En este artículo, ilustramos cómo utilizar la característica OFFSET FETCH como solución para cargar grandes volúmenes de datos desde una base de datos relacional utilizando una máquina con memoria limitada y evitando una excepción de falta de memoria. Describimos cómo cargar los datos en lotes para evitar colocar una gran cantidad de datos en la memoria.
Este artículo es el primero de la serie de Consejos y Trucos de SSIS que pretende ilustrar algunas de las mejores prácticas.
Introducción
Cuando se buscan en Internet problemas relacionados con la importación de datos de SSIS, se encuentran soluciones que se pueden utilizar en entornos óptimos o tutoriales para manejar una pequeña cantidad de datos. Lamentablemente, estas soluciones resultan ser inadecuadas en un entorno real.
En realidad, las empresas más pequeñas no siempre pueden adoptar nuevos equipos de almacenamiento, procesamiento y tecnologías aunque deban manejar una cantidad creciente de datos. Esto es especialmente cierto para el análisis de los medios sociales, ya que deben analizar el comportamiento de su público objetivo (clientes).
Del mismo modo, no todas las empresas pueden subir sus datos a la nube debido al alto coste junto con los problemas de privacidad y confidencialidad de los datos.
Función OFFSET FETCH
OFFSET FETCH es una función añadida a la cláusula ORDER BY a partir de la edición de SQL Server 2012. Se puede utilizar para extraer un número específico de filas a partir de un índice específico. Como ejemplo, tenemos una consulta que devuelve 40 filas y necesitamos extraer 10 filas a partir de la décima fila:
|
1
2
3
4
5
|
SELECT *
FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
En la consulta anterior, OFFSET 10 se utiliza para saltar 10 filas y FETCH 10 ROWS ONLY se utiliza para extraer sólo 10 filas.
Para obtener información adicional sobre la cláusula ORDER BY y la función OFFSET FETCH, consulte la documentación oficial: Using OFFSET and FETCH to limit the rows returned.
Using OFFSET FETCH to load data in chunks (pagination)
Uno de los principales propósitos de utilizar la función OFFSET FETCH es cargar datos en trozos. Imaginemos que tenemos una aplicación que ejecuta una consulta SQL y necesita mostrar los resultados en varias páginas donde cada página contiene sólo 10 resultados (similar al buscador de Google).
La siguiente consulta se puede utilizar como una consulta de paginación donde @PageSize es el número de filas que necesita mostrar en cada chunk y @PageNumber es el número de iteración (página):
|
1
2
3
4
5
|
SELECT <algunas columnas>
FROM <nombre de la tabla>
ORDER BY <algunas columnas>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Este artículo no pretende ilustrar todos los casos de uso de la función OFFSET FETCH, ni discutir las mejores prácticas. Hay muchos artículos en línea que puede consultar para obtener más información:
- Paginación con OFFSET / FETCH : Una mejor manera
- Paginación en SQL Server utilizando OFFSET / FETCH
Implementación de la función OFFSET FETCH dentro de SSIS para cargar un gran volumen de datos en trozos
A menudo nos han pedido que construyamos un paquete SSIS que cargue una gran cantidad de datos desde SQL Server con recursos de máquina limitados. La carga de datos mediante OLE DB Source utilizando el modo de acceso a datos de Tabla o Vista provocaba una excepción de falta de memoria.
Una de las soluciones más sencillas es utilizar la función OFFSET FETCH para cargar los datos en trozos y evitar errores de falta de memoria. En esta sección, proporcionamos una guía paso a paso sobre la implementación de esta lógica dentro de un paquete SSIS.
En primer lugar, debemos crear un nuevo paquete de Integration Services, y luego declarar cuatro variables como sigue:
- RowCount (Int32): Almacena el número total de filas de la tabla origen
- IncrementValue (Int32): Almacena el número de filas que debemos especificar en la cláusula OFFSET (similar a @PageSize * @PageNumber en el ejemplo anterior)
- RowsInChunk (Int32): Especifica el número de filas en cada trozo de datos (similar a @PageSize en el ejemplo anterior)
- SourceQuery (String): Almacena el comando SQL fuente utilizado para obtener los datos
Después de declarar las variables, asignamos un valor por defecto para la variable RowsInChunk; en este ejemplo, lo estableceremos en 1000. Además, debemos establecer la expresión de la consulta de origen, como sigue:
|
1
2
3
4
5
|
«SELECT *
FROM ..
