Neste artigo, ilustramos como usar o recurso OFFSET FETCH como uma solução para carregar grandes volumes de dados de uma base de dados relacional usando uma máquina com memória limitada e evitando uma exceção fora da memória. Descrevemos como carregar dados em lotes para evitar colocar uma grande quantidade de dados na memória.
Este artigo é o primeiro da série Dicas e Truques SSIS que visa ilustrar algumas melhores práticas.
Introdução
Ao pesquisar online por problemas relacionados à importação de dados SSIS, você encontrará soluções que podem ser usadas em ambientes ótimos ou tutoriais para lidar com uma pequena quantidade de dados. Infelizmente, estas soluções revelam-se inadequadas num ambiente real.
Na realidade, as empresas mais pequenas nem sempre podem adoptar novos equipamentos de armazenamento, processamento e tecnologias, embora ainda tenham de lidar com uma quantidade crescente de dados. Isto é especialmente verdade para a análise das mídias sociais, pois elas devem analisar o comportamento de seu público-alvo (clientes).
Da mesma forma, nem todas as empresas podem carregar seus dados na nuvem devido ao alto custo, juntamente com questões de privacidade e confidencialidade dos dados.
OFFSET FETCH feature
OFFSET FETCH é uma funcionalidade adicionada à cláusula ORDER BY, que começa com a edição 2012 do SQL Server. Ele pode ser usado para extrair um número específico de linhas a partir de um índice específico. Como exemplo, temos uma consulta que retorna 40 linhas e precisamos extrair 10 linhas a partir da 10ª linha:
|
1
2
3
4
5
|
SELECCIONAR *
FROM Tabela
ORDEM POR ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS APENAS
|
Na consulta acima, OFFSET 10 é usado para saltar 10 linhas e FETCH 10 ROWS APENAS é usado para extrair apenas 10 linhas.
Para obter informações adicionais sobre a cláusula ORDER BY e a funcionalidade OFFSET FETCH, consulte a documentação oficial: Usando OFFSET e FETCH para limitar as linhas retornadas.
Usando OFFSET FETCH para carregar dados em pedaços (paginação)
Uma das principais finalidades de usar a funcionalidade OFFSET FETCH é carregar dados em pedaços. Imaginemos que temos uma aplicação que executa uma consulta SQL e precisa de mostrar os resultados em várias páginas onde cada página contém apenas 10 resultados (semelhante ao motor de busca do Google).
A seguinte consulta pode ser usada como uma consulta de paginação onde @PageSize é o número de linhas que você precisa mostrar em cada trecho e @PageNumber é o número de iteração (página):
|
1
2
3
4
5
|
SELECT <algumas colunas>
DE < nome da tabela>
ORDEM POR <algumas colunas>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Este artigo não pretende ilustrar todos os casos de uso do recurso OFFSET FETCH, nem discutir as melhores práticas. Existem muitos artigos online que pode consultar para mais informações:
- Paginação com OFFSET / FETCH : Uma maneira melhor
- Paginação no SQL Server usando OFFSET / FETCH
Implementar a funcionalidade OFFSET FETCH dentro do SSIS para carregar um grande volume de dados em pedaços
Muitas vezes foi-nos pedido para construir um pacote SSIS que carrega uma enorme quantidade de dados do SQL Server com recursos limitados da máquina. Carregar dados usando OLE DB Source usando o modo Table ou View data access estava causando uma exceção à memória.
Uma das soluções mais fáceis é usar a função OFFSET FETCH para carregar dados em pedaços para evitar erros de falta de memória. Nesta seção, nós fornecemos um guia passo a passo sobre a implementação desta lógica dentro de um pacote SSIS.
