Estructura de los virus
Los virus no son plantas, ni animales, ni bacterias, pero son los parásitos por excelencia de los reinos vivos. Aunque puedan parecer organismos vivos por su prodigiosa capacidad reproductiva, los virus no son organismos vivos en el sentido estricto de la palabra.
Sin una célula huésped, los virus no pueden realizar sus funciones vitales ni reproducirse. No pueden sintetizar proteínas, porque carecen de ribosomas y deben utilizar los ribosomas de sus células huésped para traducir el ARN mensajero viral en proteínas virales. Los virus no pueden generar ni almacenar energía en forma de trifosfato de adenosina (ATP), sino que tienen que obtener su energía, y todas las demás funciones metabólicas, de la célula huésped. También parasitan la célula para obtener materiales de construcción básicos, como aminoácidos, nucleótidos y lípidos (grasas). Aunque se ha especulado con la posibilidad de que los virus sean una forma de protovida, su incapacidad para sobrevivir sin organismos vivos hace muy improbable que hayan precedido a la vida celular durante la evolución temprana de la Tierra. Algunos científicos especulan con que los virus empezaron como segmentos de código genético sin sentido que se adaptaron a una existencia parasitaria.
Todos los virus contienen ácido nucleico, ya sea ADN o ARN (pero no ambos), y una cubierta proteica, que envuelve el ácido nucleico. Algunos virus también están rodeados por una envoltura de moléculas de grasa y proteínas. En su forma infecciosa, fuera de la célula, una partícula de virus se llama virión. Cada virión contiene al menos una proteína única sintetizada por genes específicos en su ácido nucleico. Los viroides (que significa «parecido a un virus») son organismos causantes de enfermedades que sólo contienen ácido nucleico y no tienen proteínas estructurales. Otras partículas parecidas a los virus, llamadas priones, están compuestas principalmente por una proteína estrechamente integrada con una pequeña molécula de ácido nucleico.
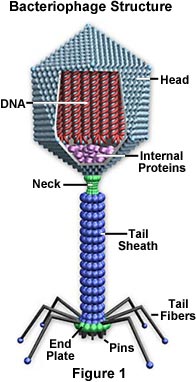
Los virus se clasifican generalmente por los organismos que infectan, animales, plantas o bacterias. Dado que los virus no pueden penetrar las paredes celulares de las plantas, prácticamente todos los virus de las plantas son transmitidos por insectos u otros organismos que se alimentan de ellas. Algunos virus bacterianos, como el bacteriófago T4, han desarrollado un elaborado proceso de infección. El virus tiene una «cola» que se adhiere a la superficie de la bacteria por medio de «clavijas» proteináceas. La cola se contrae y el tapón de la cola penetra la pared celular y la membrana subyacente, inyectando los ácidos nucleicos virales en la célula. Los virus se clasifican a su vez en familias y géneros en función de tres consideraciones estructurales 1) el tipo y el tamaño de su ácido nucleico, 2) el tamaño y la forma de la cápside, y 3) si tienen una envoltura lipídica que rodea la nucleocápside (el ácido nucleico encerrado en la cápside).
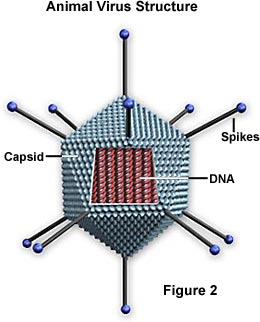
Hay predominantemente dos tipos de formas encontradas entre los virus: varillas, o filamentos, y esferas. La forma de varilla se debe a la disposición lineal del ácido nucleico y las subunidades proteicas que componen la cápside. La forma de esfera es en realidad un polígono de 20 lados (icosaedro).
La naturaleza de los virus no se comprendió hasta el siglo XX, pero sus efectos se habían observado durante siglos. El médico británico Edward Jenner incluso descubrió el principio de la inoculación a finales del siglo XVIII, tras observar que las personas que contraían la enfermedad leve de la viruela de las vacas eran generalmente inmunes a la enfermedad más mortal de la viruela. A finales del siglo XIX, los científicos sabían que algún agente causaba la enfermedad de las plantas de tabaco, pero no crecía en un medio artificial (como las bacterias) y era demasiado pequeño para ser visto a través de un microscopio de luz. Los avances en el cultivo de células vivas y la microscopía en el siglo XX permitieron finalmente a los científicos identificar los virus. Los avances en genética mejoraron drásticamente el proceso de identificación.