ORDER BY
OFFSET » + (DT_WSTR,50)@ + » ROWS
FETCH NEXT » + (DT_WSTR,50) @ + » ROWS ONLY»
|
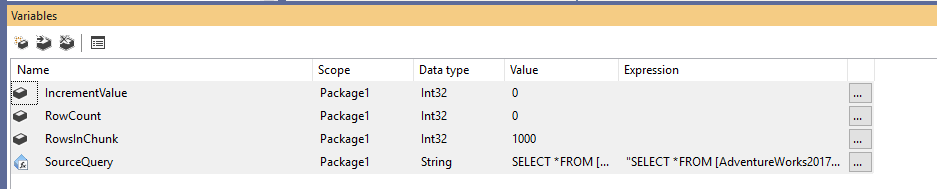
Figura 1 – Adición de variables
A continuación, añadimos una Tarea SQL Execute para obtener el número total de filas de la tabla origen. En este ejemplo, utilizamos la tabla Persona almacenada en la base de datos AdventureWorks2017. En la Execute SQL Task, utilizamos la siguiente sentencia SQL:
|
1
|
SELECT COUNT(*) FROM ..
|
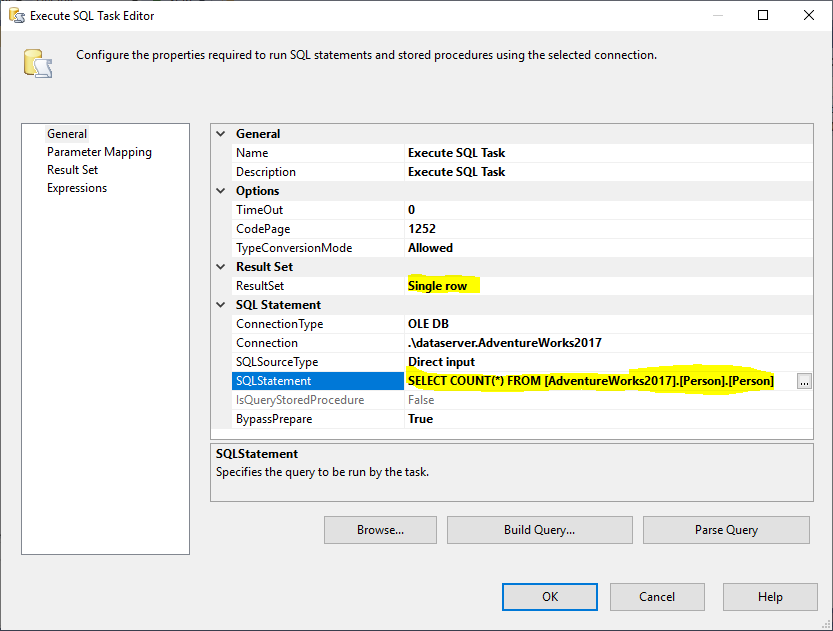
Figura 2 – Configuración de la Tarea de Ejecución de SQL
Y, debemos cambiar la propiedad de Conjunto de Resultados a Fila Única. A continuación, en la pestaña Result Set, seleccionamos la variable RowCount para almacenar el conjunto de resultados como se muestra en la siguiente imagen:
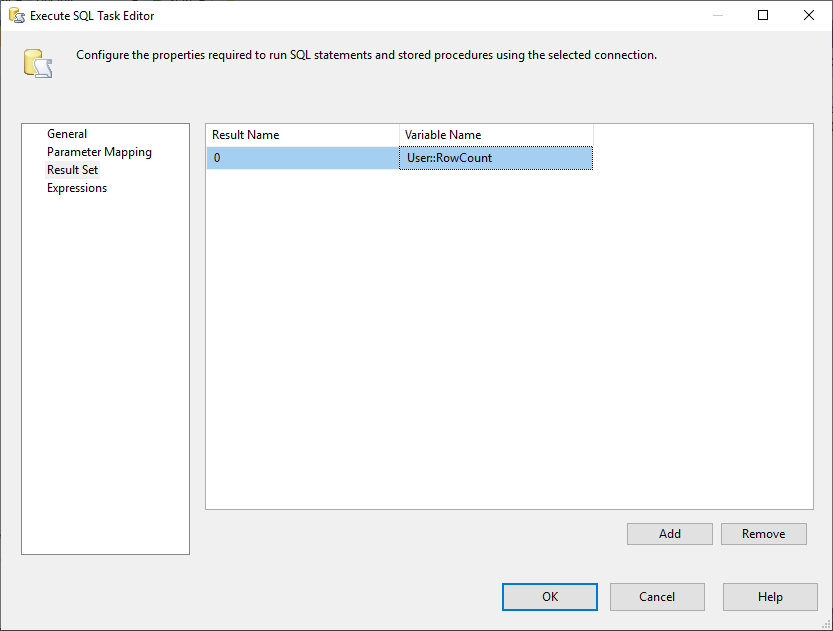
Figura 3 – Asignación del conjunto de resultados a la variable
Después de configurar la Execute SQL Task, añadimos un For Loop Container, con las siguientes especificaciones:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
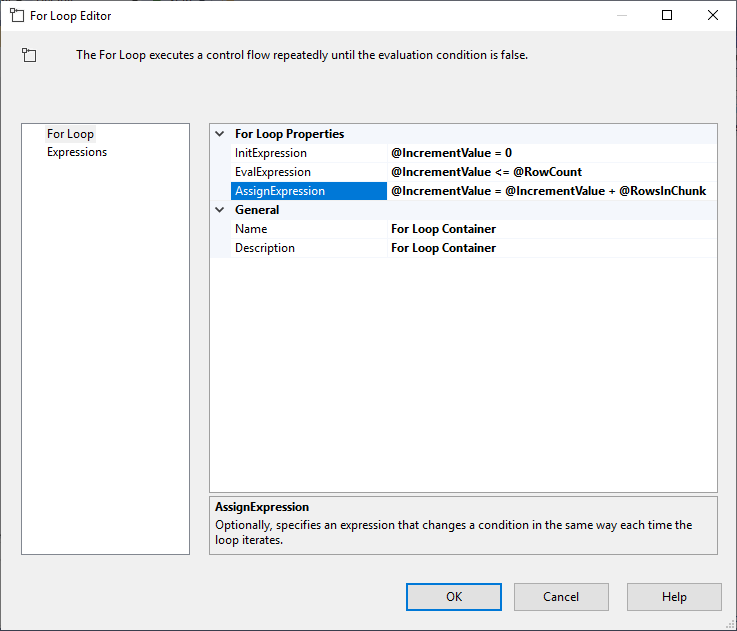
Figura 4 – Configuración del contenedor del bucle For
Después de configurar el Contenedor del Bucle For, añadimos una Tarea de Flujo de Datos dentro del mismo. A continuación, dentro de la Tarea de Flujo de Datos, añadimos un Origen OLE DB y un Destino OLE DB.
En el Origen OLE DB seleccionamos Comando SQL del modo de acceso a datos variables, y seleccionamos la variable @User::SourceQuery como origen.
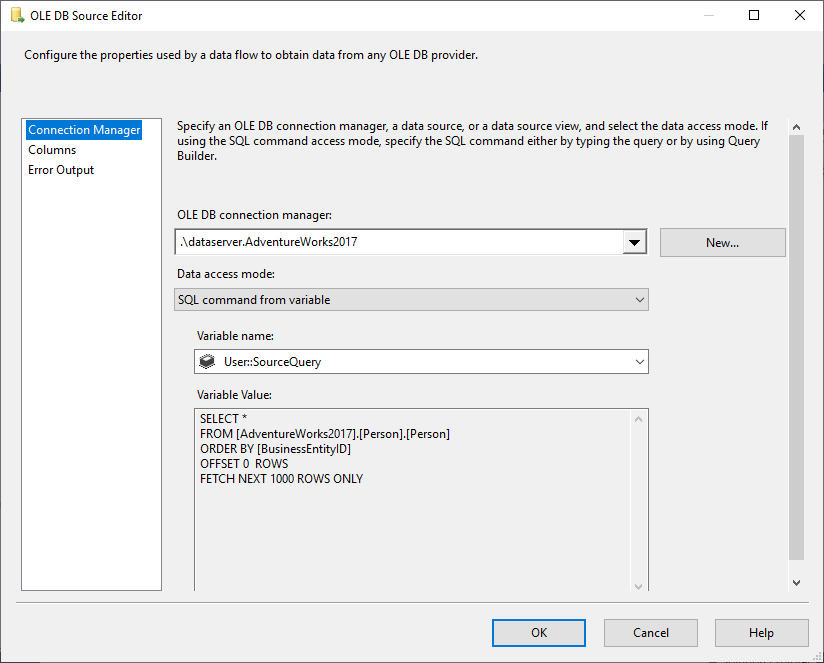