Primeiro, devemos criar um novo pacote de Serviços de Integração, depois declarar quatro variáveis como segue:
- RowCount (Int32): Armazena o número total de linhas na tabela de origem
- IncrementValue (Int32): Armazena o número de linhas que precisamos especificar na cláusula OFFSET (similar a @PageSize * @PageNumber no exemplo acima)
- RowsInChunk (Int32): Especifica o número de linhas em cada pedaço de dados (similar a @PageSize no exemplo acima)
- SourceQuery (String): Armazena o comando SQL de origem usado para buscar dados
Após declarar as variáveis, nós atribuímos um valor padrão para a variável RowsInChunk; neste exemplo, nós a configuraremos para 1000. Além disso, devemos definir a expressão Source Query, como segue:
|
1
2
3
4
5
|
“SELECT *
> FROM …
ENCOMENDAR POR
OFFSET ” + (DT_WSTR,50)@ + ” LINHAS
BUSCAR A SEGUIR ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
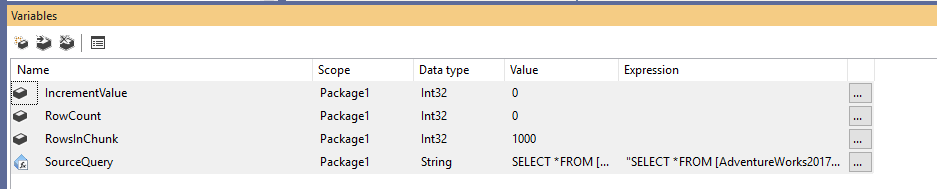
Figura 1 – Adicionando variáveis
A seguir, adicionamos uma Tarefa Executar SQL para obter o número total de linhas na tabela de origem. Neste exemplo, usamos a tabela Person armazenada na base de dados AdventureWorks2017. Na tarefa Execute SQL, usamos a seguinte instrução SQL:
|
1
|
SELECT COUNT(*) FROM …
|
>
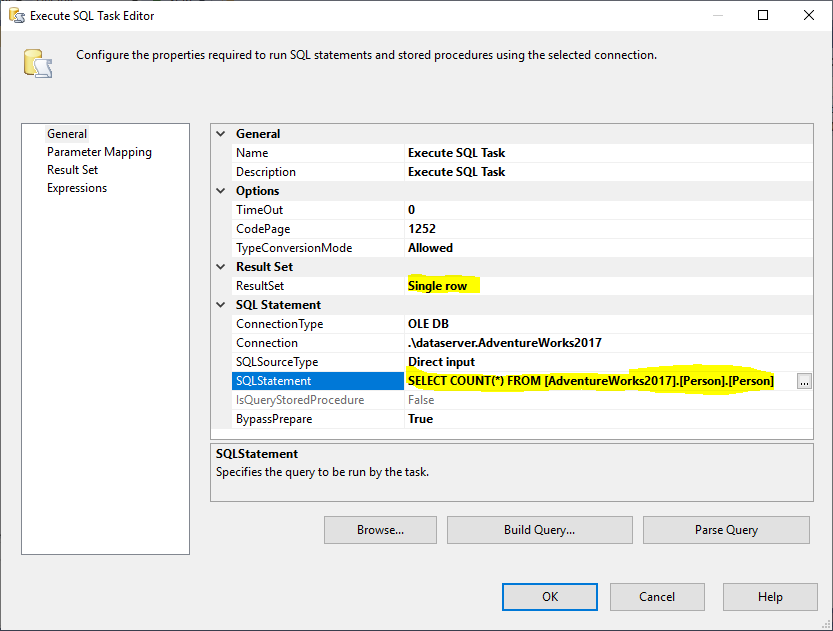
Figura 2 – Configuração da Tarefa Executar SQL
E, devemos alterar a propriedade Definir Resultado para Fila Única. Em seguida, na aba Result Set, selecionamos a variável RowCount para armazenar o resultado definido como mostrado na imagem abaixo:
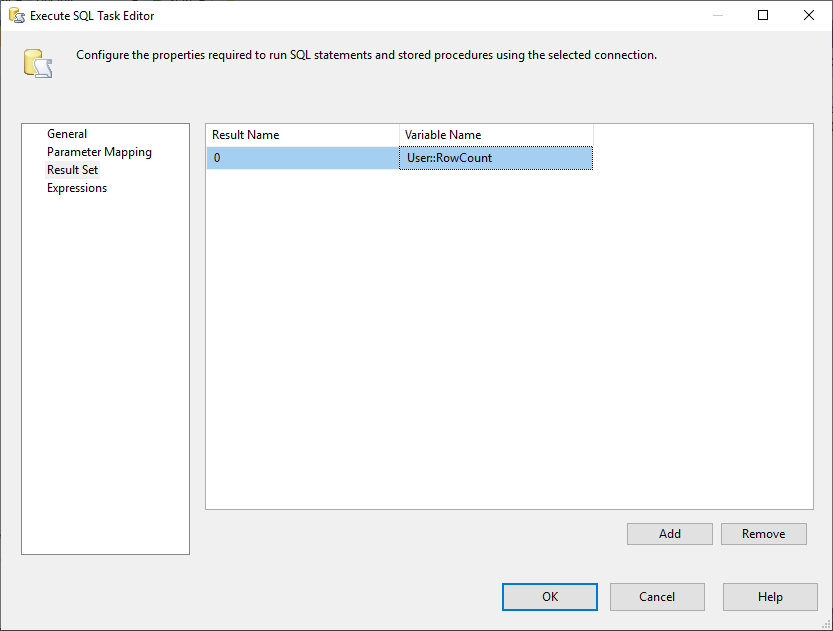
Figura 3 – Mapeamento do resultado definido como variável
Após configurar a Tarefa Execute SQL, adicionamos um For Loop Container, com as seguintes especificações:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
