Tässä artikkelissa havainnollistetaan, miten OFFSET FETCH -ominaisuutta voidaan käyttää ratkaisuna suurten tietomäärien lataamiseen relaatiotietokannasta koneella, jonka muisti on rajallinen, ja miten voidaan estää muistin loppuminen. Kuvaamme, miten tiedot ladataan erissä, jotta vältetään suuren tietomäärän sijoittaminen muistiin.
Tämä artikkeli on ensimmäinen SSIS Vinkkejä ja niksejä -sarjassa, jonka tarkoituksena on havainnollistaa joitakin parhaita käytäntöjä.
Esittely
Kun etsit verkosta SSIS:n datan tuontiin liittyviä ongelmia, löydät ratkaisuja, joita voidaan käyttää optimaalisissa ympäristöissä, tai oppaita, jotka koskevat pienen tietomäärän käsittelyä. Valitettavasti nämä ratkaisut osoittautuvat soveltumattomiksi todellisessa ympäristössä.
Todellisuudessa pienemmät yritykset eivät voi aina ottaa käyttöön uusia tallennus-, käsittelylaitteita ja tekniikoita, vaikka niiden on silti käsiteltävä yhä suurempia tietomääriä. Tämä pätee erityisesti sosiaalisen median analysointiin, koska niiden on analysoitava kohdeyleisönsä (asiakkaidensa) käyttäytymistä.
Samoin kaikki yritykset eivät voi ladata tietojaan pilvipalveluun korkeiden kustannusten sekä tietosuojaan ja luottamuksellisuuteen liittyvien kysymysten vuoksi.
OFFSET FETCH -ominaisuus
OFFSET FETCH on ominaisuus, joka lisättiin ORDER BY -lausekkeeseen SQL Server 2012 -versiosta alkaen. Sen avulla voidaan poimia tietty määrä rivejä tietystä indeksistä alkaen. Esimerkkinä meillä on kysely, joka palauttaa 40 riviä, ja meidän on poimittava 10 riviä 10. riviltä:
|
1
2
3
4
5
|
SELECT *
FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
Yllä olevassa kyselyssä, OFFSET 10 käytetään 10 rivin ohittamiseen ja FETCH 10 ROWS ONLY käytetään vain 10 rivin poimimiseen.
Lisätietoja ORDER BY -lausekkeesta ja OFFSET FETCH -ominaisuudesta saat virallisesta dokumentaatiosta: OFFSET- ja FETCH-ominaisuuksien käyttäminen palautettavien rivien rajoittamiseen.
OFFSET FETCH-ominaisuuden käyttäminen tietojen lataamiseen kappaleittain (sivunumerointi)
Yksi OFFSET FETCH -ominaisuuden tärkeimmistä käyttötarkoituksista on tietojen lataaminen kappaleittain. Kuvitellaan, että meillä on sovellus, joka suorittaa SQL-kyselyn ja jonka on näytettävä tulokset useilla sivuilla, joilla kullakin sivulla on vain 10 tulosta (kuten Googlen hakukoneessa).
Seuraavaa kyselyä voidaan käyttää paging-kyselynä, jossa @PageSize on kussakin lohkossa näytettävien rivien määrä ja @PageNumber on iteraation (sivun) numero:
|
1
2
3
3
4
5
|
SELECT <jotkut sarakkeet>
FROM <taulukon nimi>
ORDER BY <jotkut sarakkeet>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Tämän artikkelin tarkoituksena ei ole havainnollistaa kaikkia OFFSET FETCH -ominaisuuden käyttötapauksia, eikä siinä käsitellä parhaita käytäntöjä. Verkossa on monia artikkeleita, joista voit lukea lisätietoja:
- Pagination with OFFSET / FETCH : A better way
- Pagination in SQL Server using OFFSET / FETCH
Implementing the OFFSET FETCH feature within SSIS to load a large volume of data in chunks
Meitä on usein pyydetty rakentamaan SSIS-paketti, joka lataa SQL Serveristä valtavan määrän dataa rajoitetuilla koneresursseilla. Tietojen lataaminen OLE DB Source -lähteen avulla käyttäen Table- tai View-tiedonkäyttötilaa aiheutti muistin loppumisesta aiheutuvan poikkeuksen.
Yksi helpoimmista ratkaisuista on käyttää OFFSET FETCH -ominaisuutta tietojen lataamiseen palasina muistin loppumisesta aiheutuvien virheiden estämiseksi. Tässä osiossa annetaan vaiheittainen ohje tämän logiikan toteuttamisesta SSIS-paketissa.
