In diesem Artikel wird gezeigt, wie das OFFSET FETCH-Feature als Lösung für das Laden großer Datenmengen aus einer relationalen Datenbank auf einem Computer mit begrenztem Speicher verwendet werden kann, um eine Ausnahme wegen Speichermangels zu verhindern. Wir beschreiben, wie man Daten in Stapeln lädt, um zu vermeiden, dass eine große Menge an Daten im Speicher platziert wird.
Dieser Artikel ist der erste in der Reihe SSIS Tipps und Tricks, die darauf abzielt, einige Best Practices zu veranschaulichen.
Einführung
Wenn Sie online nach Problemen im Zusammenhang mit dem SSIS-Datenimport suchen, werden Sie Lösungen finden, die in optimalen Umgebungen oder Tutorials für die Handhabung einer kleinen Datenmenge verwendet werden können. Leider erweisen sich diese Lösungen in einer realen Umgebung als ungeeignet.
In der Realität können kleinere Unternehmen nicht immer neue Speicher-, Verarbeitungsgeräte und Technologien übernehmen, obwohl sie immer größere Datenmengen verarbeiten müssen. Dies gilt insbesondere für die Analyse sozialer Medien, da sie das Verhalten ihrer Zielgruppe (Kunden) analysieren müssen.
Ebenso können nicht alle Unternehmen ihre Daten in die Cloud hochladen, da dies mit hohen Kosten verbunden ist und Fragen des Datenschutzes und der Vertraulichkeit aufwirft.
OFFSET FETCH-Funktion
OFFSET FETCH ist eine Funktion, die der ORDER BY-Klausel ab der SQL Server 2012-Edition hinzugefügt wurde. Sie kann verwendet werden, um eine bestimmte Anzahl von Zeilen ausgehend von einem bestimmten Index zu extrahieren. Ein Beispiel: Wir haben eine Abfrage, die 40 Zeilen zurückgibt und wir müssen 10 Zeilen ab der 10:
|
1
2
3
4
5
|
SELECT *
FROM Tabelle
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
In der Abfrage oben, OFFSET 10 wird verwendet, um 10 Zeilen zu überspringen, und FETCH 10 ROWS ONLY wird verwendet, um nur 10 Zeilen zu extrahieren.
Weitere Informationen über die ORDER BY-Klausel und die OFFSET FETCH-Funktion finden Sie in der offiziellen Dokumentation: Using OFFSET and FETCH to limit the rows returned.
Using OFFSET FETCH to load data in chunks (pagination)
Einer der Hauptzwecke der Verwendung der OFFSET FETCH-Funktion ist das Laden von Daten in Chunks. Nehmen wir an, wir haben eine Anwendung, die eine SQL-Abfrage ausführt und die Ergebnisse auf mehreren Seiten anzeigen muss, wobei jede Seite nur 10 Ergebnisse enthält (ähnlich wie bei der Google-Suchmaschine).
Die folgende Abfrage kann als Paging-Abfrage verwendet werden, wobei @PageSize die Anzahl der Zeilen ist, die in jedem Chunk angezeigt werden sollen, und @PageNumber die Iterationsnummer (Seite) ist:
|
1
2
3
4
5
|
SELECT <Einige Spalten>
FROM <Tabellenname>
ORDER BY <einige Spalten>
OFFSET @Seitengröße * @Seitenzahl ROWS
FETCH NEXT @Seitengröße ROWS ONLY;
|
Dieser Artikel soll nicht alle Anwendungsfälle der Funktion OFFSET FETCH veranschaulichen und geht auch nicht auf bewährte Verfahren ein. Es gibt viele Online-Artikel, in denen Sie weitere Informationen finden können:
- Paginierung mit OFFSET / FETCH : Ein besserer Weg
- Paginierung in SQL Server mit OFFSET / FETCH
Implementierung der OFFSET FETCH-Funktion in SSIS zum Laden großer Datenmengen in Stücken
Wir wurden oft gebeten, ein SSIS-Paket zu erstellen, das eine große Datenmenge von SQL Server mit begrenzten Maschinenressourcen lädt. Das Laden von Daten über die OLE DB-Quelle mit dem Datenzugriffsmodus „Tabelle“ oder „Ansicht“ verursachte eine „Out-of-Memory“-Ausnahme
Eine der einfachsten Lösungen ist die Verwendung des OFFSET FETCH-Features zum Laden von Daten in Chunks, um Fehler durch Speicherüberlastung zu vermeiden. In diesem Abschnitt finden Sie eine schrittweise Anleitung zur Implementierung dieser Logik in einem SSIS-Paket.