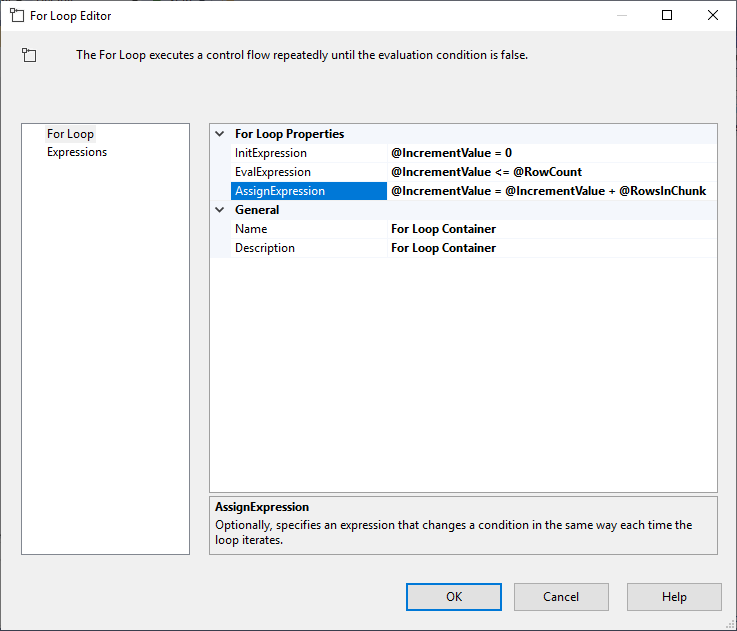
Figura 4 – Configurando para container de loop
Após configurar o For Loop Container, adicionamos uma tarefa de fluxo de dados dentro dele. Então, dentro da tarefa de fluxo de dados, adicionamos uma Fonte OLE DB e Destino OLE DB.
Na Fonte OLE DB selecionamos o comando SQL do modo de acesso a dados variáveis, e selecionamos @User::SourceQuery variável como a fonte.
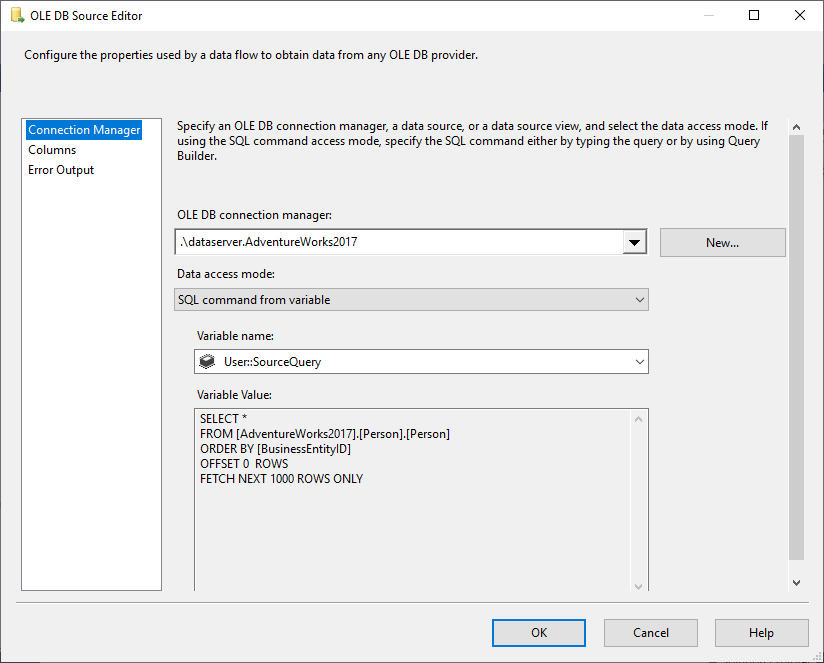
Figura 5 – Configuração da fonte OLE DB
Especificamos a tabela de destino dentro do componente OLE DB Destination:
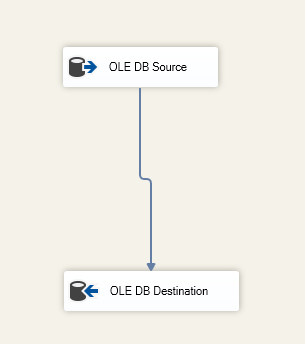
Figura 6 – Tela de tarefa de fluxo de dados
O fluxo de controle de pacotes deve se parecer com o seguinte:
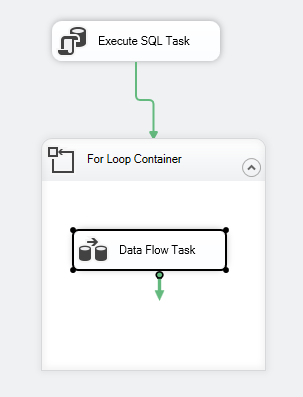
Figura 7 – Tela de controle de fluxo de dados
Limitações
Depois de ilustrar como carregar dados em pedaços usando a função OFFSET FETCH no SSIS, vamos notar que esta lógica tem algumas limitações:
- Você sempre precisa de algumas colunas para serem usadas na cláusula ORDER BY (Prefere-se a chave Identity ou Primary), já que OFFSET FETCH é uma característica da cláusula ORDER BY e não pode ser implementada separadamente
- Se ocorrer um erro durante o carregamento dos dados, todos os dados exportados para o destino são comprometidos e apenas o pedaço de dados atual é revertido para trás. Isto pode requerer passos adicionais para evitar a duplicação de dados ao executar o pacote novamente
OFFSET FETCH usando outros provedores de banco de dados
Na seção seguinte, nós cobrimos brevemente a sintaxe usada por outros provedores de banco de dados:
Oracle
Com Oracle, você pode usar a mesma sintaxe do SQL Server. Consulte o seguinte link para obter mais informações: Oracle FETCH