-
Cápside – La cápside es la cubierta proteica que encierra el ácido nucleico; con su ácido nucleico encerrado, se llama nucleocápside. Esta cubierta está compuesta por proteínas organizadas en subunidades conocidas como capsómeros. Están estrechamente asociados al ácido nucleico y reflejan su configuración, ya sea una hélice en forma de varilla o una esfera en forma de polígono. La cápside tiene tres funciones: 1) protege el ácido nucleico de la digestión por parte de las enzimas, 2) contiene sitios especiales en su superficie que permiten al virión adherirse a una célula huésped, y 3) proporciona proteínas que permiten al virión penetrar la membrana de la célula huésped y, en algunos casos, inyectar el ácido nucleico infeccioso en el citoplasma de la célula. En las condiciones adecuadas, el ARN viral en una suspensión líquida de moléculas proteicas autoensamblará una cápside para convertirse en un virus funcional e infeccioso.
-
Envoltura – Muchos tipos de virus tienen una envoltura glicoproteica que rodea la nucleocápside. La envoltura está compuesta por dos capas de lípidos intercaladas con moléculas de proteínas (bicapa lipoproteica) y puede contener material de la membrana de una célula huésped así como de origen viral. El virus obtiene las moléculas lipídicas de la membrana celular durante el proceso de gemación viral. Sin embargo, el virus sustituye las proteínas de la membrana celular por sus propias proteínas, creando una estructura híbrida de lípidos derivados de la célula y proteínas derivadas del virus. Muchos virus también desarrollan picos hechos de glicoproteína en sus envolturas que les ayudan a adherirse a superficies celulares específicas.
-
Ácido nucleico – Al igual que en las células, el ácido nucleico de cada virus codifica la información genética para la síntesis de todas las proteínas. Mientras que el ADN de doble cadena es el responsable de esto en las células procariotas y eucariotas, sólo unos pocos grupos de virus utilizan el ADN. La mayoría de los virus mantienen toda su información genética con el ARN monocatenario. Hay dos tipos de virus basados en el ARN. En la mayoría, el ARN genómico se denomina cadena positiva porque actúa como ARN mensajero para la síntesis directa (traducción) de la proteína viral. Sin embargo, unos pocos tienen hebras negativas de ARN. En estos casos, el virión tiene una enzima, llamada ARN polimerasa dependiente de ARN (transcriptasa), que debe catalizar primero la producción de ARN mensajero complementario a partir del ARN genómico del virión antes de que pueda producirse la síntesis de proteínas virales.
El virus de la influenza (gripe) – Después del resfriado común, la influenza o «la gripe» es quizás la infección respiratoria más conocida en el mundo. Sólo en Estados Unidos, aproximadamente entre 25 y 50 millones de personas contraen la gripe cada año. Los síntomas de la gripe son similares a los del resfriado común, pero suelen ser más graves. La fiebre, el dolor de cabeza, la fatiga, la debilidad y el dolor muscular, el dolor de garganta, la tos seca y el goteo o la congestión nasal son comunes y pueden desarrollarse rápidamente. Los síntomas gastrointestinales asociados a la gripe los experimentan a veces los niños, pero para la mayoría de los adultos, las enfermedades que se manifiestan en forma de diarrea, náuseas y vómitos no están causadas por el virus de la gripe, aunque a menudo se denominan de forma inexacta «gripe estomacal». Una serie de complicaciones, como la aparición de bronquitis y neumonía, también pueden producirse en asociación con la gripe y son especialmente comunes entre los ancianos, los niños pequeños y cualquier persona con el sistema inmunitario suprimido.
El virus de la inmunodeficiencia humana (VIH) – El virus responsable del VIH fue aislado por primera vez en 1983 por Robert Gallo, de Estados Unidos, y el científico francés Luc Montagnier. Desde entonces, se ha llevado a cabo una enorme cantidad de investigaciones centradas en el agente causante del SIDA y se ha aprendido mucho sobre la estructura del virus y su curso de acción típico. El VIH pertenece a un grupo de virus atípicos llamados retrovirus que mantienen su información genética en forma de ácido ribonucleico (ARN). Mediante el uso de una enzima conocida como transcriptasa inversa, el VIH y otros retrovirus son capaces de producir ácido desoxirribonucleico (ADN) a partir de ARN, mientras que la mayoría de las células llevan a cabo el proceso contrario, transcribiendo el material genético del ADN en ARN. La actividad de la enzima permite que la información genética del VIH se integre de forma permanente en el genoma (cromosomas) de una célula huésped.
Volver al inicio de la estructura celular
¿Preguntas o comentarios? Envíenos un correo electrónico.
© 1995-2021 por Michael W. Davidson y The Florida State University. Todos los derechos reservados. No se pueden reproducir ni utilizar imágenes, gráficos, software, scripts o applets de ninguna manera sin el permiso de los titulares de los derechos de autor. El uso de este sitio web significa que usted acepta todos los Términos y Condiciones Legales establecidos por los propietarios.
Este sitio web es mantenido por nuestro
Equipo de Programación Web& en colaboración con Microscopía Óptica en el
Laboratorio Nacional de Alto Campo Magnético.
Última modificación: Friday, Nov 13, 2015 at 02:18 PM
Cuento de accesos desde el 1 de octubre de 2000: 1951931
Microscopios proporcionados por:
![]()
![]()