Ralph Kimballs dimensionale Datenmodellierung definiert drei Arten von Faktentabellen. Diese sind:
- Transaktionsfaktentabellen.
- Periodische Snapshot-Tabellen und
- Akkumulierende Snapshot-Tabellen.
In diesem Beitrag werden wir jede dieser Arten von Faktentabellen durchgehen und dann darüber nachdenken, wie sie sich in den Jahren seit der letzten Aktualisierung des Data Warehouse Toolkit durch Kimball nicht verändert haben. Wenn Sie mit diesen drei Kategorien von Faktentabellen vertraut sind, können Sie zur Analyse am Ende springen; wenn nicht, betrachten Sie dies als einen kurzen Streifzug durch eine der grundlegenden Komponenten der Datenmodellierung im Kimball-Stil.
Zwei kurze Hinweise, bevor wir beginnen: Erstens setzt dieser Beitrag Vertrautheit mit dem Sternschema voraus. Ich gehe davon aus, dass Sie zumindest mit Fakten- und Dimensionstabellen vertraut sind. Zweitens möchte ich anmerken, dass Kimball eine vierte Art von Faktentabelle kennt – die Zeitspannenfaktentabelle -, die aber nur unter besonderen Umständen verwendet wird. Wir lassen sie hier außen vor.
Transaktionsfaktentabellen
Transaktionsfaktentabellen sind leicht zu verstehen: Ein Kunde oder ein Geschäftsprozess tut etwas; Sie wollen das Auftreten dieses Vorgangs erfassen, also zeichnen Sie eine Transaktion in Ihrem Data Warehouse auf, und schon sind Sie fertig.
Das lässt sich am besten anhand eines einfachen Beispiels veranschaulichen. Stellen Sie sich vor, Sie betreiben einen Lebensmittelladen und haben ein elektronisches Kassensystem, das jeden Verkauf aufzeichnet.
In einem typischen Kimball-Sternschema würde die Faktentabelle, die im Zentrum Ihres Schemas steht, aus Daten über Bestellvorgänge bestehen. Dabei handelt es sich in erster Linie um numerische Größen wie die Auftragssumme, die Beträge der Einzelposten, die Kosten der verkauften Waren, die angewandten Rabatte usw.
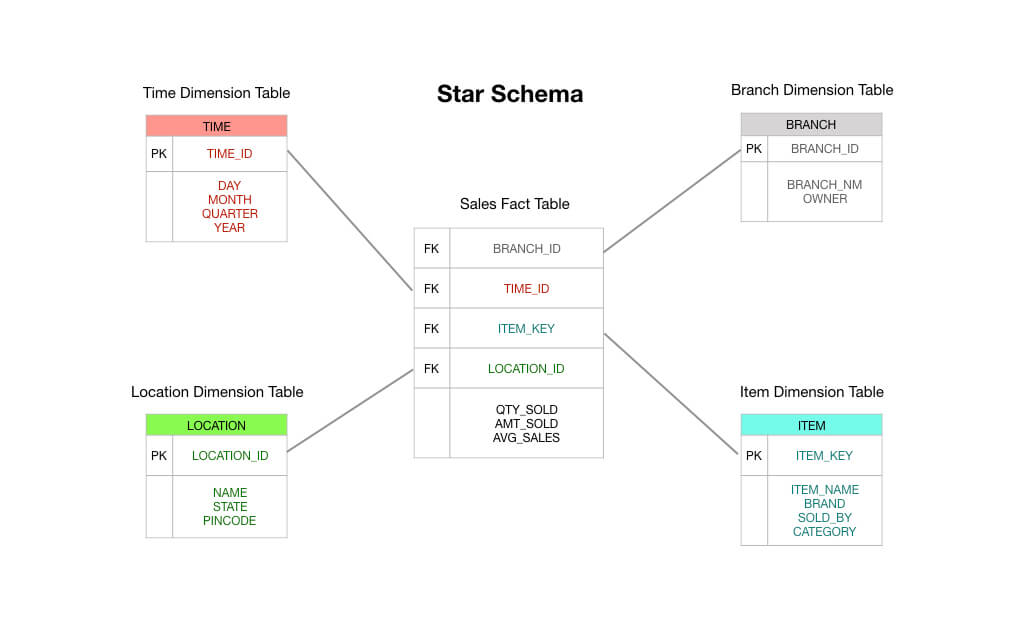
Sie sehen also, dass eine Transaktionsfaktentabelle genau das ist, was auf der Verpackung steht: Sie erhalten eine Transaktion, Sie zeichnen die Transaktion in Ihrer Faktentabelle auf, und diese wird zur Grundlage Ihrer Berichterstattung. In vielerlei Hinsicht ist eine Transaktionsfaktentabelle der Standardtyp einer Faktentabelle, an den wir gewohnt sind zu denken.
