V tomto článku si ukážeme, jak použít funkci OFFSET FETCH jako řešení pro načítání velkých objemů dat z relační databáze pomocí počítače s omezenou pamětí a zabránit výjimce nedostatku paměti. Popíšeme, jak načítat data v dávkách, abychom se vyhnuli umístění velkého množství dat do paměti.
Tento článek je první ze série tipů a triků SSIS, jejímž cílem je ilustrovat některé osvědčené postupy.
Úvod
Při hledání problémů souvisejících s importem dat SSIS na internetu najdete řešení, která lze použít v optimálním prostředí, nebo návody pro zpracování malého množství dat. Bohužel se ukazuje, že tato řešení jsou v reálném prostředí nevhodná.
Ve skutečnosti menší společnosti nemohou vždy přijmout nová úložná zařízení, zařízení pro zpracování a technologie, přestože musí zpracovávat stále větší množství dat. To platí zejména pro analýzu sociálních médií, protože musí analyzovat chování své cílové skupiny (zákazníků).
Stejně tak ne všechny společnosti mohou nahrávat svá data do cloudu kvůli vysokým nákladům spolu s otázkami ochrany soukromí a důvěrnosti dat.
Funkce OFFSET FETCH
OFFSET FETCH je funkce přidaná do klauzule ORDER BY počínaje edicí SQL Server 2012. Lze ji použít k extrakci určitého počtu řádků počínaje určitým indexem. Jako příklad můžeme uvést dotaz, který vrací 40 řádků a my potřebujeme extrahovat 10 řádků od 10. řádku:
|
1
2
3
4
5
|
SELECT *
. FROM Tabulka
ORDER BY ID
OFFSET 10 ŘÁDKŮ
FETCH NEXT 10 ROWS ONLY
|
Ve výše uvedeném dotazu, OFFSET 10 se použije pro vynechání 10 řádků a FETCH 10 ROWS ONLY se použije pro získání pouze 10 řádků.
Další informace o klauzuli ORDER BY a funkci OFFSET FETCH najdete v oficiální dokumentaci:
Použití funkce OFFSET FETCH k načítání dat po částech (stránkování)
Jedním z hlavních účelů použití funkce OFFSET FETCH je načítání dat po částech. Představme si, že máme aplikaci, která provádí dotaz SQL a potřebuje zobrazit výsledky na několika stránkách, přičemž každá stránka obsahuje pouze 10 výsledků (podobně jako vyhledávač Google).
Následující dotaz lze použít jako stránkovací dotaz, kde @PageSize je počet řádků, které potřebujete zobrazit v každém chunku, a @PageNumber je číslo iterace (stránky):
|
1
2
3
4
5
|
SELECT <některé sloupce>
FROM <název tabulky>
ORDER BY <některé sloupce>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Tento článek si neklade za cíl ilustrovat všechny případy použití funkce OFFSET FETCH, ani nepojednává o osvědčených postupech. Na internetu existuje mnoho článků, ve kterých najdete další informace:
- Stránkování pomocí OFFSET / FETCH : Lepší způsob
- Stránkování v SQL Serveru pomocí OFFSET / FETCH
Implementace funkce OFFSET FETCH v rámci SSIS pro načítání velkého objemu dat po částech
Často jsme byli požádáni o vytvoření balíčku SSIS, který načítá obrovské množství dat ze serveru SQL Server s omezenými strojovými prostředky. Načítání dat pomocí zdroje OLE DB s použitím režimu přístupu k datům Table nebo View způsobovalo výjimku nedostatku paměti
Jedním z nejjednodušších řešení je použití funkce OFFSET FETCH pro načítání dat po částech, aby se zabránilo chybám nedostatku paměti. V této části uvádíme návod krok za krokem, jak tuto logiku implementovat v rámci balíčku SSIS.
