Ralpha Kimballa wymiarowe modelowanie danych definiuje trzy typy tabel faktów. Są to:
- Transakcyjne tabele faktów.
- Okresowe tabele migawkowe i
- Kumulacyjne tabele migawkowe.
W tym poście przejdziemy przez każdy z tych typów tabel faktów, a następnie zastanowimy się, w jaki sposób nie zmieniły się one w ciągu lat, odkąd Kimball po raz ostatni zaktualizował Data Warehouse Toolkit. Jeśli znasz te trzy kategorie tabel faktów, przejdź do analizy na końcu; jeśli nie, potraktuj to jako zwięzłą wycieczkę po jednym z podstawowych elementów modelowania danych w stylu Kimballa.
Dwie krótkie uwagi zanim zaczniemy: po pierwsze, ten fragment zakłada znajomość schematu gwiazdy. Przeczytaj to, jeśli potrzebujesz elementarza – założę, że rozumiesz tabele faktów i wymiarów jako absolutne minimum. Po drugie, chciałbym zauważyć, że Kimball rozpoznaje czwarty typ tabeli faktów – tabelę faktów czasowych – ale jest ona używana tylko w szczególnych okolicznościach. Pozostawimy ją poza naszą dyskusją.
Transakcyjne tabele faktów
Transakcyjne tabele faktów są łatwe do zrozumienia: klient lub proces biznesowy robi jakąś rzecz; chcesz uchwycić wystąpienie tej rzeczy, a więc zapisujesz transakcję w swojej hurtowni danych i możesz działać.
Najlepiej zilustrować to prostym przykładem. Wyobraźmy sobie, że prowadzisz sklep spożywczy i masz elektroniczny system punktów sprzedaży (POS), który rejestruje każdą dokonaną sprzedaż.
W typowym schemacie gwiaździstym w stylu Kimballa, tabela faktów, która jest w centrum twojego schematu, składałaby się z danych transakcji zamówień. Są to przede wszystkim miary liczbowe, takie jak suma zamówienia, kwoty pozycji, koszt sprzedanych towarów, zastosowane kwoty rabatów i tak dalej.
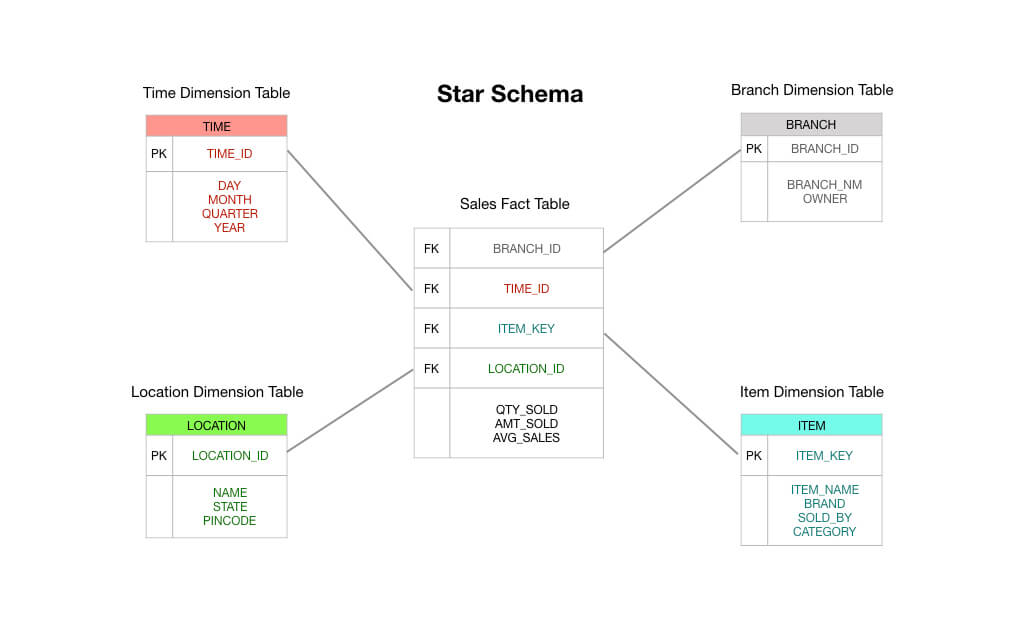
Więc widzisz, że tabela faktów transakcji jest dokładnie taka, jak mówi puszka: otrzymujesz transakcję, rejestrujesz ją w swojej tabeli faktów, a to staje się podstawą Twojej sprawozdawczości. Pod wieloma względami tabela faktów transakcji jest domyślnym typem tabeli faktów, o której zwykliśmy myśleć.
