La modellazione dimensionale dei dati di Ralph Kimball definisce tre tipi di tabelle di fatti. Queste sono:
- Tabelle di transazione.
- Tabelle snapshot periodiche, e
- Tabelle snapshot accumulative.
In questo post, esamineremo ognuno di questi tipi di tabelle di fatti, e poi rifletteremo su come non sono cambiate negli anni dall’ultimo aggiornamento di Kimball del Data Warehouse Toolkit. Se avete familiarità con queste tre categorie di tabelle di fatti, saltate avanti fino all’analisi alla fine; se non ne avete, considerate questo un breve viaggio attraverso uno dei componenti di base della modellazione dei dati in stile Kimball.
Due brevi note prima di iniziare: primo, questo pezzo presuppone familiarità con lo star schema. Leggete questo se avete bisogno di un’introduzione – io assumo che comprendiate le tabelle dei fatti e delle dimensioni come minimo. In secondo luogo, noterò che Kimball riconosce un quarto tipo di tabella dei fatti – la tabella dei fatti timepan – ma è usata solo per circostanze speciali. La lasceremo fuori dalla nostra discussione qui.
Tabelle di fatti di transazione
Le tabelle di fatti di transazione sono facili da capire: un cliente o un processo di business fa qualcosa; tu vuoi catturare l’occorrenza di quella cosa, e così registri una transazione nel tuo data warehouse e sei a posto.
Questo è illustrato meglio con un semplice esempio. Immaginiamo che stiate gestendo un negozio di alimentari, e che abbiate un sistema elettronico di punti vendita (POS) che registra ogni vendita effettuata.
In un tipico schema a stella in stile Kimball, la tabella dei fatti che è al centro del vostro schema consisterebbe in dati di transazioni di ordini. Queste sono principalmente misure numeriche come il totale dell’ordine, gli importi delle voci, il costo delle merci vendute, gli importi degli sconti applicati, e così via.
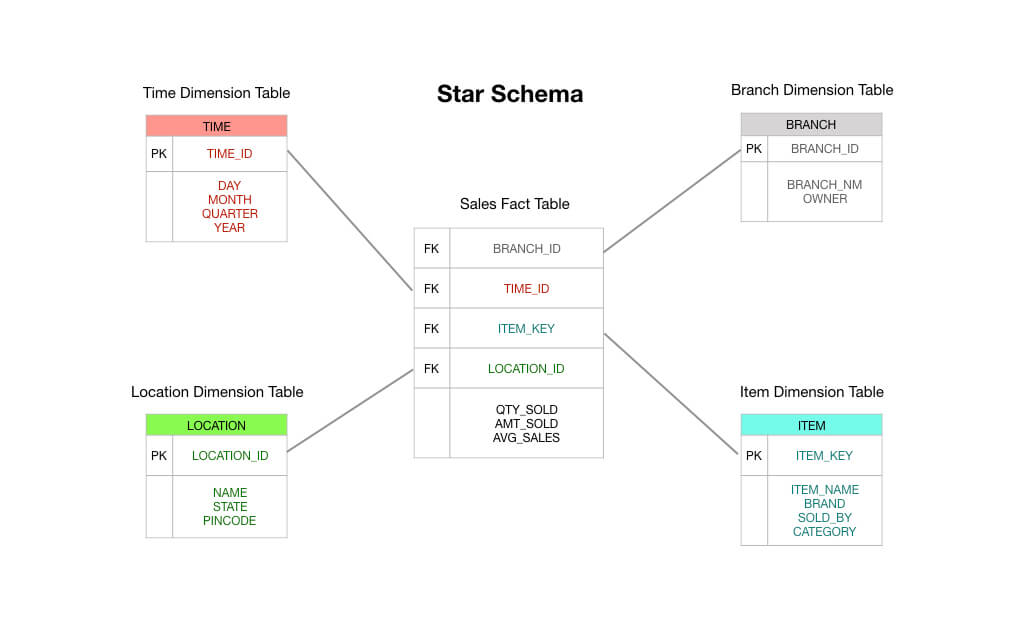
E così potete vedere che una tabella dei fatti delle transazioni è esattamente come dice l’etichetta: ricevete una transazione, registrate la transazione nella vostra tabella dei fatti, e questa diventa la base del vostro reporting. In molti modi, una tabella dei fatti delle transazioni è il tipo predefinito di tabella dei fatti a cui siamo abituati a pensare.