Nejprve musíme vytvořit nový balíček Integration Services a poté deklarovat čtyři proměnné takto:
- RowCount (Int32): Uloží celkový počet řádků ve zdrojové tabulce
- IncrementValue (Int32): Ukládá počet řádků, které musíme zadat v klauzuli OFFSET (podobně jako @PageSize * @PageNumber v příkladu výše)
- RowsInChunk (Int32): (podobně jako @PageSize v příkladu výše)
- SourceQuery (String):
Po deklaraci proměnných přiřadíme proměnné RowsInChunk výchozí hodnotu; v tomto příkladu ji nastavíme na 1000. Dále musíme nastavit výraz Source Query, a to takto:
|
1
2
3
4
5
|
„SELECT *
FROM …
ORDER BY
OFFSET “ + (DT_WSTR,50)@ + “ ŘÁDKY
FETCH NEXT “ + (DT_WSTR,50) @ + “ POUZE ŘÁDKY“
|
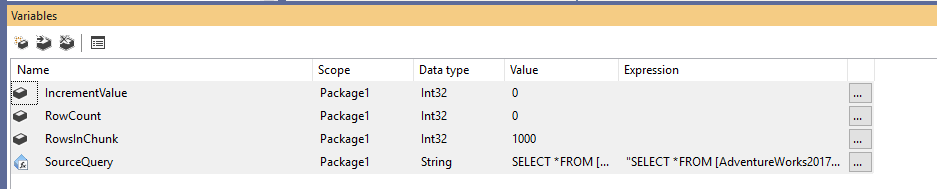
Obrázek 1 – Přidání proměnných
Dále přidáme úlohu Execute SQL pro získání celkového počtu řádků ve zdrojové tabulce. V tomto příkladu použijeme tabulku Person uloženou v databázi AdventureWorks2017. V úloze Execute SQL Task jsme použili následující příkaz SQL:
|
1
|
SELECT COUNT(*) FROM …
|
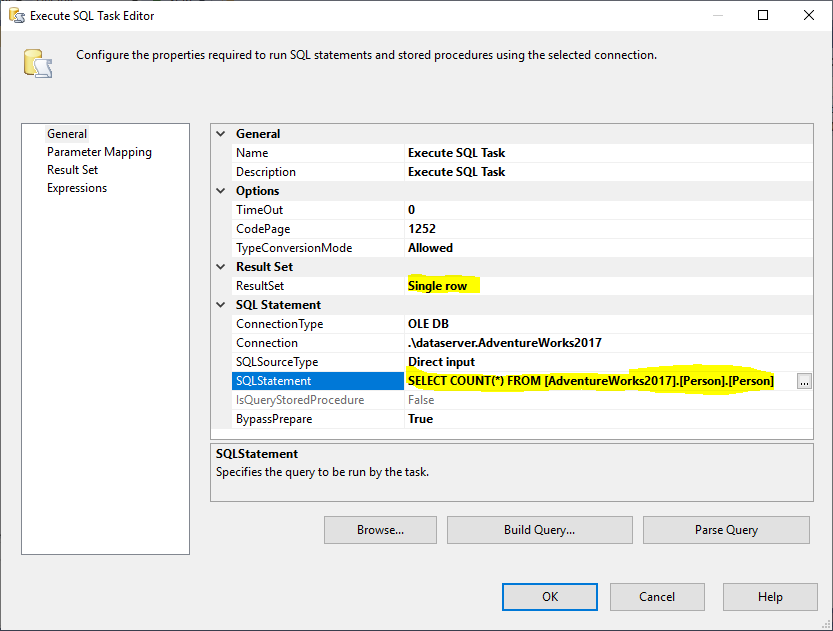
Obrázek 2 – Nastavení Execute SQL Task
A ještě musíme změnit vlastnost Result Set na Single Row. Poté na kartě Sada výsledků vybereme proměnnou RowCount pro uložení sady výsledků, jak ukazuje následující obrázek:
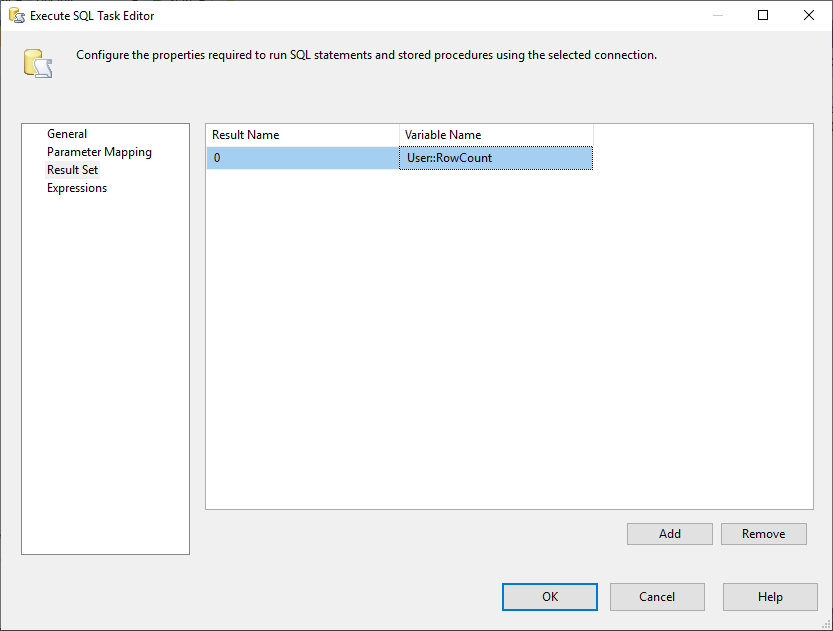
Obrázek 3 – Mapování sady výsledků na proměnnou
Po nastavení úlohy Execute SQL přidáme kontejner For Loop s následující specifikací:
- InitExpression: Výraz: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