Zunächst müssen wir ein neues Integration Services-Paket erstellen und dann vier Variablen wie folgt deklarieren:
- RowCount (Int32): Speichert die Gesamtzahl der Zeilen in der Quelltabelle
- IncrementValue (Int32): Speichert die Anzahl der Zeilen, die wir in der OFFSET-Klausel angeben müssen (ähnlich wie @PageSize * @PageNumber im obigen Beispiel)
- RowsInChunk (Int32): Gibt die Anzahl der Zeilen in den einzelnen Datenpaketen an (ähnlich wie @PageSize im obigen Beispiel)
- SourceQuery (String): Speichert den SQL-Quellbefehl, der zum Abrufen der Daten verwendet wird
Nachdem wir die Variablen deklariert haben, weisen wir einen Standardwert für die Variable RowsInChunk zu; in diesem Beispiel setzen wir ihn auf 1000. Außerdem müssen wir den Ausdruck der Quellabfrage wie folgt festlegen:
|
1
2
3
4
5
|
„SELECT *
FROM ..
ORDER BY
OFFSET “ + (DT_WSTR,50)@ + “ ROWS
FETCH NEXT “ + (DT_WSTR,50) @ + “ ROWS ONLY“
|
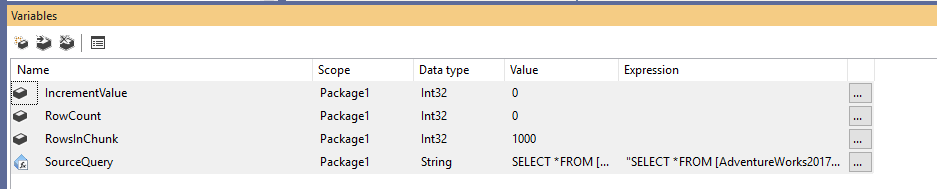
Abbildung 1 – Hinzufügen von Variablen
Als nächstes fügen wir einen Execute SQL Task hinzu, um die Gesamtzahl der Zeilen in der Quelltabelle zu ermitteln. In diesem Beispiel verwenden wir die Tabelle Person, die in der Datenbank AdventureWorks2017 gespeichert ist. Im Execute SQL Task wird die folgende SQL-Anweisung verwendet:
|
1
|
SELECT COUNT(*) FROM ..
|
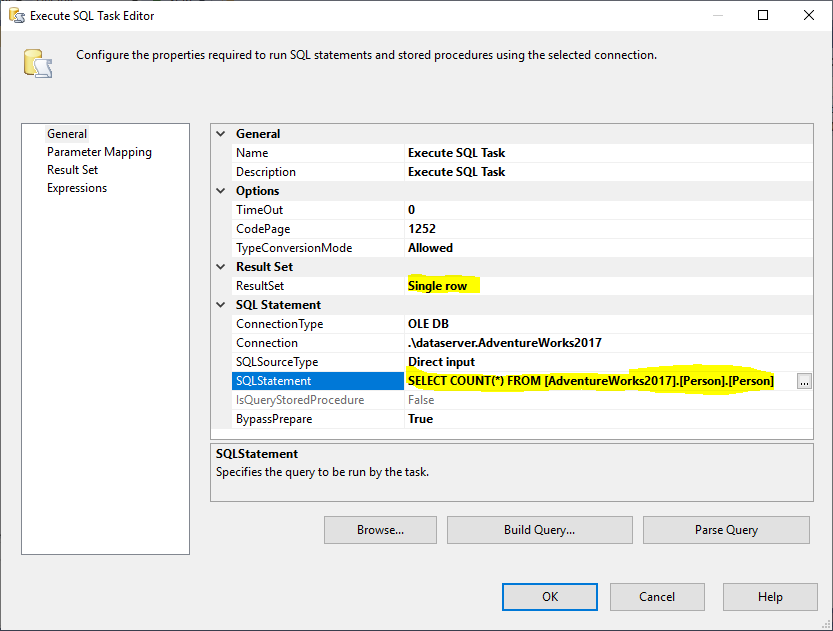
Abbildung 2 – Einstellen von Execute SQL Task
Und, wir müssen die Result Set Eigenschaft auf Single Row ändern. Dann wählen wir auf der Registerkarte Ergebnismenge die Variable RowCount aus, um die Ergebnismenge zu speichern, wie in der folgenden Abbildung gezeigt:
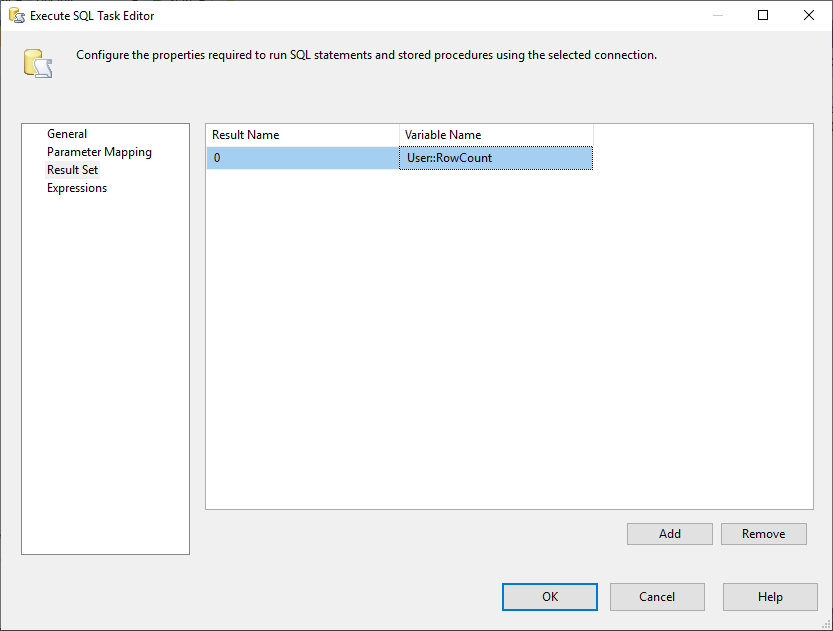
Abbildung 3 – Zuordnen der Ergebnismenge zu einer Variablen
Nach dem Konfigurieren der Execute SQL Task fügen wir einen For Loop Container mit den folgenden Spezifikationen hinzu:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
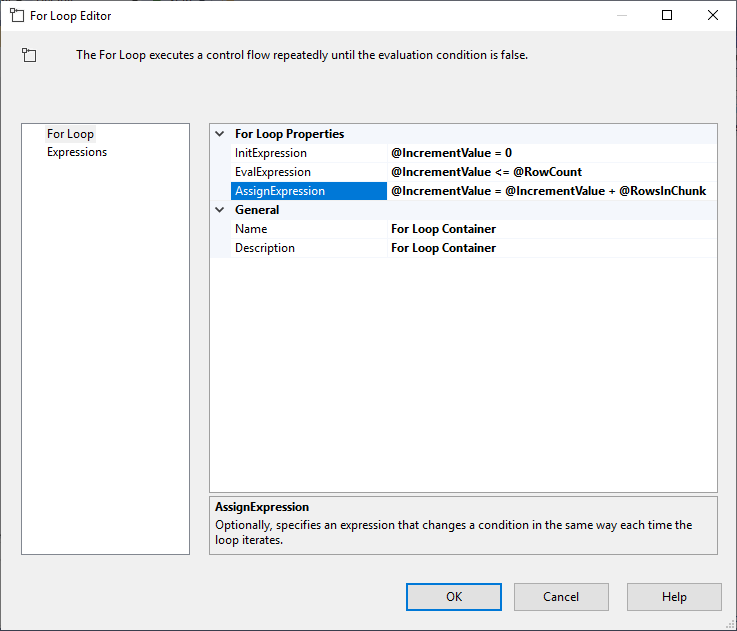
Abbildung 4 – Konfigurieren des For-Loop-Containers
Nach dem Konfigurieren des For-Loop-Containers fügen wir darin eine Datenflussaufgabe hinzu. Dann fügen wir innerhalb der Datenflussaufgabe eine OLE DB-Quelle und ein OLE DB-Ziel hinzu.
In der OLE DB-Quelle wählen wir SQL Command aus dem variablen Datenzugriffsmodus und wählen die Variable @User::SourceQuery als Quelle.