Periodic Snapshot Tables
Periodic snapshot fact tables są logicznym rozszerzeniem zwykłych, waniliowych tabel faktów, które właśnie omówiliśmy powyżej. Wiersz w okresowej tabeli faktów przechwytuje pewien rodzaj danych okresowych – na przykład, dzienny rzut metryk finansowych, lub tygodniowe podsumowanie należności, lub miesięczne podsumowanie numerów zapasów.
Innymi słowy, „ziarno” lub „poziom rozdzielczości” jest okresem, a nie pojedynczą transakcją. Zauważ, że jeśli w pewnym okresie nie wystąpią żadne transakcje, nowy wiersz musi zostać wstawiony do tabeli migawek okresowych, nawet jeśli każdy zapisany fakt jest zerem!
Tablice migawek okresowych mają tendencję do zawierania niewiarygodnie dużej liczby pól. Dzieje się tak, ponieważ każda rozsądnie interesująca metryka może zostać wepchnięta do tabeli okresowej. Możesz sobie wyobrazić scenariusz, w którym zaczynasz od zagregowanej sprzedaży, przychodów i kosztów sprzedanych towarów w okresie tygodniowym, ale w miarę upływu czasu, kierownictwo prosi o dodanie innych faktów, takich jak poziomy zapasów, metryki zobowiązań i inne interesujące pomiary.
Dlaczego okresowe tabele migawkowe są przydatne? Cóż, jest to dość proste do wyobrażenia. Jeśli chcesz mieć przegląd linii trendu w kluczowych wskaźnikach wydajności w swojej firmie, pomocne jest zapytanie do okresowej tabeli faktów.
Accumulating Snapshot Tables
W przeciwieństwie do okresowych tabel migawkowych, akumulacyjne tabele migawkowe są nieco trudniejsze do wyjaśnienia. Aby zrozumieć, dlaczego Kimball i jego rówieśnicy wymyślili to podejście, warto zrozumieć nieco rodzaje pytań zadawanych biznesowi w latach 90-tych, czyli w czasie, gdy po raz pierwszy napisano pakiet narzędzi hurtowni danych.
Pod koniec lat 80-tych japońscy producenci zaczęli pokonywać swoich amerykańskich kolegów na wszystkie rodzaje paskudnych, ale nieoczywistych sposobów. Głównym z nich był nacisk na szybkość wykonania.
Produkcja może być postrzegana jako seria kroków. Bierzesz surowiec na jednym końcu fabryki, i włączyć go do samochodów i telefonów i widżetów z drugiego końca. Każdy etap procesu produkcyjnego można zmierzyć – ile czasu zajmuje na przykład przekształcenie bloków stalowych w stalowe granulki? Jak długo czekają one w fabrycznych magazynach? A stamtąd, ile czasu upłynie, zanim granulat zostanie przetworzony na części samochodowe? Jak długo zanim zostaną wykorzystane w prawdziwych samochodach?
W późnych latach 70-tych japońskie firmy zaczęły zdawać sobie sprawę, że ten „ciąg kroków” w tworzeniu wartości może prowadzić do poważnej przewagi konkurencyjnej, jeśli zmniejszą czas opóźnienia pomiędzy każdym krokiem. Mówiąc bardziej konkretnie: jeśli uda im się ograniczyć liczbę kroków potrzebnych do wyprodukowania każdego elementu i jeśli uda im się skrócić czas trwania każdego kroku, japońscy producenci dowiedzieli się, że mogą ograniczyć marnotrawstwo materiałów, obniżyć wskaźniki wad i skrócić czas dostawy, a jednocześnie zwiększyć wydajność pracowników, zwiększyć wielkość produkcji, zwiększyć różnorodność produktów i obniżyć ceny – wszystko w tym samym czasie.