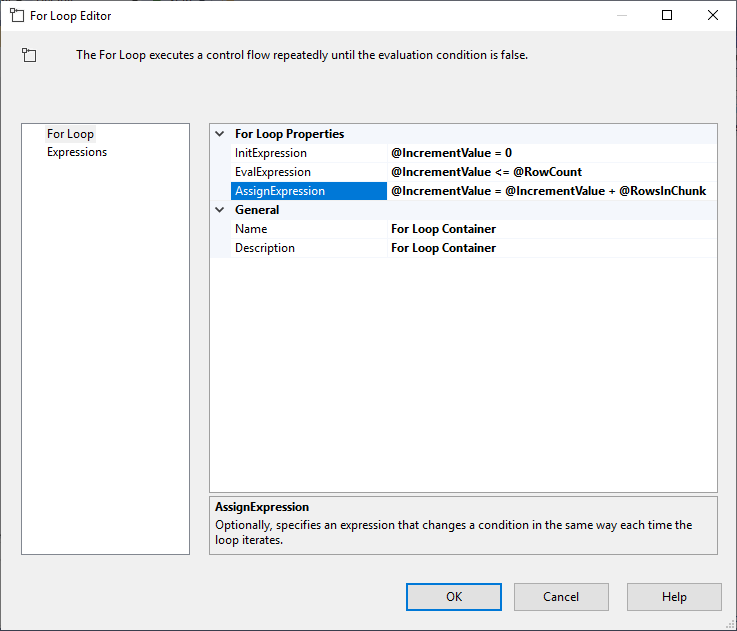
Obrázek 4 – Konfigurace kontejneru smyčky For
Po konfiguraci kontejneru smyčky For do něj přidáme úlohu toku dat. Poté v rámci Data Flow Task přidáme OLE DB Source a OLE DB Destination.
V OLE DB Source vybereme z režimu přístupu k datům proměnnou SQL Command a jako zdroj vybereme proměnnou @User::SourceQuery.
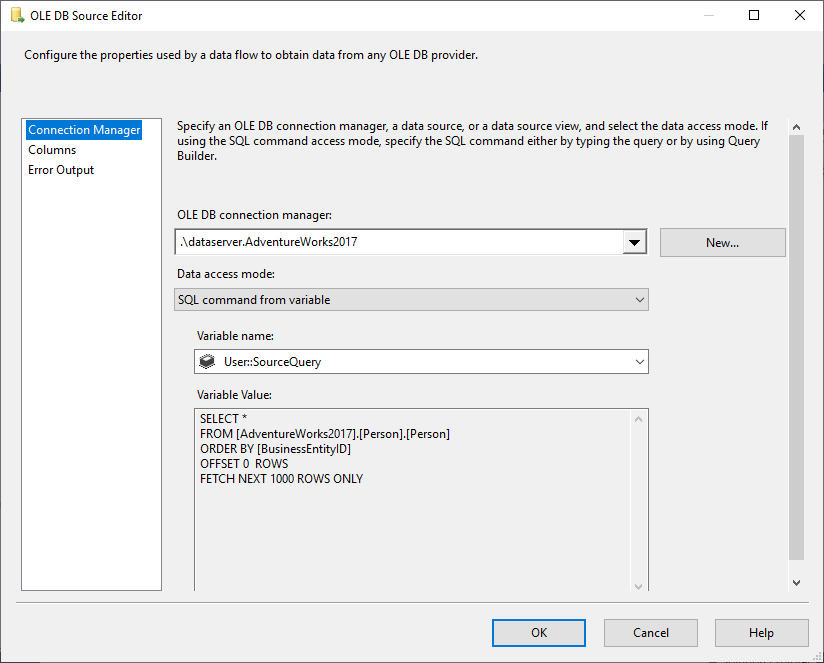
Obrázek 5 – Konfigurace OLE DB source
V komponentě OLE DB Destination zadáme cílovou tabulku:
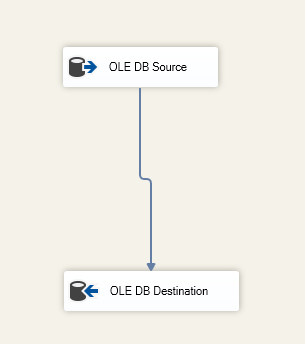
Obrázek 6 – Snímek obrazovky úlohy toku dat
Tok řízení balíčku by měl vypadat následovně:
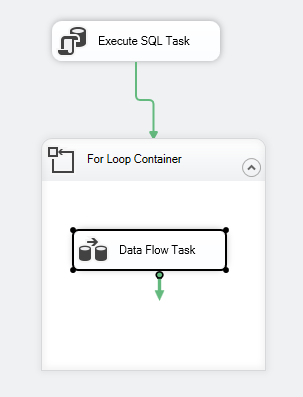
Obrázek 7 – Snímek obrazovky řídicího toku
Omezení
Po ukázce načítání dat po částech pomocí funkce OFFSET FETCH v SSIS si povšimneme, že tato logika má určitá omezení:
- Vždy je třeba použít některé sloupce v klauzuli ORDER BY (nejlépe Identity nebo Primární klíč), protože OFFSET FETCH je funkce klauzule ORDER BY a nelze ji implementovat samostatně
- Pokud při načítání dat dojde k chybě, všechna data exportovaná do cílového místa se odevzdají a vrátí se pouze aktuální kus dat. To může vyžadovat další kroky, aby se zabránilo duplikaci dat při opětovném spuštění balíčku
OFFSET FETCH při použití jiných poskytovatelů databází
V následující části se stručně věnujeme syntaxi používané jinými poskytovateli databází:
Oracle
U společnosti Oracle můžete použít stejnou syntaxi jako u SQL Serveru. Další informace naleznete na následujícím odkazu: Oracle FETCH
