In dit artikel laten we zien hoe u de OFFSET FETCH-feature kunt gebruiken als oplossing voor het laden van grote hoeveelheden gegevens uit een relationele database met een machine met beperkt geheugen en het voorkomen van een exception (uitzondering) voor het opraken van het geheugen. We beschrijven hoe gegevens in batches kunnen worden geladen om te voorkomen dat een grote hoeveelheid gegevens in het geheugen wordt geplaatst.
Dit artikel is het eerste in de SSIS Tips and Tricks serie die tot doel heeft een aantal best practices te illustreren.
Inleiding
Wanneer u online zoekt naar problemen met betrekking tot SSIS-gegevensimport, vindt u oplossingen die kunnen worden gebruikt in optimale omgevingen of tutorials voor het verwerken van een kleine hoeveelheid gegevens. Helaas blijken deze oplossingen in een echte omgeving ongeschikt te zijn.
In werkelijkheid kunnen kleinere bedrijven niet altijd nieuwe opslag-, verwerkingsapparatuur en technologieën invoeren, hoewel ze toch een toenemende hoeveelheid gegevens moeten verwerken. Dit geldt met name voor social media-analyse, omdat ze het gedrag van hun doelgroep (klanten) moeten analyseren.
Evenzo kunnen niet alle bedrijven hun gegevens uploaden naar de cloud vanwege de hoge kosten in combinatie met privacy- en vertrouwelijkheidskwesties.
OFFSET FETCH-functie
OFFSET FETCH is een functie die is toegevoegd aan de ORDER BY-clausule die begint met de SQL Server 2012-editie. Het kan worden gebruikt om een specifiek aantal rijen te extraheren vanaf een specifieke index. Als voorbeeld, we hebben een query die 40 rijen retourneert en we moeten 10 rijen extraheren vanaf de 10e rij:
|
1
2
3
4
5
|
SELECT *
FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
In de bovenstaande query wordt OFFSET 10 gebruikt om de volgende 10 rijen over te slaan, OFFSET 10 wordt gebruikt om 10 rijen over te slaan en FETCH 10 ROWS ONLY wordt gebruikt om slechts 10 rijen te extraheren.
Voor meer informatie over de ORDER BY-clausule en de OFFSET FETCH-functie raadpleegt u de officiële documentatie: Using OFFSET and FETCH to limit the rows returned.
Using OFFSET FETCH to load data in chunks (pagination)
Een van de belangrijkste doelen van het gebruik van de OFFSET FETCH-functie is om gegevens in chunks te laden. Stel dat we een toepassing hebben die een SQL-query uitvoert en de resultaten op verschillende pagina’s moet tonen, waarbij elke pagina slechts 10 resultaten bevat (vergelijkbaar met de Google-zoekmachine).
De volgende query kan worden gebruikt als een paging-query waarbij @PageSize het aantal rijen is dat in elke chunk moet worden getoond en @PageNumber het iteratie (pagina) nummer is:
|
1
2
3
4
5
|
SELECT <sommige kolommen>
FROM <tabellennaam>
ORDER BY <sommige kolommen>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Dit artikel is niet bedoeld om alle gebruikssituaties van de OFFSET FETCH-functie te illustreren, en gaat ook niet in op best practices. Er staan veel artikelen online waarnaar u kunt verwijzen voor meer informatie:
- Pagineren met OFFSET / FETCH : Een betere manier
- Paginatie in SQL Server met behulp van OFFSET / FETCH
Implementeren van de OFFSET FETCH-functie binnen SSIS om een groot volume aan gegevens in brokken te laden
Er is ons vaak gevraagd om een SSIS-pakket te bouwen dat een enorme hoeveelheid gegevens uit SQL Server laadt met beperkte machinebronnen. Het laden van gegevens met behulp van OLE DB Source met Table of View data access mode veroorzaakte een out of memory exception.
Een van de eenvoudigste oplossingen is om de OFFSET FETCH functie te gebruiken om gegevens in chunks te laden om geheugenuitvalfouten te voorkomen. In dit gedeelte geven we een stap-voor-stap handleiding voor het implementeren van deze logica in een SSIS-pakket.
