Deskriptive Statistik
Für dieses Tutorial werden wir den autoDatensatz verwenden, der mit Stata geliefert wird. Um diesen Datentyp zu laden
sysuse auto, clearDer Auto-Datensatz hat die folgenden Variablen.
describe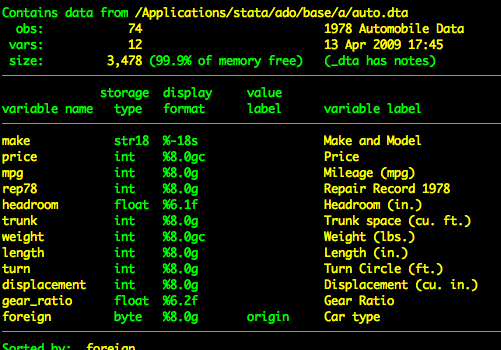
Angenommen, wir möchten einige zusammenfassende Statistiken für den Preis wie den Mittelwert, die Standardabweichung und den Bereich erhalten. Wir verwenden den Befehl summarize.
summarize price
Nun fügen wir die Option detail zu summarize hinzu. Dadurch erhalten wir viele weitere Informationen, einschließlich des Medians und anderer Perzentile.
summarize price, detail
Mehrere Variablen auf einmal
Um Beschreibungen für mehrere Variablen auf einmal zu erhalten, fügen Sie einfach die Variablennamen nach summarize hinzu.
summarize price mpg
Hinzufügen der Option detail.
summarize price mpg, detail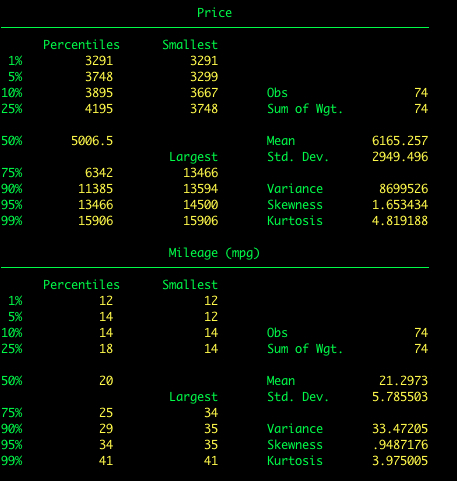
Nutzung durch Verarbeitung
Angenommen, wir möchten die deskriptive Statistik für den Preis nach Autotyp (Ausland vs. Inland) erhalten. Wir können die so genannte byVerarbeitung verwenden.
by foreign: summarize price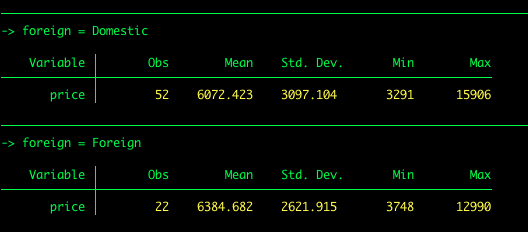
Bei der Verwendung des by-Befehls muss die Variable von Interesse im Datensatz sortiert werden. Im vorigen Beispiel ist die Variable „Ausland“ bereits in unserem Datensatz sortiert. Wenn wir den Preis nach dem Benzinverbrauch untersuchen wollten, müssten wir die Meilen pro Gallone sortieren. Eine Möglichkeit, Daten zu sortieren, ist die Verwendung eines einfachen Sortierbefehls, gefolgt von dem Variablennamen. Stata sortiert die Daten standardmäßig in aufsteigender Reihenfolge.
sort mpgNach dem Sortieren der Daten können wir dann den Standardbefehl „by mpg:“ verwenden. Bei der by-Verarbeitung können wir die Daten auch sortieren und gleichzeitig den by-Befehl ausführen, indem wir den bysort-Befehl verwenden:
bysort mpg: summarize priceDer by-Befehl kann auch in anderen Befehlen verwendet werden, z. B. beim Erstellen von Grafiken. Wenn wir zum Beispiel Histogramme der Kilometerleistung nach Automarke untersuchen wollen, würden wir den Befehl by als Option verwenden. Die Automarke muss für diesen Befehl nicht sortiert werden.
histogram(mpg), by(foreign)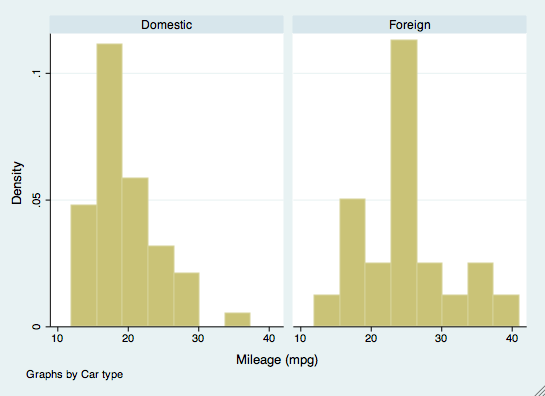
Verwendung von if
Die by-Anweisung liefert uns Beschreibungen für alle Ebenen der by-Variable (d.h. sowohl für ausländische als auch für inländische). Angenommen, wir wollen nur die Beschreibungen für eine Ebene der Variablen by. Hierfür kann die Anweisung if verwendet werden. Für ausländische Autos (d. h. foreign == 1):
summarize price if foreign == 1
Für inländische Autos (d. h., foreign == 0)
summarize price if foreign == 0
Diese Tabelle soll dabei helfen, zu bestimmen, welche Werte der Variablen Sie verwenden wollen.
Symbol |
Bedeutung |
| == | ist oder ist gleich |
| != oder ~= | ist nicht oder ist nicht gleich |
| > | ist größer als |
| >= | ist größer als oder gleich |
| < | ist kleiner als |
| <= | ist kleiner als oder gleich |
| *Aus pg. 74 von A Gentle Introduction to Stata von Alan Acock | |
Verwendung in
Der Qualifizierer in legt eine bestimmte Untergruppe von Fällen auf der Grundlage ihrer Reihenfolge im Datensatz fest. Wenn wir z. B. den Benzinverbrauch der 10 günstigsten Autos untersuchen wollen, würden wir den Befehl in verwenden.
sort pricesummarize mpg in 1/10
Wenn Ihre Variablen beschriftet sind (d. h. die Beschriftung wird anstelle des numerischen Werts angezeigt) und Sie die numerischen Werte finden müssen, um die Niveaus der Variablen zu untersuchen, können Sie die Option nolabel verwenden.
browse, nolabelDamit werden die Zahlenwerte für Variablen angezeigt. Sie können diese Werte auch finden, indem Sie im Datenbrowser auf sie doppelklicken.