SQLite
V SQLite je syntaxe odlišná od SQL Serveru, protože používáte funkci LIMIT OFFSET, jak je uvedeno níže:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
V MySQL, je syntaxe podobná jako v SQLite, protože místo OFFSET Fetch se používá LIMIT OFFSET.
DB2
V DB2 je syntaxe podobná SQLite, protože místo OFFSET FETCH používáte LIMIT OFFSET.
Závěr
V tomto článku jsme popsali funkci OFFSET FETCH, která se nachází v SQL Serveru 2012 a vyšších. Ukázali jsme, jak tuto funkci použít k vytvoření stránkovacího dotazu, a poté jsme poskytli návod krok za krokem, jak načítat data po částech, aby bylo možné extrahovat velké množství dat pomocí stroje s omezenými zdroji. Nakonec jsme zmínili některá omezení a rozdíly v syntaxi oproti jiným poskytovatelům databází.
- Autor
- Poslední příspěvky

Kromě práce s SQL Serverem pracoval s různými datovými technologiemi, jako jsou databáze NoSQL, Hadoop, Apache Spark. Je certifikovaným odborníkem na Neo4j a ArangoDB.
Na akademické úrovni má Hadi dva magisterské tituly v oboru informatiky a podnikové informatiky. V současné době je doktorandem v oboru datové vědy se zaměřením na techniky hodnocení kvality velkých dat.
Hadi se velmi rád každý den učí novým věcem a sdílí své znalosti. Můžete ho kontaktovat na jeho osobních webových stránkách.
Zobrazit všechny příspěvky od Hadi Fadlallah
- Vytváření kostek SSAS OLAP pomocí Bimlu – 16. března, 2021
- Migrace grafových databází SQL Serveru na Neo4j – 9. března 2021
- Začínáme s grafovou databází Neo4j – 5. února 2021