Do czasu, gdy nadeszły lata 90. Wielu konsultantów ds. zarządzania – wśród nich George Stalk Jr z Boston Consulting Group – zaczęło propagować tempo realizacji jako źródło przewagi konkurencyjnej. Konsultanci ci instruowali firmy, aby rejestrowały czas spędzony na każdym etapie procesu produkcyjnego. Kiedy przychodziło zamówienie, jak długo czekało na realizację? Po jego przetworzeniu, jak długo trwało zanim zamówienie zostało wysłane do fabryki? W fabryce, ile czasu upłynęło zanim produkt został ukończony? A potem jak długo czekał w magazynie? I wreszcie, jak długo trwało, zanim klient otrzymał produkt i uzyskał z niego wartość?
Biznesy w latach 90-tych były zatem naciskane do pomiaru czasów opóźnień w całym procesie dostawy biznesowej. Zostały do tego zmuszone, ponieważ japońscy konkurenci wkraczali do wielu branż wcześniej zdominowanych przez firmy zachodnie – w niektórych przypadkach powodując bankructwa i zakłócając całe łańcuchy dostaw. To właśnie w tym środowisku pracował Kimball.
Kumulująca się tabela faktów migawkowych jest więc metodą pomiaru szybkości w ramach procesu biznesowego. Weźmy na przykład ten potok biznesowy, który Kimball zaprezentował w drugim wydaniu The Data Warehouse Toolkit:
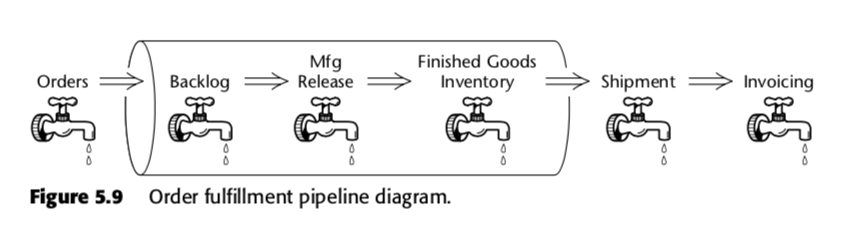
Dla tego procesu Kimball zaproponował następującą tabelę akumulujących się migawek:
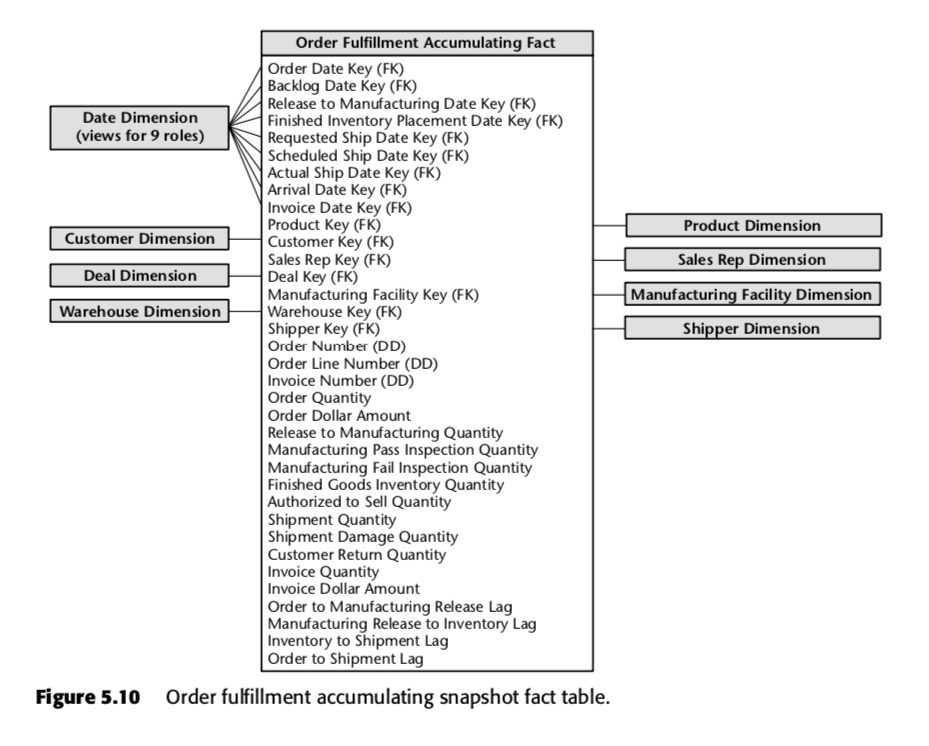
Każdy wiersz w tej tabeli reprezentuje zamówienie lub partię zamówień. Oczekuje się, że każdy z tych wierszy będzie wielokrotnie aktualizowany w miarę przechodzenia przez proces realizacji zamówienia. Zwróć uwagę w szczególności na samą liczbę pól daty na górze schematu. Kiedy wiersz jest po raz pierwszy tworzony w tej tabeli, większość z tych dat będzie zaczynać się jako zerowe, ale ostatecznie zostaną wypełnione w miarę upływu czasu. (Uwaga: Kimball używa tutaj tabeli wymiarów daty, zamiast wbudowanego typu danych daty SQL, ponieważ jest to sposób Kimballa ™ – pozwala uchwycić więcej informacji o datach niż tylko naiwne typy daty.)
