Estadística Descriptiva
Para este tutorial vamos a utilizar el conjunto de datos autoque viene con Stata. Para cargar este tipo de datos
sysuse auto, clearEl conjunto de datos auto tiene las siguientes variables.
describe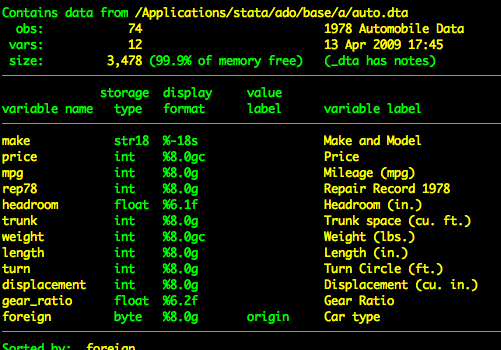
Supongamos que queremos obtener algunas estadísticas de resumen para el precio como la media, la desviación estándar y el rango. Utilizaremos el comando summarize.
summarize price
Ahora vamos a añadir la opción detail a summarize. Esto nos dará mucha más información, incluyendo la mediana y otros percentiles.
summarize price, detail
Múltiples variables a la vez
Para obtener los descriptivos de múltiples variables a la vez basta con añadir los nombres de las variables después de summarize.
summarize price mpg
Añadir la opción detail.
summarize price mpg, detail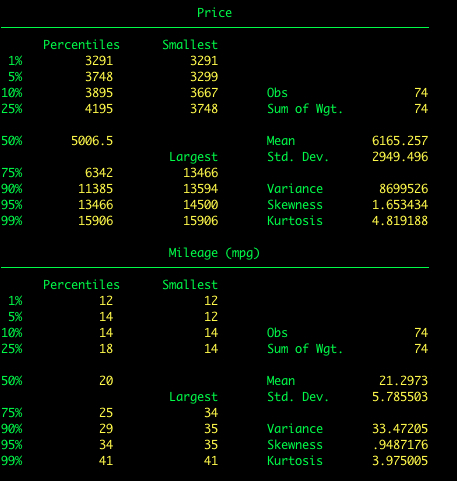
Usar por procesamiento
Supongamos que queremos obtener los estadísticos descriptivos del precio por tipo de coche (extranjero vs nacional). Podemos utilizar lo que se llama byprocesamiento.
by foreign: summarize price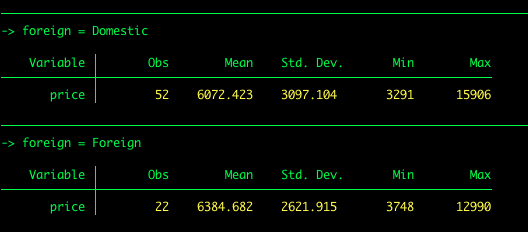
Cuando se utiliza el comando by, la variable de interés tiene que estar ordenada en el conjunto de datos. Por ejemplo, en el ejemplo anterior la variable «extranjero» ya está ordenada dentro de nuestro conjunto de datos. Si quisiéramos examinar el precio por mpg, necesitaríamos ordenar las millas por galón. Una forma de ordenar los datos es utilizando un simple comando de ordenación seguido del nombre de la variable. Stata ordenará los datos en orden ascendente por defecto.
sort mpgDespués de ordenar los datos, podemos utilizar el comando estándar by mpg:. En el procesamiento de by, también podemos ordenar los datos y ejecutar el comando by al mismo tiempo utilizando el comando bysort:
bysort mpg: summarize priceEl comando by también se puede utilizar en otros comandos, como la creación de gráficos. Por ejemplo, si quisiéramos examinar los histogramas de mpg según la marca del coche, utilizaríamos el comando by como opción. La marca del coche no tiene que estar ordenada para este comando.
histogram(mpg), by(foreign)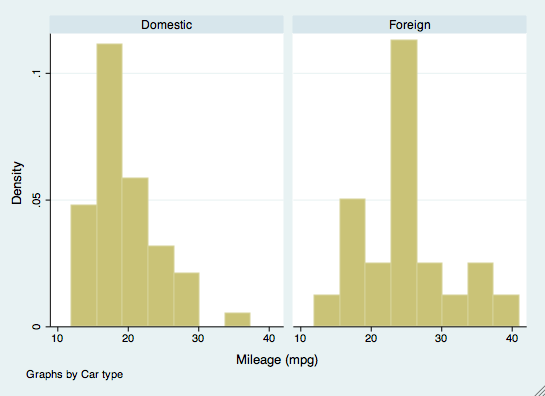
Usando if
La sentencia by nos dará las descripciones para todos los niveles de la variable by (es decir, tanto extranjeros como nacionales). Supongamos que sólo queremos las descripciones de un nivel de la variable by. Para ello podemos utilizar la sentencia if. Para los coches extranjeros (es decir, foreign == 1):
summarize price if foreign == 1
Para los coches nacionales (es decir, foreign == 0)
summarize price if foreign == 0
Esta tabla es para ayudar a determinar cómo especificar qué niveles de la variable que desea utilizar.
Símbolo |
Significado |
| == | ¡Es o es igual a |
| != o ~= | no es o es igual a |
| > | es mayor que |
| >= | es mayor o igual a |
| < | es menor que |
| <= | es menor o igual a |
| *De la pg. 74 de A Gentle Introduction to Stata por Alan Acock | |
Usando en
El calificador in especifica un subconjunto particular de casos basado en su orden en el conjunto de datos. Por ejemplo, si queremos examinar el mpg de los 10 coches menos caros, utilizaríamos el comando in.
sort pricesummarize mpg in 1/10
Como pista útil para cualquiera de estos procesos, si sus variables están etiquetadas (mostrando la etiqueta en lugar del valor numérico) y necesita encontrar los valores numéricos para examinar los niveles de la variable, puede utilizar la opción nolabel.
browse, nolabelEsto le mostrará los valores numéricos de las variables. También puede encontrar esos valores haciendo doble clic en ellos en el navegador de datos.