Eerst moeten we een nieuw Integratie Services-pakket maken en vervolgens vier variabelen als volgt declareren:
- RowCount (Int32): Slaat het totaal aantal rijen in de brontabel op
- IncrementValue (Int32): Slaat het aantal rijen op dat we moeten opgeven in de OFFSET-clausule (vergelijkbaar met @PageSize * @PageNumber in het voorbeeld hierboven)
- RowsInChunk (Int32): Specificeert het aantal rijen in elke gegevensbrok (Vergelijkbaar met @PageSize in het bovenstaande voorbeeld)
- SourceQuery (String): Slaat de bron SQL-opdracht op die wordt gebruikt om gegevens op te halen
Na het declareren van de variabelen wijzen we een standaardwaarde toe voor de variabele RowsInChunk; in dit voorbeeld stellen we die in op 1000. Verder moeten we de Source Query expressie instellen, als volgt:
|
1
2
3
4
5
|
“SELECT *
FROM …
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
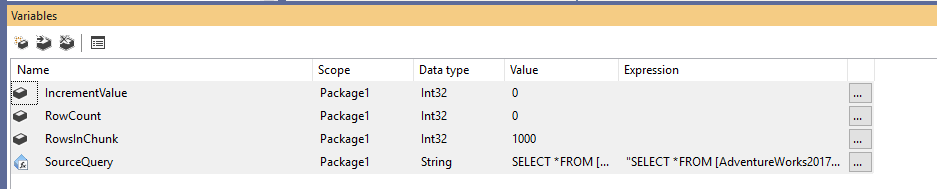
Figuur 1 – Variabelen toevoegen
Vervolgens voegen we een Execute SQL Task toe om het totale aantal rijen in de brontabel te verkrijgen. In dit voorbeeld gebruiken we de tabel Person die opgeslagen is in de AdventureWorks2017 database. In de Execute SQL Task hebben we de volgende SQL Statement gebruikt:
|
1
|
SELECT COUNT(*) FROM …
|
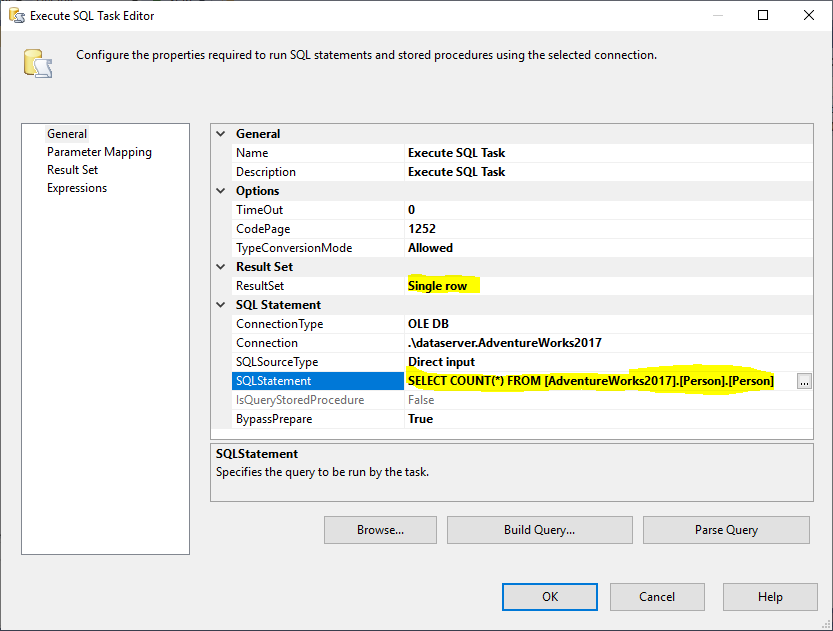
Figure 2 – Setting Execute SQL Task
En, we moeten de eigenschap Result Set wijzigen in Single Row. Vervolgens selecteren we in het tabblad Resultaatset de variabele RowCount om de resultaatset op te slaan, zoals weergegeven in de onderstaande afbeelding:
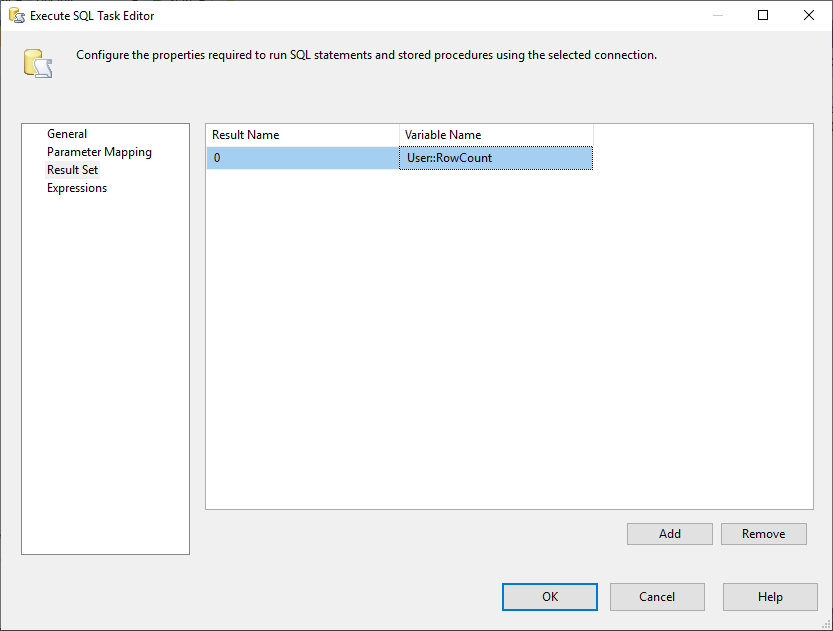
Afbeelding 3 – Resultaatset toewijzen aan variabele
Na het configureren van de Execute SQL Task, voegen we een For Loop Container toe, met de volgende specificaties:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