Ensin on luotava uusi Integration Services -paketti ja sen jälkeen ilmoitettava neljä muuttujaa seuraavasti:
- RowCount (Int32): Tallentaa lähdetaulukon rivien kokonaismäärän
- IncrementValue (Int32): Tallentaa rivien määrän, joka meidän on määritettävä OFFSET-lausekkeessa (samanlainen kuin @PageSize * @PageNumber yllä olevassa esimerkissä)
- RowsInChunk (Int32): Määrittää rivien lukumäärän kussakin datakappaleessa (samanlainen kuin @PageSize yllä olevassa esimerkissä)
- SourceQuery (String): Tallentaa lähteen SQL-komennon, jota käytetään tietojen hakemiseen
Muuttujien ilmoittamisen jälkeen annamme RowsInChunk-muuttujalle oletusarvon; tässä esimerkissä sen arvoksi asetetaan 1000. Lisäksi meidän on määritettävä Source Query -lauseke seuraavasti:
|
1
2
3
4
5
|
”SELECT *
FROM …
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
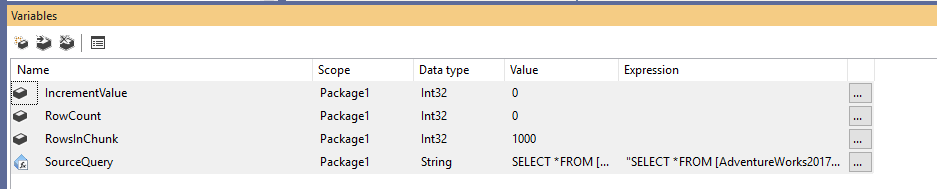
Kuva 1 – Muuttujien lisääminen
Seuraavaksi lisäämme Execute SQL Task -tehtävän, jonka avulla saamme lähdetaulukon rivien kokonaismäärän. Tässä esimerkissä käytämme AdventureWorks2017-tietokantaan tallennettua Person-taulukkoa. Execute SQL Taskissa käytimme seuraavaa SQL-lausetta:
|
1
|
SELECT COUNT(*) FROM …
|
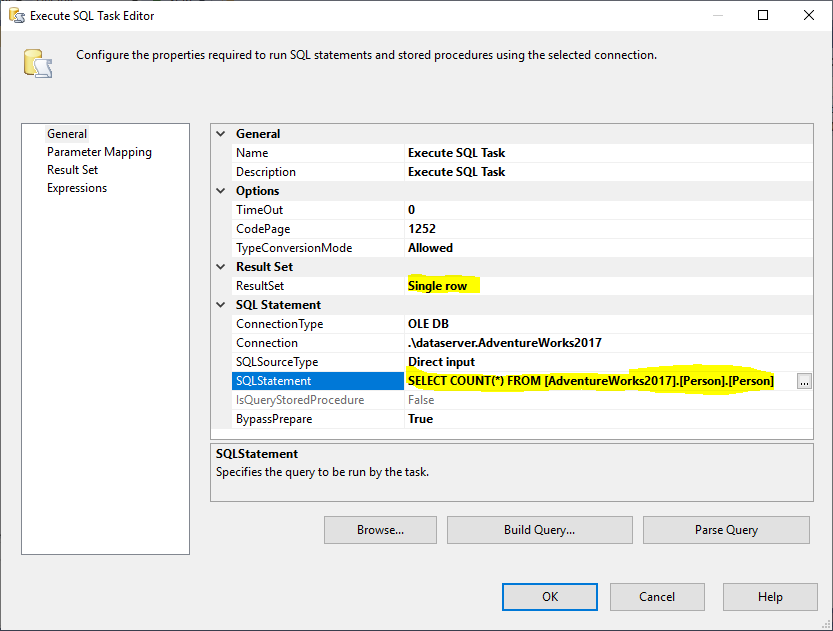
Kuva 2 – Execute SQL Taskin
asettaminen
Ja meidän on muutettava Tulosjoukko (Result Set) -ominaisuudeksi Yksittäinen rivi. Tämän jälkeen valitsemme Result Set -välilehdeltä RowCount-muuttujan tulosjoukon tallentamista varten alla olevan kuvan mukaisesti:
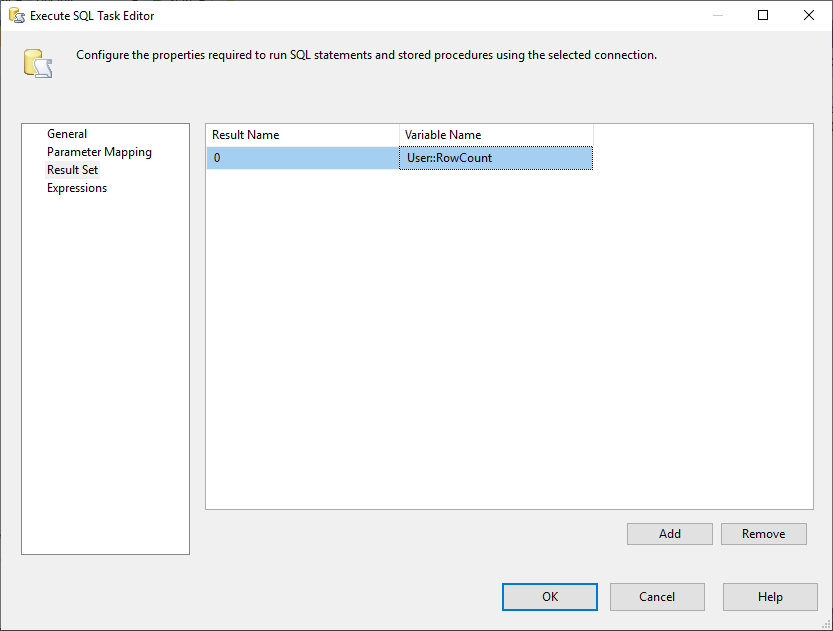
Kuva 3 – Tulosjoukon liittäminen muuttujaan
Execute SQL Task -tehtävän määrittelyn jälkeen lisäämme For Loop Container -kontinerin seuraavilla määrityksillä:
- InitExpression:
- EvalExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
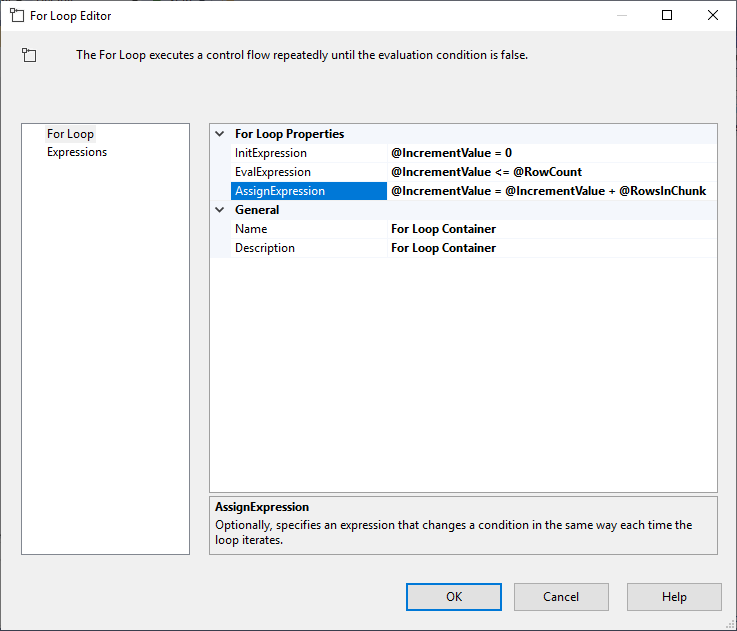
Kuva 4 – For Loop -konttorin konfigurointi
Kun For Loop -konttori on konfiguroitu, lisäämme sen sisälle Data Flow Taskin. Sen jälkeen lisäämme Data Flow Taskin sisälle OLE DB Source (OLE DB-lähde) ja OLE DB Destination (OLE DB-kohde).
OLE DB Source (OLE DB-lähde) -kohdassa valitsemme SQL Command (SQL-komento) -vaihtoehdon muuttujan data access mode (tiedonkäyttötilasta) ja valitsemme lähteenä @User::SourceQuery-muuttujan.