Tabelle Snapshot periodiche
Le tabelle dei fatti snapshot periodiche sono un’estensione logica delle semplici tabelle dei fatti che abbiamo appena trattato. Una riga in una tabella dei fatti istantanea periodica cattura una sorta di dati periodici – per esempio, un’istantanea giornaliera delle metriche finanziarie, o forse un riassunto settimanale dei crediti, o un conteggio mensile dei numeri di inventario.
In altre parole, la ‘grana’ o ‘livello di risoluzione’ è il periodo, non la singola transazione. Si noti che se non si verificano transazioni durante un certo periodo, una nuova riga deve essere inserita nella tabella delle istantanee periodiche, anche se ogni fatto che viene salvato è un null!
Le tabelle delle istantanee periodiche tendono a contenere un numero incredibilmente grande di campi. Questo perché qualsiasi metrica ragionevolmente interessante può essere infilata nella tabella dei periodi. Si può immaginare uno scenario in cui si inizia con le vendite aggregate, le entrate e il costo dei beni venduti su un periodo settimanale, ma col passare del tempo, la direzione chiede di aggiungere altri fatti come i livelli di inventario, le metriche dei conti passivi e altre misure interessanti.
Perché le tabelle istantanee periodiche sono utili? Beh, questo è abbastanza semplice da immaginare. Se si vuole avere una visione d’insieme delle linee di tendenza negli indicatori di performance chiave del proprio business, aiuta l’interrogazione di una tabella periodica di fatti.
Tabelle di istantanee accumulanti
A differenza delle tabelle di istantanee periodiche, le tabelle di istantanee accumulanti sono un po’ più difficili da spiegare. Per capire perché Kimball e i suoi colleghi sono arrivati a questo approccio, aiuta a capire un po’ il tipo di domande che venivano poste al business negli anni ’90, cioè quando il Data Warehouse Toolkit è stato scritto per la prima volta.
Alla fine degli anni ’80, i produttori giapponesi hanno iniziato a battere le loro controparti americane in tutti i modi sgradevoli ma non ovvi. Il principale di questi era l’attenzione alla velocità di esecuzione.
La produzione può essere vista come una serie di passi. Si prende la materia prima da un lato della fabbrica e la si trasforma in auto, telefoni e widget dall’altro lato. Ogni passo del processo produttivo può essere misurato – quanto tempo ci vuole per trasformare i blocchi di acciaio in pellet di acciaio, per esempio? Quanto tempo aspettano nell’inventario della fabbrica? E da lì, quanto tempo prima che i pellet siano fabbricati in parti di automobili? Quanto tempo prima che vengano usati nelle automobili vere e proprie?
Alla fine degli anni ’70, le aziende giapponesi hanno cominciato a rendersi conto che questa visione della creazione di valore in “serie di passi” poteva portare a un serio vantaggio competitivo se avessero ridotto il tempo di ritardo tra ogni passo. Più concretamente: se potessero ridurre il numero di fasi di produzione di ogni articolo e se potessero ridurre il tempo trascorso all’interno di ogni fase, i produttori giapponesi impararono che potevano ridurre lo spreco di materiale, abbassare i tassi di difettosità e tagliare i tempi di consegna, e allo stesso tempo aumentare la produttività dei lavoratori, aumentare il volume di produzione, espandere la varietà dei prodotti e tagliare i prezzi – tutto allo stesso tempo.