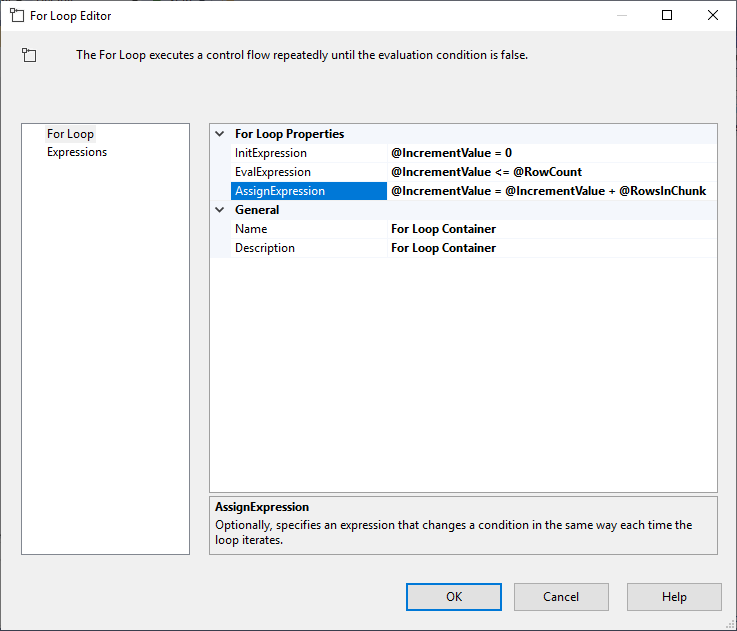
Figuur 4 – Configuratie van de For Loop-container
Nadat we de For Loop-container hebben geconfigureerd, voegen we er een Data Flow Task aan toe. Vervolgens voegen we binnen de Data Flow Task een OLE DB Source en OLE DB Destination toe.
In de OLE DB Source selecteren we SQL Command uit variable data access mode, en selecteren @User::SourceQuery variabele als de bron.
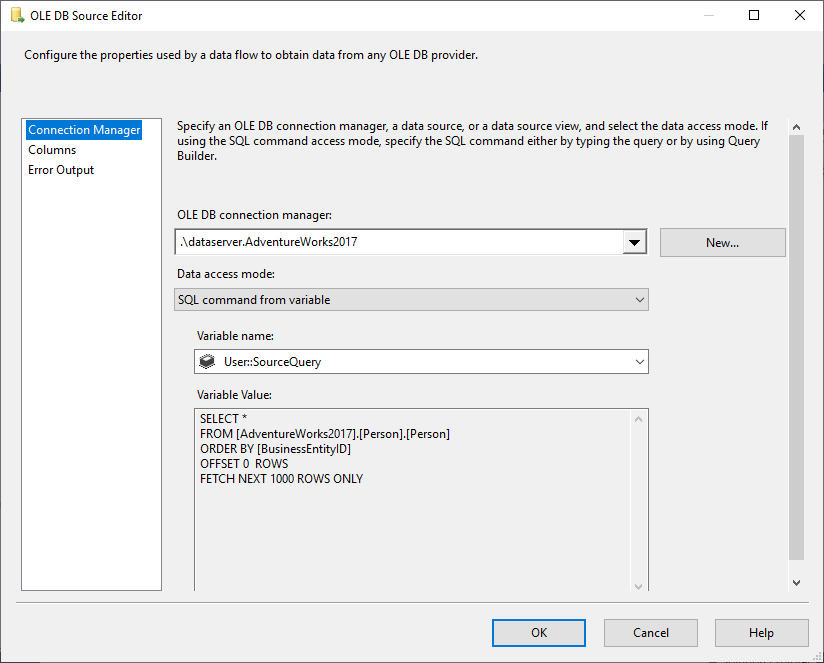
Figuur 5 – Configuratie OLE DB bron
We specificeren de bestemmingstabel in de OLE DB Bestemmingscomponent:
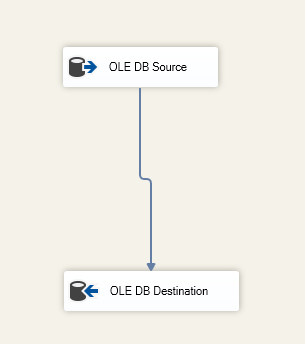
Figuur 6 – Gegevensstroom taak screenshot
De pakketbesturingsstroom zou er als volgt uit moeten zien:
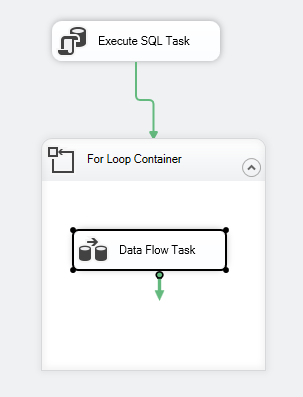
Figuur 7 – Control flow screenshot
Beperkingen
Nadat we hebben geïllustreerd hoe u gegevens in chunks kunt laden met behulp van de OFFSET FETCH-functie in SSIS, zullen we opmerken dat deze logica enkele beperkingen heeft:
- U moet altijd enkele kolommen gebruiken in de ORDER BY-clausule (Identity of Primary key heeft de voorkeur), omdat OFFSET FETCH een functie is van de ORDER BY-clausule en deze niet afzonderlijk kan worden geïmplementeerd
- Als er een fout optreedt tijdens het laden van gegevens, worden alle gegevens die naar de bestemming zijn geëxporteerd, vastgelegd en wordt alleen de huidige chunk van gegevens teruggerold. Dit kan extra stappen vereisen om te voorkomen dat gegevens worden gedupliceerd wanneer het pakket opnieuw wordt uitgevoerd
OFFSET FETCH met behulp van andere database providers
In de volgende sectie behandelen we kort de syntaxis die door andere database providers wordt gebruikt:
Oracle
