期間にトランザクションが発生しない場合、保存されるすべてのファクトが null であっても、定期的なスナップショット テーブルに新しい行が挿入されなければならないことに注意してください!
定期的なスナップショット テーブルは、非常に多くのフィールドを含む傾向があります。 これは、合理的に興味深いメトリックはすべて周期テーブルに押し込まれる可能性があるためです。 最初は週次で集計された売上、収益、および商品売上原価からスタートし、時間が経つにつれて、在庫レベル、買掛金メトリクス、およびその他の興味深い測定値などの他の事実を追加するように経営陣から依頼されるシナリオを想像してください。 まあ、これは想像するのがかなり簡単です。 ビジネスにおける主要なパフォーマンス インジケーターのトレンド ラインの概要を把握したい場合、周期的なファクト テーブルに対してクエリを実行すると便利です。 Kimball 氏と彼の仲間がこのアプローチを考え出した理由を理解するには、Data Warehouse Toolkit が最初に作成された 90 年代にビジネスで問われていた質問について少し理解するのに役立ちます。 その最たるものが、実行速度への注力です。
製造業は、一連の工程と見なすことができます。 工場の一方の端で原料を採取し、もう一方の端でそれを車や電話やウィジェットに変えます。 例えば、鉄のブロックを鉄のペレットに変えるのに、どれくらいの時間がかかるのでしょうか。 例えば、鉄のブロックを鉄のペレットにするのに何分かかるか、ペレットが工場の在庫になるまでに何日かかるか。 そして、そのペレットが自動車部品に加工されるまでには、どれくらいの時間がかかるのか。
70年代後半、日本企業は、この「一連のステップ」による価値創造が、各ステップ間のタイムラグを減らすことで深刻な競争優位につながることに気付き始めた。 より具体的には、各アイテムの生産にかかる工程数を減らし、各工程で費やす時間を短縮すれば、日本のメーカーは材料の無駄を減らし、不良率を下げ、納期を短縮すると同時に、労働者の生産性を上げ、製造量を増やし、製品の種類を増やし、価格を下げることができることを知ったのだ。 ボストン・コンサルティング・グループのジョージ・ストークJrを筆頭に、多くの経営コンサルタントが、競争優位の源泉として実行テンポを唱え始めたのである。 ボストンコンサルティンググループのジョージ・ストークJr.を筆頭に、多くの経営コンサルタントが「実行のテンポ」を競争力の源泉とし、生産工程の各ステップで費やした時間を記録するよう指導した。 注文が入ってから処理されるまでの時間は? 注文が入ってから、工場に送るまでの時間は? 工場で、製品が完成するまでの時間は? そして、在庫になるまでの期間は?
このように、90年代の企業は、ビジネスのデリバリー・プロセス全体にわたってタイムラグを測定するように圧力をかけられました。 日本の競合他社が、以前は欧米企業が支配していた多くの産業に進出し、場合によっては倒産やサプライチェーン全体の破壊を引き起こしたからである。 このような環境で、Kimball 氏は作業を行っていました。
このように、累積スナップショット ファクト テーブルは、ビジネス プロセス内の速度を測定するための方法です。 たとえば、Kimball 氏が The Data Warehouse Toolkit の第 2 版で提示したこのビジネス パイプラインを考えてみましょう。
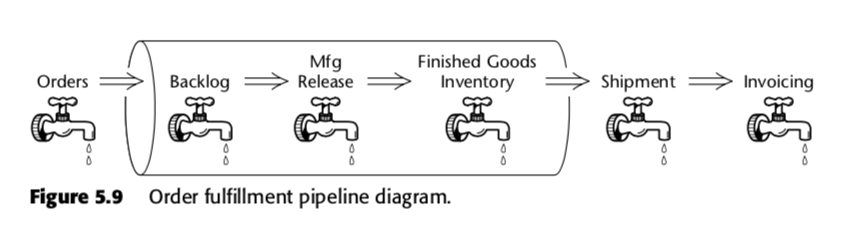
そのプロセスに対して、Kimball 氏は次のような蓄積型スナップショット テーブルを提案しました。 これらの各行は、注文処理パイプラインを進むにつれて、複数回更新されることが予想されます。 特に、スキーマの一番上にある膨大な数の日付フィールドに注目してください。 このテーブルに初めて行が作成されたとき、これらの日付の大部分は最初は空白ですが、時間が経つにつれて埋まっていきます。 (注意: Kimball はここで、組み込みの SQL 日付データ型ではなく、日付ディメンション テーブルを使用しています。)
また、リストの一番下にあるフィールドも重要です。 これらの各フィールドは遅延指標、つまり、2 つの日付の差を測定します。 例えば、Order to Manufacturing Release LagはOrder DateからRelease to Manufacturing Dateまでにかかった時間、Inventory to Shipment LagはFinished Inventory Placement DateからActual Ship Dateまでにかかった時間、といったようにです。 時間が経つにつれて、これらの日付はERPシステムやデータ入力担当者によって入力されることになる。 したがって、各フィールドが入力されると、各特定の注文の遅延時間が計算されます。