Per quando arrivarono gli anni ’90, le aziende occidentali avevano capito. Un certo numero di consulenti di gestione – primo fra tutti George Stalk Jr del Boston Consulting Group – iniziò a difendere il tempo di esecuzione come fonte di vantaggio competitivo. Questi consulenti istruivano le aziende a registrare il tempo trascorso in ogni fase del processo di produzione. Quando arrivava un ordine, quanto tempo aspettava per essere elaborato? Dopo essere stato elaborato, quanto tempo prima che l’ordine fosse inviato alla fabbrica? In fabbrica, quanto tempo prima che il prodotto fosse completato? E poi quanto tempo ha aspettato nell’inventario? E infine, quanto tempo è passato prima che il cliente ricevesse il prodotto e ne ricavasse valore?
Le aziende degli anni ’90 erano quindi costrette a misurare i tempi di ritardo in tutto il loro processo di consegna aziendale. Erano costrette a farlo perché i concorrenti giapponesi stavano facendo breccia in molti settori precedentemente dominati dalle aziende occidentali – in alcuni casi, causando fallimenti e interrompendo intere catene di fornitura. Era in questo ambiente che Kimball stava lavorando.
La tabella dei fatti dell’istantanea accumulata è quindi un metodo per misurare la velocità all’interno del processo di business. Prendiamo, per esempio, questa pipeline aziendale, che Kimball ha presentato nella seconda edizione di The Data Warehouse Toolkit:
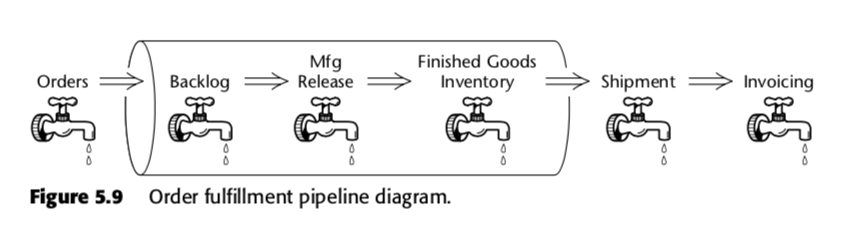
Per questo processo, Kimball ha proposto la seguente tabella di snapshot accumulata:
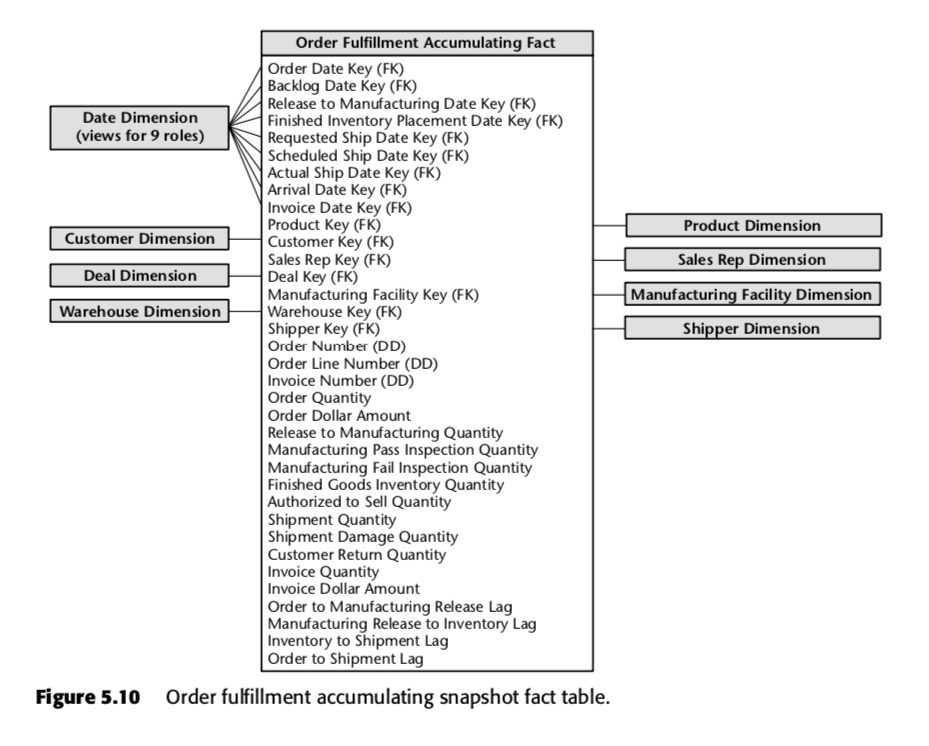
Ogni riga di questa tabella rappresenta un ordine o un lotto di ordini. Ci si aspetta che ognuna di queste righe venga aggiornata più volte mentre procede attraverso la pipeline di evasione degli ordini. Notate in particolare l’enorme numero di campi data in cima allo schema. Quando una riga viene creata per la prima volta in questa tabella, la maggior parte di queste date inizieranno come nulle, ma alla fine saranno riempite con il passare del tempo. (Nota: Kimball usa una tabella di dimensione della data qui, invece del tipo di dati SQL integrato della data, perché questo è il Kimball Way ™ – ti permette di catturare più informazioni sulle date che solo i tipi di data ingenui. Ognuno di essi misura un indicatore di ritardo – cioè la differenza tra due date. Così, per esempio, Order to Manufacturing Release Lag è il tempo impiegato da