Descriptieve Statistieken
Voor deze tutorial gaan we gebruik maken van de auto dataset die met Stata wordt meegeleverd. Om deze dataset te laden
sysuse auto, clearDe auto dataset heeft de volgende variabelen.
describe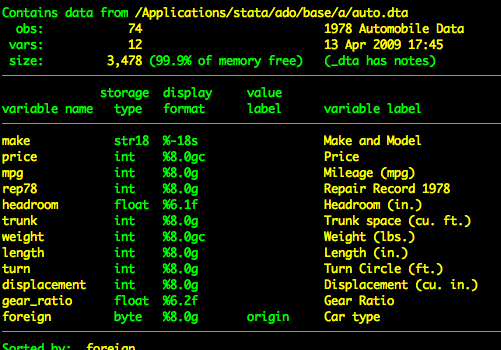
Voorstel dat we enkele samenvattende statistieken voor de prijs willen verkrijgen, zoals het gemiddelde, de standaardafwijking, en het bereik. We gebruiken daarvoor het commando summarize.
summarize price
Nu voegen we de optie detail toe aan summarize. Dit geeft ons veel meer informatie, waaronder de mediaan en andere percentielen.
summarize price, detail
Meerdere variabelen tegelijk
Om beschrijvingen voor meerdere variabelen tegelijk te krijgen, voegt u de variabelenamen toe na summarize.
summarize price mpg
Door de optie detail toe te voegen.
summarize price mpg, detail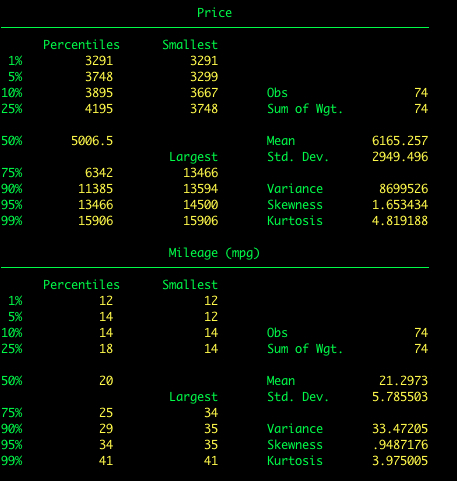
Gebruik door verwerking
Voor stel dat we de beschrijvende statistieken voor de prijs per autotype (buitenlands vs binnenlands) willen krijgen. We kunnen gebruik maken van wat wordt genoemd byverwerking.
by foreign: summarize price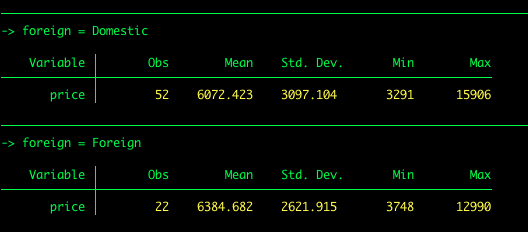
Wanneer we het commando by gebruiken, moet de variabele van belang in de gegevensreeks worden gesorteerd. In het vorige voorbeeld is de variabele “buitenland” bijvoorbeeld al gesorteerd binnen onze gegevensreeks. Indien we de prijs per liter brandstof willen onderzoeken, moeten we het aantal kilometer per liter sorteren. Een manier om gegevens te sorteren is met behulp van een eenvoudig sort commando gevolgd door de variabele naam. Stata sorteert de gegevens standaard in oplopende volgorde.
sort mpgNadat we de gegevens hebben gesorteerd, kunnen we vervolgens de standaard opdracht by mpg: gebruiken. In by-bewerking kunnen we de gegevens ook sorteren en tegelijkertijd de by-opdracht uitvoeren met de bysort-opdracht:
bysort mpg: summarize priceDe by-opdracht kan ook worden gebruikt in andere opdrachten, zoals het maken van grafieken. Als we bijvoorbeeld histogrammen van het aantal km/u per automerk willen onderzoeken, zouden we het by-commando als optie gebruiken. Het merk van de auto hoeft voor deze opdracht niet te worden gesorteerd.
histogram(mpg), by(foreign)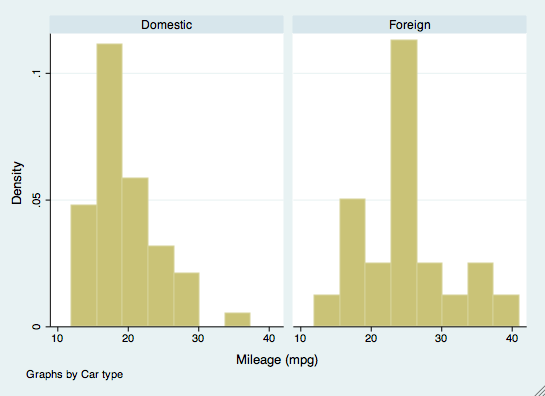
Gebruik van if
Het by-commando geeft ons beschrijvingen voor alle niveaus van de by-variabele (d.w.z. zowel buitenlands als binnenlands). Stel dat we alleen de beschrijvingen voor één niveau van de variabele by willen. Daarvoor kunnen we het if-commando gebruiken. Voor buitenlandse auto’s (d.w.z., foreign == 1):
summarize price if foreign == 1
Voor binnenlandse auto’s (d.w.z., foreign == 0)
summarize price if foreign == 0
Deze tabel is bedoeld als hulp bij het bepalen van de niveaus van de variabele die u wilt gebruiken.
Symbool |
Betekenis |
| == | is of is gelijk aan |
| != of ~= | is niet of is niet gelijk aan |
| > | is groter dan |
| >= | is groter dan of gelijk aan |
| < | is kleiner dan |
| <= | is kleiner dan of gelijk aan |
| *Van pg. 74 van A Gentle Introduction to Stata door Alan Acock | |
Gebruik in
De qualifier in specificeert een bepaalde subset van gevallen op basis van hun volgorde in de dataset. Als we bijvoorbeeld het brandstofverbruik van de 10 minst dure auto’s willen onderzoeken, gebruiken we het in-commando.
sort pricesummarize mpg in 1/10
Als een handige hint voor elk van deze processen, als uw variabelen zijn gelabeld (met het label in plaats van de numerieke waarde) en u de numerieke waarden moet vinden om de niveaus van de variabele te onderzoeken, kunt u de optie nolabel gebruiken.
browse, nolabelDit toont u de numerieke waarden voor variabelen. U kunt deze waarden ook vinden door erop te dubbelklikken in de gegevensbrowser.