Periodische Snapshot-Tabellen
Periodische Snapshot-Faktentabellen sind eine logische Erweiterung der einfachen Vanilla-Faktentabellen, die wir gerade oben behandelt haben. Eine Zeile in einer periodischen Snapshot-Faktentabelle erfasst irgendeine Art von periodischen Daten – zum Beispiel eine tägliche Momentaufnahme der Finanzkennzahlen oder vielleicht eine wöchentliche Zusammenfassung der Außenstände oder eine monatliche Auflistung der Bestandszahlen.
Mit anderen Worten: Die „Körnung“ oder „Auflösungsebene“ ist die Periode, nicht die einzelne Transaktion. Beachten Sie, dass eine neue Zeile in die periodische Snapshot-Tabelle eingefügt werden muss, wenn während eines bestimmten Zeitraums keine Transaktionen stattfinden, selbst wenn jeder gespeicherte Fakt eine Null ist!
Periodische Snapshot-Tabellen neigen dazu, eine unglaublich große Anzahl von Feldern zu enthalten. Das liegt daran, dass jede halbwegs interessante Metrik in die Perioden-Tabelle geschoben werden kann. Sie können sich ein Szenario vorstellen, in dem Sie mit aggregierten Umsätzen, Erträgen und Selbstkosten für eine wöchentliche Periode beginnen, aber im Laufe der Zeit bittet die Geschäftsleitung Sie, weitere Fakten wie Lagerbestände, Kreditorenmetriken und andere interessante Messungen hinzuzufügen.
Warum sind periodische Snapshot-Tabellen nützlich? Nun, das kann man sich recht einfach vorstellen. Wenn Sie sich einen Überblick über die Trendlinien der wichtigsten Leistungsindikatoren in Ihrem Unternehmen verschaffen wollen, ist es hilfreich, eine periodische Faktentabelle abzufragen.
Akkumulierende Snapshot-Tabellen
Im Gegensatz zu periodischen Snapshot-Tabellen sind akkumulierende Snapshot-Tabellen etwas schwieriger zu erklären. Um zu verstehen, warum Kimball und seine Kollegen diesen Ansatz entwickelt haben, ist es hilfreich, ein wenig über die Art der Fragen zu wissen, die in den 90er Jahren, als das Data Warehouse Toolkit zum ersten Mal geschrieben wurde, an die Unternehmen gestellt wurden.
In den späten 80er Jahren begannen japanische Hersteller, ihre amerikanischen Konkurrenten auf alle möglichen unangenehmen, aber nicht offensichtlichen Arten zu schlagen. Der Schwerpunkt lag dabei auf der Ausführungsgeschwindigkeit.
Die Fertigung kann als eine Reihe von Schritten betrachtet werden. Am einen Ende der Fabrik wird Rohmaterial entnommen, das am anderen Ende in Autos, Telefone und Widgets verwandelt wird. Jeder Schritt des Herstellungsprozesses kann gemessen werden – wie lange dauert es zum Beispiel, bis aus Stahlblöcken Stahlpellets werden? Wie lange warten sie im Lager der Fabrik? Und wie lange dauert es dann, bis aus den Pellets Autoteile hergestellt werden? Wie lange dauert es, bis sie in Autos verbaut werden?
In den späten 70er Jahren begannen japanische Unternehmen zu erkennen, dass diese „Reihe von Schritten“ der Wertschöpfung zu einem ernsthaften Wettbewerbsvorteil führen könnte, wenn sie die Zeit zwischen den einzelnen Schritten verkürzen würden. Konkreter ausgedrückt: Wenn sie die Anzahl der Schritte, die für die Herstellung eines Artikels erforderlich sind, und die Dauer der einzelnen Schritte reduzieren konnten, lernten die japanischen Hersteller, dass sie die Materialverschwendung verringern, die Fehlerquote senken und die Lieferzeiten verkürzen konnten, während sie gleichzeitig die Produktivität der Mitarbeiter steigerten, das Produktionsvolumen erhöhten, die Produktvielfalt ausweiteten und die Preise senkten – und das alles zur gleichen Zeit.