Ważne są również pola na dole tej listy. Każde z nich mierzy wskaźnik lag – czyli różnicę pomiędzy dwoma datami. Tak więc na przykład Order to Manufacturing Release Lag to czas potrzebny od Order Date do Release to Manufacturing Date; Inventory to Shipment Lag to czas potrzebny od Finished Inventory Placement Date do Actual Ship Date i tak dalej. W miarę upływu czasu, każda z tych dat zostanie wypełniony przez system ERP lub może przez grunt wprowadzania danych. Czasy opóźnienia dla każdego konkretnego zamówienia będą zatem obliczane jako każde pole jest wypełnione.
Można zobaczyć, jak taka tabela byłaby przydatna dla firmy działającej w środowisku konkurencyjnym opartym na czasie. Korzystając z jednej tabeli, kierownictwo mogłoby sprawdzić, czy czasy opóźnień w produkcji rosną czy maleją w czasie. Mogą wykorzystać taką analitykę biznesową do określenia, które etapy procesu produkcyjnego są najbardziej problematyczne. I mogą podjąć działania na tych odcinkach, które są dla nich najbardziej niepokojące.
Uwaga dodatkowa: te pomysły zostały zaadaptowane do świata oprogramowania pod terminologią „lean”; aby uzyskać więcej informacji na temat pomiaru produkcji w firmach technologicznych, sprawdź nasze posty na temat książki Accelerate tutaj i tutaj.
Dlaczego się nie zmieniły?
To testament dla Kimballa i jego kolegów, że trzy rodzaje tabel faktów nie zmieniły się znacząco od czasu, gdy zostały po raz pierwszy wyartykułowane w 1996 roku.
Dlaczego tak jest? Odpowiedź, jak sądzę, leży w fakcie, że schemat gwiazdy oddaje coś fundamentalnego w biznesie. Jeśli modelujesz swoje dane, aby dopasować je do swoich procesów biznesowych, będziesz całkiem sporo przechwytywać dane o faktach na jeden z trzech sposobów: poprzez transakcje, z zestawionymi okresami i – jeśli twoja firma jest wystarczająco bystra w kwestii konkurencji opartej na czasie – poprzez pomiar czasów opóźnienia między każdym krokiem twojego systemu dostarczania wartości.
Kimball sam mówi coś podobnego. We wpisie na blogu z 2015 r. pisze:
Raczej niż zawieszać się na religijnych argumentach na temat modeli logicznych i fizycznych, powinniśmy po prostu uznać, że model wymiarowy jest w rzeczywistości interfejsem programowania aplikacji hurtowni danych (API). Siła tego API leży w spójnym i jednolitym interfejsie widzianym przez wszystkich obserwatorów, zarówno użytkowników, jak i aplikacje BI. Widzimy, że nie ma znaczenia, gdzie przechowywane są bity ani jak są one dostarczane, gdy uruchamiane jest żądanie API.
Schemat gwiazdy jest sprawdzony w czasie. To oczywiste.