Order Date a Release to Manufacturing Date; Inventory to Shipment Lag è il tempo impiegato da Finished Inventory Placement Date a Actual Ship Date, e così via. Con il passare del tempo, ognuna di queste date sarà compilata da un sistema ERP o forse da un gruppetto di inserimento dati. I tempi di ritardo per ogni particolare ordine verrebbero così calcolati man mano che ogni campo viene compilato.
Si può vedere come una tale tabella sarebbe utile per un’azienda che opera in un ambiente competitivo basato sul tempo. Usando un’unica tabella, la direzione sarebbe in grado di vedere se i tempi di ritardo nella sua produzione stanno aumentando o diminuendo nel tempo. Possono usare questa business intelligence per determinare quali passi sono più problematici nel loro processo di produzione. E possono agire sulle parti che li preoccupano di più.
Nota a margine: queste idee sono state adattate al mondo del software sotto la terminologia ‘lean’; per maggiori informazioni sulla misurazione della produzione nelle aziende tecnologiche, controlla i nostri post sul libro Accelerate qui e qui.
Perché non sono cambiate?
È un testamento di Kimball e dei suoi colleghi che i tre tipi di tabelle dei fatti non sono cambiati materialmente da quando sono stati articolati per la prima volta nel 1996.
Perché è così? La risposta, credo, sta nel fatto che lo schema a stella cattura qualcosa di fondamentale sul business. Se modellate i vostri dati per farli combaciare con i vostri processi di business, in pratica catturerete i dati di fatto in uno dei tre modi seguenti: attraverso le transazioni, con i periodi raccolti, e – se la vostra azienda è abbastanza esperta sulla concorrenza basata sul tempo – misurando i tempi di ritardo tra ogni passo del vostro sistema di consegna del valore.
Kimball stesso dice qualcosa di simile. In un post sul blog del 2015, scrive:
Piuttosto che rimanere bloccati su argomenti religiosi sui modelli logici rispetto a quelli fisici, dovremmo semplicemente riconoscere che un modello dimensionale è in realtà un’interfaccia di programmazione delle applicazioni (API) del data warehouse. Il potere di questa API sta nell’interfaccia coerente e uniforme vista da tutti gli osservatori, sia gli utenti che le applicazioni di BI. Vediamo che non importa dove sono memorizzati i bit o come vengono consegnati quando viene lanciata una richiesta API.
Lo schema a stella è collaudato nel tempo. Questo è ovvio.