Als die 90er Jahre kamen, hatten westliche Unternehmen dies erkannt. Eine Reihe von Unternehmensberatern – allen voran George Stalk Jr. von der Boston Consulting Group – begannen, das Ausführungstempo als Quelle für Wettbewerbsvorteile zu propagieren. Diese Berater wiesen die Unternehmen an, den Zeitaufwand für jeden Schritt des Produktionsprozesses zu erfassen. Wie lange dauerte es, bis ein Auftrag bearbeitet wurde? Wie lange dauerte es nach der Bearbeitung, bis der Auftrag an die Fabrik geschickt wurde? Wie lange dauerte es in der Fabrik, bis das Produkt fertiggestellt war? Und wie lange wartete es dann im Lager? Und schließlich, wie lange dauerte es, bis der Kunde das Produkt erhielt und einen Nutzen daraus zog?
Die Unternehmen in den 90er Jahren waren also gezwungen, die Verzögerungszeiten im gesamten Lieferprozess ihres Unternehmens zu messen. Sie waren dazu gezwungen, weil japanische Konkurrenten in viele Branchen vordrangen, die zuvor von westlichen Unternehmen beherrscht wurden – in einigen Fällen führten sie zu Konkursen und unterbrachen ganze Lieferketten. In diesem Umfeld arbeitete Kimball.
Die akkumulierende Snapshot-Faktentabelle ist also eine Methode zur Messung der Geschwindigkeit innerhalb des Geschäftsprozesses. Nehmen wir zum Beispiel diese Geschäftspipeline, die Kimball in der zweiten Ausgabe von The Data Warehouse Toolkit vorstellte:
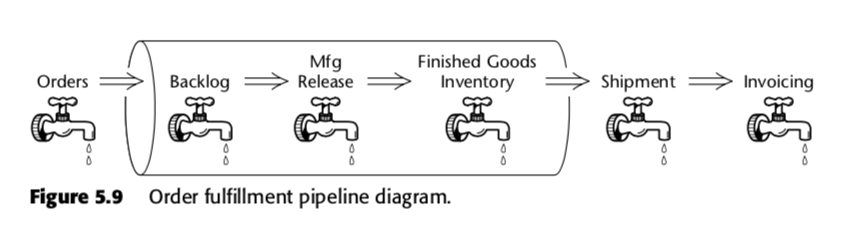
Für diesen Prozess schlug Kimball die folgende akkumulierende Snapshot-Tabelle vor:
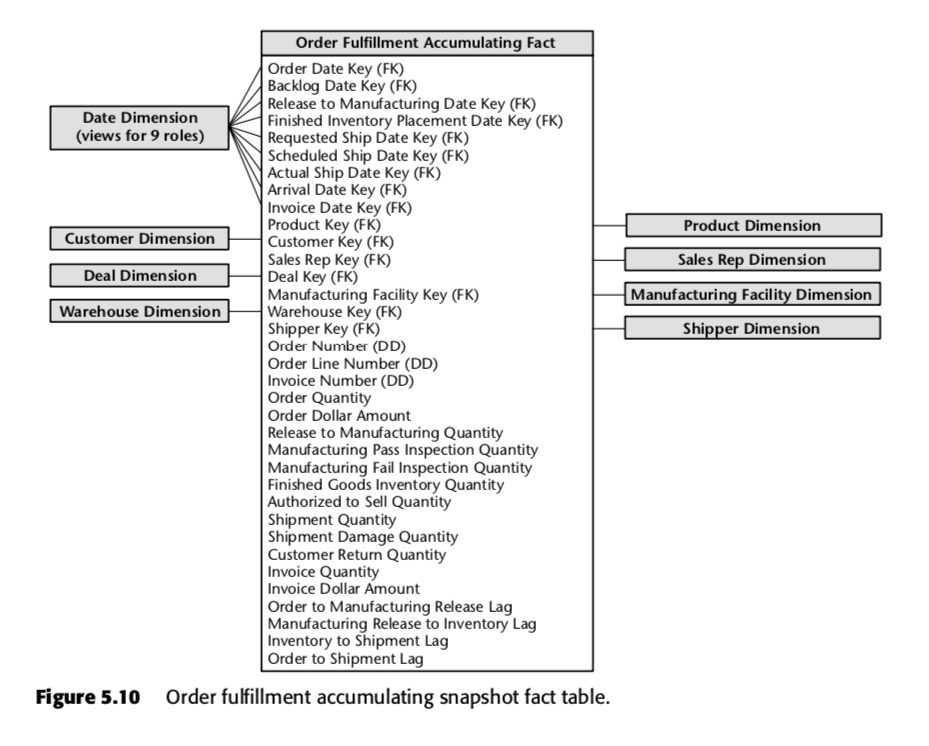
Jede Zeile in dieser Tabelle repräsentiert eine Bestellung oder eine Reihe von Bestellungen. Es ist davon auszugehen, dass jede dieser Zeilen mehrfach aktualisiert wird, während sie die Auftragserfüllungspipeline durchläuft. Beachten Sie insbesondere die große Anzahl von Datumsfeldern am Anfang des Schemas. Wenn eine Zeile in dieser Tabelle zum ersten Mal erstellt wird, sind die meisten dieser Datumsangaben zunächst Nullen, werden aber im Laufe der Zeit aufgefüllt. (Hinweis: Kimball verwendet hier eine Datumsdimensionstabelle anstelle des eingebauten SQL-Datumsdatentyps, weil dies der Kimball Way ™ ist – es ermöglicht Ihnen, mehr Informationen über Daten zu erfassen als nur die naiven Datumstypen.)