Met Oracle kunt u dezelfde syntaxis gebruiken als met SQL Server. Raadpleeg de volgende link voor meer informatie: Oracle FETCH
SQLite
Bij SQLite is de syntaxis anders dan bij SQL Server, omdat u de LIMIT OFFSET functie gebruikt zoals hieronder vermeld:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
In MySQL, is de syntaxis vergelijkbaar met die van SQLite, omdat u LIMIT OFFSET gebruikt in plaats van OFFSET Fetch.
DB2
In DB2 is de syntaxis vergelijkbaar met die van SQLite, omdat u LIMIT OFFSET gebruikt in plaats van OFFSET FETCH.
Conclusie
In dit artikel hebben we de OFFSET FETCH-functie beschreven die in SQL Server 2012 en hoger is te vinden. We hebben geïllustreerd hoe deze functie te gebruiken om een paging query te maken, daarna hebben we een stap-voor-stap handleiding gegeven voor het laden van gegevens in chunks om grote hoeveelheden gegevens te kunnen extraheren met een machine met beperkte middelen. Tot slot noemden we enkele beperkingen en de verschillen in syntaxis met andere databaseproviders.
- Auteur
- Recent Posts

Naast het werken met SQL Server, werkte hij met verschillende data-technologieën, zoals NoSQL databases, Hadoop, Apache Spark. Hij is een Neo4j en ArangoDB gecertificeerde professional.
Op academisch niveau heeft Hadi twee masterdiploma’s in informatica en bedrijfscomputing. Momenteel is hij een Ph.D. kandidaat in data science gericht op Big Data kwaliteitsbeoordelingstechnieken.
Hadi vindt het erg leuk om elke dag nieuwe dingen te leren en zijn kennis te delen. Je kunt hem bereiken op zijn persoonlijke website.
Bekijk alle berichten van Hadi Fadlallah
- Bouwen van SSAS OLAP kubussen met behulp van Biml – 16 maart, 2021
- SQL Server grafische databases migreren naar Neo4j – 9 maart 2021
- Aan de slag met de Neo4j grafische database – 5 februari 2021