Nello stesso post, Kimball continua a sostenere che anche le recenti innovazioni come il data warehouse a colonne non hanno cambiato questo fatto; la maggior parte delle aziende con cui parla si ritrova ancora con una struttura di modelli dimensionali alla fine della giornata.
Ma le cose sono cambiate. In tutto il Data Warehouse Toolkit ci sono menzioni pittoresche di ‘limitare il numero di fatti per tabella’, e ‘pianificare la strategia di modellazione dei dati con tutti gli stakeholder del dominio presenti alla riunione’. Questi non riflettono ciò che stiamo vedendo nella pratica nella nostra azienda e nei dipartimenti dati dei nostri clienti.
Il più grande cambiamento è la velocità con cui le tecnologie attuali ci permettono di passare dalla “tabella dei fatti ingenua” al “modello dimensionale stile Kimball” – che ci permette di saltare la pratica della modellazione iniziale e scegliere invece di modellare il meno possibile. Questa pratica è resa possibile da una serie di cambiamenti tecnologici che abbiamo già discusso su questo blog (in particolare, nel nostro post su The Rise and Fall of the OLAP Cube), ma le implicazioni pratiche sul nostro uso delle tabelle dei fatti sono le seguenti:
- Tabelle dei fatti di transazione – siamo perfettamente felici di avere tabelle dei fatti grasse, con decine se non centinaia di fatti per riga! Questo non vuol dire che questa sia una situazione ideale, ma solo che è un compromesso molto accettabile. A differenza dei tempi di Kimball, il talento dei dati oggi è proibitivo; lo storage e il tempo di calcolo sono economici. Quindi siamo perfettamente d’accordo nel lasciare certe tabelle di fatti così come sono – in effetti, ne abbiamo diverse con più di 100 campi, inserite direttamente dai nostri sistemi di origine! La nostra posizione filosofica è: se abbiamo esigenze di reporting complesse, allora vale la pena impiegare il tempo e modellare i dati correttamente. Ma se i rapporti di cui abbiamo bisogno sono semplici, allora approfittiamo della potenza di calcolo a nostra disposizione e lasciamo le tabelle dei fatti così come sono.
- Tabelle dei fatti a scatto periodico – è sorprendente quanto siamo in grado di evitare di fare questo. Poiché i moderni magazzini di dati colonnari MPP sono così potenti, non creiamo tabelle dei fatti snapshot periodiche per i rapporti che non sono usati regolarmente. Il tempo di esecuzione delle query e il costo aggiuntivo necessario per generare i report dai dati grezzi delle transazioni è perfettamente accettabile, specialmente se sappiamo che il report è necessario solo una volta alla settimana o giù di lì (o reso disponibile per l’esplorazione periodica). Per altri insiemi di dati, generiamo periodicamente tabelle di snapshot come da raccomandazioni originali di Kimball.
- Accumulare tabelle di snapshot – Questo è quasi invariato rispetto ai tempi di Kimball. Ma – come dice lo stesso Kimball – le tabelle di snapshot accumulate sono rare nella pratica. Quindi non ci pensiamo così tanto come potrebbe fare un’azienda più orientata al tempo.
E’ importante notare qui che pensiamo che la modellazione sia importante. La differenza è che la nostra pratica di analisi dei dati ci permette di rivedere le nostre decisioni di modellazione in qualsiasi momento nel futuro. Come lo facciamo? Bene, carichiamo i nostri dati transazionali grezzi nel nostro data warehouse prima di trasformarli. Questo è noto come ‘ELT’ in opposizione a ‘ETL’. Poiché facciamo tutte le nostre trasformazioni all’interno del data warehouse, usando un livello di modellazione dei dati, siamo in grado di rivedere le nostre scelte e rimodellare i nostri dati in caso di necessità.
Questo ci permette di concentrarci prima sulla fornitura di valore di business. Mantiene basso il lavoro di modellazione dei dati.