Ebenfalls wichtig sind die Felder am Ende der Liste. Jedes von ihnen misst einen Verzögerungsindikator, d. h. die Differenz zwischen zwei Daten. So ist zum Beispiel Order to Manufacturing Release Lag die Zeit von Order Date bis Release to Manufacturing Date; Inventory to Shipment Lag ist die Zeit von Finished Inventory Placement Date bis Actual Ship Date und so weiter. Im Laufe der Zeit wird jedes dieser Daten von einem ERP-System oder vielleicht von einem Datenerfasser ausgefüllt. Die Verzögerungszeiten für jeden einzelnen Auftrag werden also berechnet, während jedes Feld ausgefüllt wird.
Sie können sich vorstellen, wie nützlich eine solche Tabelle für ein Unternehmen wäre, das in einem zeitbasierten Wettbewerbsumfeld tätig ist. Anhand einer einzigen Tabelle könnte die Geschäftsleitung feststellen, ob die Verzögerungszeiten in ihrer Produktion im Laufe der Zeit zunehmen oder abnehmen. Mit Hilfe dieser Business Intelligence können sie feststellen, welche Schritte in ihrem Produktionsprozess am problematischsten sind. Und sie können Maßnahmen für die Teile ergreifen, die ihnen am meisten Sorgen bereiten.
Anmerkung am Rande: Diese Ideen wurden unter dem Begriff „Lean“ an die Softwarewelt angepasst; weitere Informationen über die Messung der Produktion in Technologieunternehmen finden Sie in unseren Beiträgen über das Buch Accelerate hier und hier.
Warum haben sie sich nicht verändert?
Es ist ein Zeugnis für Kimball und seine Kollegen, dass sich die drei Arten von Faktentabellen nicht wesentlich verändert haben, seit sie 1996 zum ersten Mal formuliert wurden.
Warum ist das so? Die Antwort liegt meines Erachtens in der Tatsache, dass das Sternschema etwas Grundlegendes über die Wirtschaft aussagt. Wenn Sie Ihre Daten so modellieren, dass sie mit Ihren Geschäftsprozessen übereinstimmen, werden Sie Faktendaten auf eine von drei Arten erfassen: über Transaktionen, mit kollationierten Zeiträumen und – wenn Ihr Unternehmen den zeitbasierten Wettbewerb beherrscht – durch Messung der Verzögerungszeiten zwischen den einzelnen Schritten Ihres Wertschöpfungssystems.
Kimball selbst sagt etwas Ähnliches. In einem Blogbeitrag aus dem Jahr 2015 schreibt er:
Anstatt sich in religiösen Argumenten über logische versus physische Modelle zu verlieren, sollten wir einfach erkennen, dass ein Dimensionsmodell eigentlich eine Data-Warehouse-Anwendungsprogrammierschnittstelle (API) ist. Die Stärke dieser API liegt in der konsistenten und einheitlichen Schnittstelle, die von allen Beobachtern, sowohl Benutzern als auch BI-Anwendungen, gesehen wird. Wir sehen, dass es keine Rolle spielt, wo die Bits gespeichert sind oder wie sie geliefert werden, wenn eine API-Anfrage gestartet wird.
Das Sternschema ist erprobt. So viel ist klar.