SQLite
Em SQLite, a sintaxe é diferente da do SQL Server, já que você usa o recurso LIMIT OFFSET, como mencionado abaixo:
|
1
2
3
|
SELECCIONAR * DO MYTABLE ORDEM POR ID_COLUME
LIMIT 50
OFFSET 10
|
MySQL
No MySQL, a sintaxe é semelhante ao SQLite, uma vez que se utiliza o LIMIT OFFSET em vez do OFFSET Fetch.
DB2
No DB2, a sintaxe é semelhante à do SQLite, uma vez que utiliza o LIMIT OFFSET em vez do OFFSET FETCH.
Conclusion
Neste artigo, descrevemos a funcionalidade OFFSET FETCH encontrada no SQL Server 2012 e superiores. Ilustramos como usar este recurso para criar uma consulta de paging, depois fornecemos um guia passo a passo sobre como carregar dados em pedaços para permitir extrair grandes quantidades de dados usando uma máquina com recursos limitados. Finalmente, mencionamos algumas das limitações e diferenças de sintaxe com outros provedores de banco de dados.
- Autor
- Recent Posts

Além de trabalhar com SQL Server, ele trabalhou com diferentes tecnologias de dados como bancos de dados NoSQL, Hadoop, Apache Spark. Ele é um profissional certificado Neo4j e ArangoDB.
No nível acadêmico, Hadi tem dois mestrados em ciência da computação e computação empresarial. Atualmente, ele é candidato a Ph.D. em ciência de dados com foco em técnicas de avaliação de qualidade de Grandes Dados.
Hadi realmente gosta de aprender coisas novas todos os dias e compartilhar seus conhecimentos. Você pode alcançá-lo em seu site pessoal.
Veja todos os posts de Hadi Fadlallah
- Construir cubos SSAS OLAP usando Biml – 16 de Março, 2021
- Migração de bases de dados gráficos do SQL Server para o Neo4j – 9 de Março de 2021
- Começar com a base de dados gráficos do Neo4j – 5 de Fevereiro de 2021