このようなテーブルが、時間ベースの競争環境内で動作する企業にとっていかに有用であるかがわかると思います。 単一のテーブルを使用して、経営陣は、生産における遅延時間が時間の経過とともに増加しているか減少しているかを確認することができます。 このようなビジネスインテリジェンスを利用して、生産プロセスで最も問題があるのはどのステップかを判断することができます。
補足: これらのアイデアは、「リーン」という用語の下でソフトウェアの世界に適応されています。
なぜ変わらないのか
3 種類のファクト タブが 1996 年に初めて明確にされてから、実質的に変わっていないのは、Kimball 氏と彼の仲間の証しです。 その答えは、スター スキーマがビジネスに関する基本的な何かを捉えているという事実にあると思います。 トランザクションを介して、照合された期間、そして、時間ベースの競争に精通しているビジネスでは、価値提供システムの各ステップ間のラグタイムを測定することによってです。 2015 年のブログ投稿で、彼は次のように書いています。
論理モデルと物理モデルに関する宗教的な議論にとらわれるのではなく、次元モデルは実際にはデータ ウェアハウスのアプリケーション プログラミング インターフェイス (API) であることを単純に認識すべきなのです。 この API のパワーは、ユーザーと BI アプリケーションの両方、すべてのオブザーバーによって見られる、一貫性のある統一されたインターフェイスにあります。 私たちは、ビットがどこに格納されているか、または API 要求が開始されたときにどのように配信されるかは重要ではないことを理解します。 このことは明らかです。
同じ投稿で、Kimball 氏はさらに、列指向のデータ ウェアハウスなどの最近のイノベーションでさえも、この事実を変えてはいない、彼が話す企業の大半は、最終的に依然としてディメンション モデル構造で終わると主張しています。 データウェアハウスツールキットには、「テーブルあたりのファクトの数を制限する」、「データモデリング戦略をミーティングに参加するすべての関係者とともに計画する」といった古風な言及が散見されます。
最大の変化は、現在のテクノロジーによって、「素朴なファクト テーブル」から「キンブル スタイルの次元モデル」へと移行するスピードが速くなっていることです。 この方法は、以前このブログで説明した多くの技術的変化 (特に、「OLAP キューブの台頭と衰退」に関する投稿) によって可能になりましたが、ファクト テーブルの使用に対する実際の影響は次のとおりです。 これが理想的な状況であるとは言いませんが、非常に受け入れやすい妥協点であるというだけです。 Kimball氏の時代とは異なり、今日のデータ人材は法外に高価であり、ストレージと計算時間は安価です。 実際、ソースシステムから直接取り込んだ100以上のフィールドを持つファクトテーブルがいくつかあります。 私たちの哲学的なスタンスは、「複雑なレポート作成が必要な場合は、時間をかけてデータを適切にモデル化する価値がある」というものです。 しかし、必要なレポートが単純な場合は、利用可能な計算能力を活用し、ファクト テーブルをそのままにしておきます。
定期的なスナップショット ファクト テーブル – これを避けることができるのは驚くべきことです。 最近の MPP カラムナー・データウェアハウスは非常に強力なので、それほど定期的に使用されないレポートについては、定期的なスナップショット・ファクト・テーブルを作成することはありません。 生のトランザクションデータからレポートを生成するためにかかるクエリ実行時間や追加コストは、特にレポートが週に1回程度しか必要ない(または定期的に調査できるようにする)ことが分かっている場合は、全く問題ありません。 他のデータセットについては、Kimball の元の推奨に従って、定期的にスナップショット テーブルを生成します。 スナップショット テーブルの蓄積 – これは Kimball の時代とほとんど変わりません。 しかし、Kimball 氏自身が言っているように、スナップショット テーブルを蓄積することは実際にはまれです。 ここで重要なのは、私たちがモデリングは重要だと考えていることです。 違いは、私たちのデータ分析の実践により、将来いつでもモデリング決定を見直すことができるという点です。 これはどのように行うのでしょうか。 まず、生のトランザクションデータを変換する前にデータウェアハウスにロードします。 これは、「ETL」に対して「ELT」と呼ばれています。 データ モデリング レイヤーを使用して、データ ウェアハウス内ですべての変換を行うため、必要に応じて、選択を再検討し、データを修正することができます。 また、データ モデリングにかかる労力を低く抑えることができます。