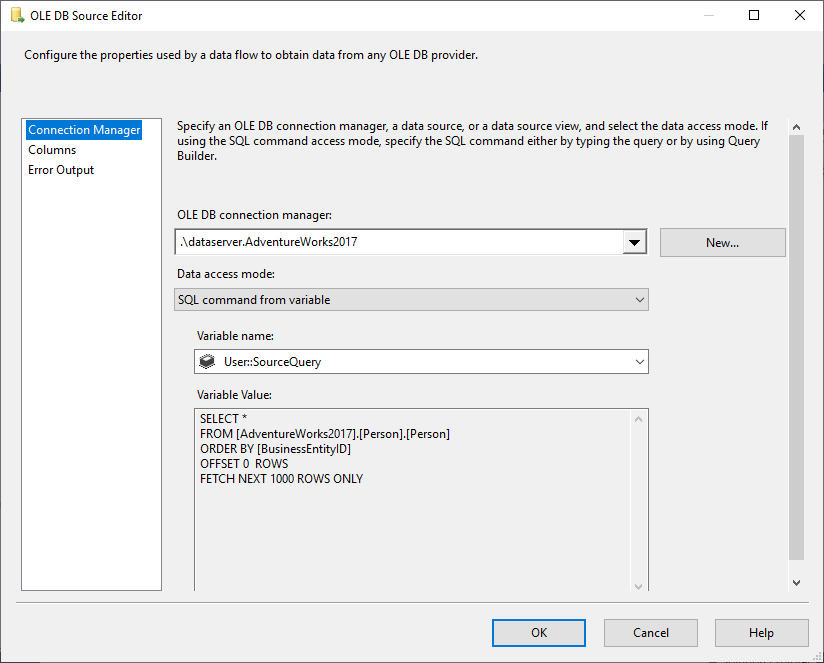
Kuva 5 – OLE DB -lähteen konfigurointi
Määritämme kohdetaulukon OLE DB Destination -komponentissa:
Kuva 6 – Tiedonsiirtotehtävän kuvakaappaus
Paketin ohjausvirran pitäisi näyttää seuraavalta:
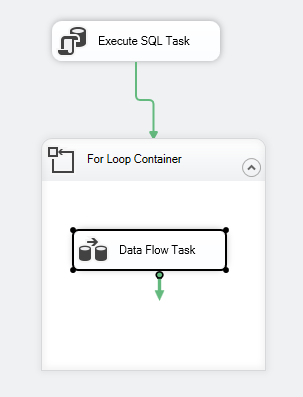
Kuva 7 – Ohjausvirran kuvakaappaus
Rajoitukset
Kun olemme havainnollistaneet, miten tietoja ladataan palasina käyttämällä SSIS:n OFFSET FETCH-ominaisuutta, huomaamme, että tällä logiikalla on joitain rajoituksia:
- ORDER BY -lausekkeessa on aina käytettävä joitakin sarakkeita (mieluiten identiteetti- tai ensisijainen avain), koska OFFSET FETCH on ORDER BY -lausekkeen ominaisuus eikä sitä voi toteuttaa erikseen
- Jos tietojen lataamisen aikana tapahtuu virhe, kaikki määränpäähän viety data sitoutuu ja vain nykyinen tietopaketti palautetaan. Tämä saattaa vaatia lisätoimia, joilla estetään tietojen päällekkäisyys, kun pakettia ajetaan uudelleen
OFFSET FETCH muiden tietokantatoimittajien käyttäminen
Seuraavassa osassa käsitellään lyhyesti muiden tietokantatoimittajien käyttämää syntaksia:
Oracle
Oraclessa voidaan käyttää samaa syntaksia kuin SQL Serverissä. Katso lisätietoja seuraavasta linkistä: Oracle FETCH
SQLite
SQLite:ssä syntaksi on erilainen kuin SQL Serverissä, koska käytät LIMIT OFFSET -ominaisuutta, kuten alla mainitaan:
|
1
2
3
|
SELECT * FROM MYTABLE. ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
MySQL, syntaksi on samanlainen kuin SQLitessä, koska käytetään LIMIT OFFSET OFFSET Fetchin sijaan.
DB2
DB2:ssa syntaksi on samanlainen kuin SQLite:ssä, koska käytät LIMIT OFFSET:iä OFFSET FETCH:n sijasta.
Tulos
Tässä artikkelissa kuvasimme SQL Server 2012:ssa ja sitä uudemmissa SQL Serverissä olevan OFFSET FETCH -ominaisuuden. Havainnollistimme, miten tätä ominaisuutta käytetään sivutuskyselyn luomiseen, ja annoimme sitten vaiheittaisen ohjeen siitä, miten tiedot ladataan palasina, jotta suuria tietomääriä voidaan poimia käyttämällä konetta, jolla on rajalliset resurssit. Lopuksi mainitsimme joitakin rajoituksia ja syntaksieroja muihin tietokantojen tarjoajiin nähden.
- Author
- Recent Posts

SQL Serverin kanssa työskentelyn lisäksi hän on työskennellyt erilaisten datateknologioiden, kuten NoSQL-tietokantojen, Hadoopin ja Apache Sparkin kanssa. Hän on Neo4j- ja ArangoDB-sertifioitu ammattilainen.
Akateemisella tasolla Hadilla on kaksi maisterintutkintoa tietojenkäsittelytieteestä ja liiketalouden tietojenkäsittelystä. Tällä hetkellä hän on datatieteen tohtorikoulutettava, joka keskittyy Big Data -laadunarviointitekniikoihin.
Hadi nauttii todella uuden oppimisesta joka päivä ja tiedon jakamisesta. Voit tavoittaa hänet hänen henkilökohtaisella verkkosivustollaan.
Katso kaikki käyttäjän Hadi Fadlallah viestit
- SSAS OLAP-kuutioiden rakentaminen Biml:llä – 16. maaliskuuta, 2021
- SQL Serverin graafitietokantojen siirtäminen Neo4j:hen – 9. maaliskuuta 2021
- Neo4j-graafitietokannan käyttöönotto – 5. helmikuuta 2021