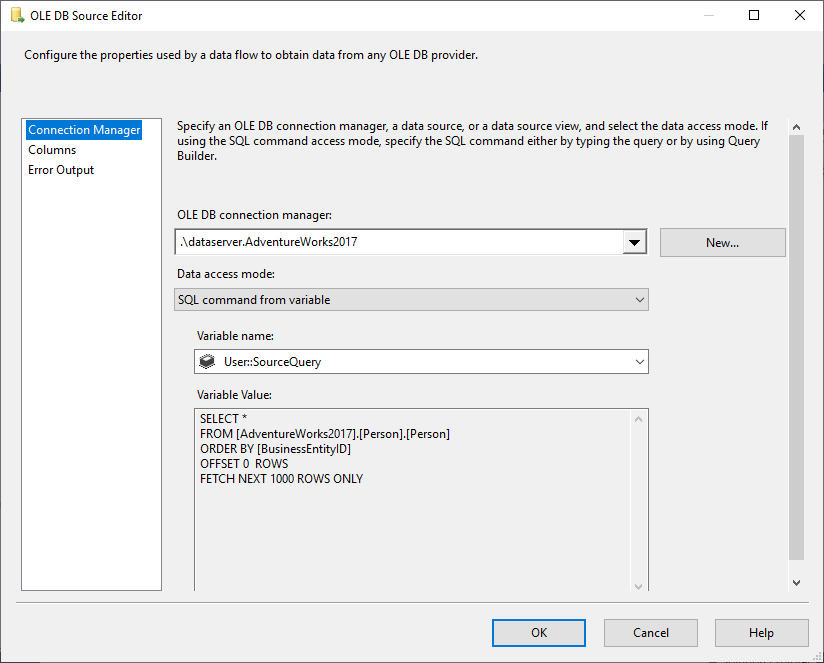
Abbildung 5 – Konfigurieren der OLE DB-Quelle
In der Komponente OLE DB-Ziel geben wir die Zieltabelle an:
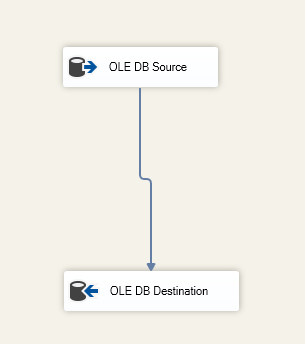
Abbildung 6 – Screenshot der Datenflussaufgabe
Der Kontrollfluss des Pakets sollte wie folgt aussehen:
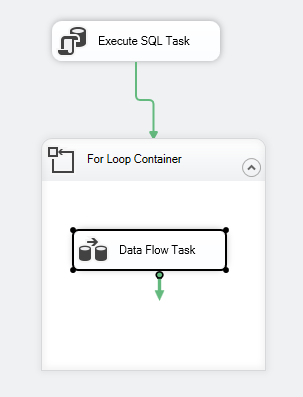
Abbildung 7 – Screenshot des Kontrollflusses
Einschränkungen
Nachdem wir gezeigt haben, wie man Daten mit der Funktion OFFSET FETCH in SSIS in Paketen lädt, werden wir feststellen, dass diese Logik einige Einschränkungen hat:
- Es müssen immer einige Spalten in der ORDER BY-Klausel verwendet werden (bevorzugt Identitäts- oder Primärschlüssel), da OFFSET FETCH eine Funktion der ORDER BY-Klausel ist und nicht separat implementiert werden kann
- Wenn beim Laden von Daten ein Fehler auftritt, werden alle zum Ziel exportierten Daten übertragen und nur der aktuelle Datenblock wird zurückgesetzt. Dies kann zusätzliche Schritte erfordern, um eine Datenduplizierung zu verhindern, wenn das Paket erneut ausgeführt wird
OFFSET FETCH mit anderen Datenbankanbietern
Im folgenden Abschnitt wird kurz auf die Syntax eingegangen, die von anderen Datenbankanbietern verwendet wird:
Oracle
Mit Oracle können Sie die gleiche Syntax wie mit SQL Server verwenden. Unter dem folgenden Link finden Sie weitere Informationen: Oracle FETCH
SQLite
In SQLite ist die Syntax anders als in SQL Server, da Sie die Funktion LIMIT OFFSET wie unten erwähnt verwenden:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
In MySQL, ist die Syntax ähnlich wie bei SQLite, da man LIMIT OFFSET anstelle von OFFSET Fetch verwendet.
DB2
In DB2 ist die Syntax ähnlich wie in SQLite, da Sie LIMIT OFFSET anstelle von OFFSET FETCH verwenden.
Abschluss
In diesem Artikel haben wir die Funktion OFFSET FETCH in SQL Server 2012 und höher beschrieben. Wir haben veranschaulicht, wie diese Funktion verwendet wird, um eine Auslagerungsabfrage zu erstellen, und dann eine Schritt-für-Schritt-Anleitung zum Laden von Daten in Blöcken gegeben, um das Extrahieren großer Datenmengen auf einem Rechner mit begrenzten Ressourcen zu ermöglichen. Abschließend wurden einige Einschränkungen und Syntaxunterschiede zu anderen Datenbankanbietern erwähnt.
- Autor
- Recent Posts

Neben der Arbeit mit SQL Server hat er mit verschiedenen Datentechnologien wie NoSQL-Datenbanken, Hadoop und Apache Spark gearbeitet. Er ist ein zertifizierter Neo4j- und ArangoDB-Experte.
Auf akademischer Ebene hat Hadi zwei Master-Abschlüsse in Informatik und Wirtschaftsinformatik. Derzeit ist er Doktorand in Datenwissenschaft mit Schwerpunkt auf Techniken zur Qualitätsbewertung von Big Data.
Hadi hat wirklich Spaß daran, jeden Tag neue Dinge zu lernen und sein Wissen zu teilen. Sie können ihn über seine persönliche Website erreichen.
Alle Beiträge von Hadi Fadlallah anzeigen
- SSAS OLAP-Würfel mit Biml erstellen – März 16, 2021
- Migrieren von SQL Server-Graphdatenbanken zu Neo4j – 9. März 2021
- Erste Schritte mit der Neo4j-Graphdatenbank – 5. Februar 2021