Figura 5 – Configuración de la fuente OLE DB
Especificamos la tabla de destino dentro del componente OLE DB Destino:
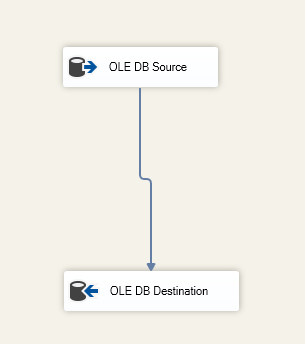
Figura 6 – Captura de pantalla de la tarea de flujo de datos
El flujo de control del paquete debe ser como el siguiente:
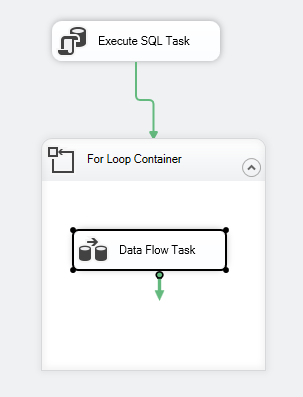
Figura 7 – Captura de pantalla del flujo de control
Limitaciones
Después de ilustrar cómo cargar datos en trozos utilizando la función OFFSET FETCH en SSIS, observaremos que esta lógica tiene algunas limitaciones:
- Siempre se necesitan algunas columnas para ser utilizadas en la cláusula ORDER BY (se prefiere la identidad o la clave primaria), ya que OFFSET FETCH es una característica de la cláusula ORDER BY y no se puede implementar por separado
- Si se produce un error mientras se cargan los datos, todos los datos exportados al destino se comprometen y sólo el trozo actual de datos se retrocede. Esto puede requerir pasos adicionales para evitar la duplicación de datos cuando se ejecuta el paquete de nuevo
OFFSET FETCH utilizando otros proveedores de bases de datos
En la siguiente sección, cubrimos brevemente la sintaxis utilizada por otros proveedores de bases de datos:
Oracle
Con Oracle, puede utilizar la misma sintaxis que SQL Server. Consulte el siguiente enlace para obtener más información: Oracle FETCH
SQLite
En SQLite, la sintaxis es diferente a la de SQL Server, ya que se utiliza la función LIMIT OFFSET como se menciona a continuación:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