W tym samym poście, Kimball następnie przechodzi do argumentowania, że nawet ostatnie innowacje, takie jak kolumnowa hurtownia danych, nie zmieniły tego faktu; większość firm, z którymi rozmawia, nadal kończy ze strukturą modelu wymiarowego na koniec dnia.
Ale rzeczy się zmieniły. W całym zestawie narzędzi hurtowni danych można znaleźć osobliwe wzmianki o „ograniczaniu liczby faktów na tabelę” i „planowaniu strategii modelowania danych z udziałem wszystkich interesariuszy domeny obecnych na spotkaniu”. Nie odzwierciedlają one tego, co widzimy w praktyce w naszej firmie i w działach danych naszych klientów.
Największą zmianą jest szybkość, z jaką obecne technologie umożliwiają nam przejście od „naiwnej tabeli faktów” do „modelu wymiarowego w stylu Kimballa” – co pozwala nam pominąć praktykę modelowania z góry, a zamiast tego zdecydować się na modelowanie tak mało, jak to konieczne. Praktyka ta jest możliwa dzięki wielu zmianom technologicznym, które omawialiśmy już wcześniej na tym blogu (przede wszystkim w naszym poście o Powstaniu i upadku kostki OLAP), ale praktyczne implikacje dla naszego wykorzystania tabel faktów są następujące:
- Transakcyjne tabele faktów – jesteśmy całkowicie zadowoleni z posiadania grubych tabel faktów, z dziesiątkami, jeśli nie setkami faktów na wiersz! Nie oznacza to, że jest to sytuacja idealna, a jedynie, że jest to bardzo akceptowalny kompromis. Inaczej niż w czasach Kimballa, talent do danych jest dziś niebotycznie drogi; przechowywanie i czas obliczeń są tanie. Dlatego nie mamy nic przeciwko pozostawieniu niektórych tabel faktów takimi, jakimi są – w rzeczywistości mamy kilka z ponad 100 polami, które zostały przesłane prosto z naszych systemów źródłowych! Nasze filozoficzne stanowisko jest następujące: jeśli mamy złożone wymagania dotyczące raportowania, to warto poświęcić czas i odpowiednio wymodelować dane. Jeśli jednak raporty, których potrzebujemy, są proste, wtedy korzystamy z dostępnej mocy obliczeniowej i pozostawiamy tabele faktów takimi, jakimi są.
- Tabele faktów z okresowymi migawkami – to zaskakujące, jak bardzo jesteśmy w stanie tego uniknąć. Ponieważ nowoczesne kolumnowe hurtownie danych MPP są tak wydajne, nie tworzymy okresowych migawkowych tabel faktów dla raportów, które nie są tak regularnie używane. Czas wykonywania zapytań i dodatkowy koszt generowania raportów z surowych danych transakcyjnych jest całkowicie do zaakceptowania, szczególnie jeśli wiemy, że raport jest potrzebny tylko raz w tygodniu lub częściej (lub udostępniany do okresowej eksploracji). W przypadku innych zbiorów danych generujemy okresowe tabele migawkowe zgodnie z oryginalnymi zaleceniami Kimballa.
- Akumulowanie tabel migawkowych – To jest prawie niezmienione od czasów Kimballa. Ale – jak mówi sam Kimball – akumulujące się tabele migawkowe są rzadkie w praktyce. Dlatego nie poświęcamy temu tak wiele uwagi, jak mogłaby to robić firma bardziej zorientowana na czas.
Warto tu zauważyć, że uważamy, iż modelowanie jest ważne. Różnica polega na tym, że nasza praktyka analityki danych pozwala nam na ponowne przeanalizowanie naszych decyzji dotyczących modelowania w dowolnym momencie w przyszłości. Jak to robimy? Cóż, ładujemy nasze surowe dane transakcyjne do naszej hurtowni danych przed transformacją. Jest to znane jako „ELT” w przeciwieństwie do „ETL”. Ponieważ wszystkie transformacje wykonujemy w hurtowni danych, używając warstwy modelowania danych, jesteśmy w stanie zweryfikować nasze wybory i przemodelować nasze dane, jeśli pojawi się taka potrzeba.
To pozwala nam skupić się na dostarczaniu wartości biznesowej w pierwszej kolejności. Dzięki temu ilość pracy związanej z modelowaniem danych jest niewielka.