Descriptive Statistics
I denne vejledning bruger vi datasættet auto, der følger med Stata. For at indlæse denne datatype
sysuse auto, clearDatasættet auto har følgende variabler:
describe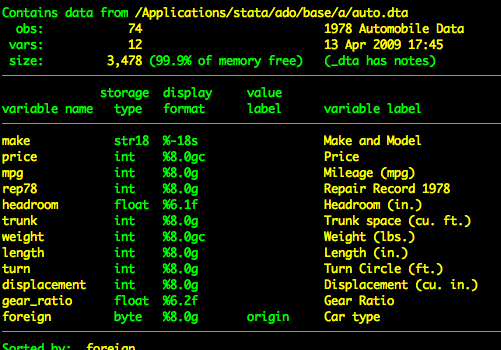
Sæt, at vi ønsker at få nogle sammenfattende statistikker for pris som f.eks. middelværdi, standardafvigelse og interval. Vi bruger kommandoen summarize.
summarize price
Nu skal vi tilføje indstillingen detail til summarize. Dette vil give os mange flere oplysninger, herunder medianen og andre percentiler.
summarize price, detail
Multiple Variables at Once
For at få beskrivelser for flere variabler på én gang skal du blot tilføje variabelnavnene efter summarize.
summarize price mpg
Tilføjelse af indstillingen detail.
summarize price mpg, detail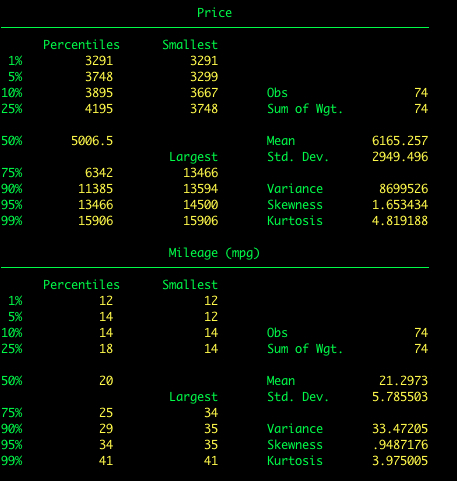
Brug ved behandling
Sæt, at vi ønsker at få den beskrivende statistik for pris efter biltype (udenlandsk vs. indenlandsk). Vi kan bruge det, der kaldes bybehandling.
by foreign: summarize price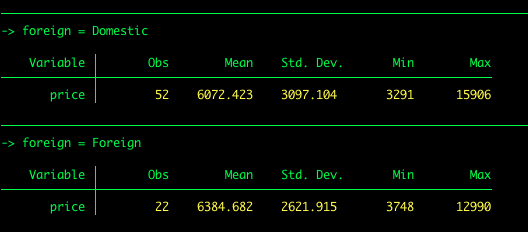
Når vi bruger by-kommandoen, skal variablen af interesse sorteres i datasættet. I det foregående eksempel er variablen “foreign” f.eks. allerede sorteret i vores datasæt. Hvis vi ville undersøge prisen efter mpg, ville vi skulle sortere miles per gallon. En måde at sortere data på er ved hjælp af en simpel sorteringskommando efterfulgt af variabelnavnet. Stata vil som standard sortere dataene i stigende rækkefølge.
sort mpgNår vi har sorteret dataene, kan vi derefter bruge standard by mpg: kommandoen. I by-behandling kan vi også sortere dataene og udføre by-kommandoen på samme tid ved hjælp af bysort-kommandoen:
bysort mpg: summarize priceDen by-kommando kan også bruges i andre kommandoer, f.eks. til at oprette grafik. Hvis vi f.eks. ønskede at undersøge histogrammer af mpg efter bilmærke, ville vi bruge by-kommandoen som en mulighed. Bilmærket behøver ikke at være sorteret for denne kommando.
histogram(mpg), by(foreign)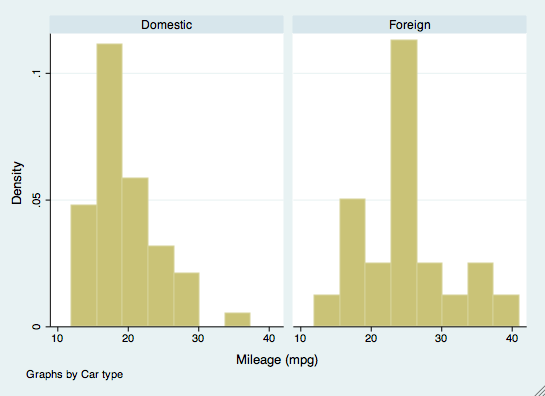
Ved anvendelse af if
Med by-erklæringen får vi beskrivelser for alle niveauer af by-variablen (dvs. både udenlandske og indenlandske). Lad os antage, at vi kun vil have beskrivelserne for ét niveau af by-variablen. Det kan vi bruge if-erklæringen til det. For udenlandske biler (dvs. foreign == 1):
summarize price if foreign == 1
For indenlandske biler (dvs, foreign == 0)
summarize price if foreign == 0
Denne tabel skal være en hjælp til at bestemme, hvordan man skal angive, hvilke niveauer af variablen man ønsker at anvende.
Symbol |
Betydning |
| == | er eller er lig med |
| != eller ~= | er ikke eller er ikke lig med |
| > | er større end |
| >= | er større end eller lig med |
| < | er mindre end |
| <= | er mindre end eller lig med |
| *Fra pg. 74 i A Gentle Introduction to Stata af Alan Acock | |
Bruger i
Den in kvalifikator angiver en bestemt delmængde af tilfælde baseret på deres rækkefølge i datasættet. Hvis vi f.eks. ønsker at undersøge mpg i de 10 billigste biler, skal vi bruge kommandoen in.
sort pricesummarize mpg in 1/10
Som et nyttigt tip til en af disse processer, hvis dine variabler er mærket (viser etiketten i stedet for den numeriske værdi), og du skal finde de numeriske værdier for at undersøge niveauerne for variablen, kan du bruge nolabel-indstillingen.
browse, nolabelDette vil vise dig de numeriske værdier for variablerne. Du kan også finde disse værdier ved at dobbeltklikke på dem i databrowseren.