En MySQL, la sintaxis es similar a la de SQLite, ya que se utiliza LIMIT OFFSET en lugar de OFFSET Fetch.
DB2
En DB2, la sintaxis es similar a la de SQLite, ya que se utiliza LIMIT OFFSET en lugar de OFFSET FETCH.
Conclusión
En este artículo, hemos descrito la característica OFFSET FETCH que se encuentra en SQL Server 2012 y superior. Hemos ilustrado cómo utilizar esta función para crear una consulta de paginación y, a continuación, hemos proporcionado una guía paso a paso sobre cómo cargar datos en trozos para permitir la extracción de grandes cantidades de datos utilizando una máquina con recursos limitados. Por último, se mencionaron algunas de las limitaciones y las diferencias de sintaxis con otros proveedores de bases de datos.
- Autor
- Puestos recientes

Además de trabajar con SQL Server, trabajó con diferentes tecnologías de datos como bases de datos NoSQL, Hadoop, Apache Spark. Es un profesional certificado en Neo4j y ArangoDB.
A nivel académico, Hadi tiene dos másteres en informática y en computación empresarial. Actualmente, es candidato a doctor en ciencias de los datos, centrándose en las técnicas de evaluación de la calidad de Big Data.
Hadi realmente disfruta aprendiendo cosas nuevas cada día y compartiendo sus conocimientos. Puedes contactar con él en su página web personal.
Ver todos los comentarios de Hadi Fadlallah
- Construcción de cubos OLAP SSAS utilizando Biml – 16 de marzo, 2021
- Migración de bases de datos gráficas de SQL Server a Neo4j – 9 de marzo de 2021
- Introducción a la base de datos gráfica de Neo4j – 5 de febrero de 2021