Im gleichen Beitrag argumentiert Kimball dann weiter, dass selbst jüngste Innovationen wie das spaltenbasierte Data Warehouse an dieser Tatsache nichts geändert haben; die meisten Unternehmen, mit denen er spricht, haben am Ende des Tages immer noch eine dimensionale Modellstruktur.
Aber die Dinge haben sich geändert. Im Data Warehouse Toolkit wird immer wieder erwähnt, dass „die Anzahl der Fakten pro Tabelle begrenzt werden muss“ und dass „die Datenmodellierungsstrategie unter Beteiligung aller Interessengruppen des Bereichs geplant werden muss“. Dies spiegelt nicht das wider, was wir in der Praxis in unserem Unternehmen und in den Datenabteilungen unserer Kunden sehen.
Die größte Veränderung ist die Geschwindigkeit, mit der die aktuellen Technologien es uns ermöglichen, von der „naiven Faktentabelle“ zum „dimensionalen Modell im Kimball-Stil“ überzugehen – was es uns ermöglicht, die Praxis der Up-Front-Modellierung zu überspringen und stattdessen so wenig wie nötig zu modellieren. Diese Praxis wird durch eine Reihe technologischer Veränderungen ermöglicht, die wir in diesem Blog bereits erörtert haben (vor allem in unserem Beitrag über The Rise and Fall of the OLAP Cube), aber die praktischen Auswirkungen auf unsere Verwendung von Faktentabellen sind wie folgt:
- Transaktionsfaktentabellen – wir sind vollkommen zufrieden damit, fette Faktentabellen zu haben, mit Dutzenden, wenn nicht Hunderten von Fakten pro Zeile! Das soll nicht heißen, dass dies eine ideale Situation ist, sondern lediglich, dass es ein sehr akzeptabler Kompromiss ist. Anders als zu Kimballs Zeiten sind Datentalente heute unerschwinglich teuer; Speicher- und Rechenzeit sind billig. Daher ist es für uns völlig in Ordnung, bestimmte Faktentabellen so zu belassen, wie sie sind – wir haben sogar einige mit mehr als 100 Feldern darin, die direkt aus unseren Quellsystemen importiert wurden! Unser philosophischer Standpunkt lautet: Wenn wir komplexe Berichtsanforderungen haben, dann lohnt es sich, die Zeit zu investieren und die Daten richtig zu modellieren. Wenn wir jedoch nur einfache Berichte benötigen, nutzen wir die uns zur Verfügung stehende Rechenleistung und belassen die Faktentabellen so, wie sie sind.
- Periodische Snapshot-Faktentabellen – es ist erstaunlich, wie sehr wir dies vermeiden können. Da moderne MPP-Spalten-Data-Warehouses so leistungsfähig sind, erstellen wir keine periodischen Snapshot-Faktentabellen für Berichte, die nicht so regelmäßig verwendet werden. Die Zeit für die Abfrageausführung und die zusätzlichen Kosten für die Erstellung von Berichten aus Transaktionsrohdaten sind durchaus akzeptabel, insbesondere wenn wir wissen, dass der Bericht nur etwa einmal pro Woche benötigt wird (oder für regelmäßige Untersuchungen zur Verfügung steht). Für andere Datensätze erstellen wir regelmäßige Snapshot-Tabellen gemäß Kimballs ursprünglichen Empfehlungen.
- Akkumulieren von Snapshot-Tabellen – Dies ist fast unverändert gegenüber Kimballs Zeit. Aber – wie Kimball selbst sagt – sind akkumulierende Snapshot-Tabellen in der Praxis selten. Wir machen uns also nicht so viele Gedanken darüber, wie es ein eher zeitorientiertes Unternehmen tun würde.
Es ist wichtig, hier festzuhalten, dass wir die Modellierung für wichtig halten. Der Unterschied besteht darin, dass unsere Praxis der Datenanalyse es uns ermöglicht, unsere Modellierungsentscheidungen jederzeit in der Zukunft zu revidieren. Wie machen wir das? Nun, wir laden unsere Transaktionsrohdaten in unser Data Warehouse, bevor wir sie transformieren. Dies wird als ELT“ im Gegensatz zu ETL“ bezeichnet. Da wir alle unsere Transformationen innerhalb des Data Warehouse unter Verwendung einer Datenmodellierungsschicht durchführen, können wir unsere Entscheidungen überprüfen und unsere Daten bei Bedarf umgestalten.
Dadurch können wir uns zunächst auf die Bereitstellung von Geschäftswerten konzentrieren. Es hält den Aufwand für die Datenmodellierung gering.