În acest articol, ilustrăm cum să folosim caracteristica OFFSET FETCH ca soluție pentru încărcarea unor volume mari de date dintr-o bază de date relațională utilizând o mașină cu memorie limitată și prevenind o excepție de lipsă de memorie. Descriem modul de încărcare a datelor în loturi pentru a evita plasarea unei cantități mari de date în memorie.
Acest articol este primul din seria Sfaturi și trucuri SSIS care își propune să ilustreze unele dintre cele mai bune practici.
Introducere
Atunci când căutați online probleme legate de importul de date SSIS, veți găsi soluții care pot fi utilizate în medii optime sau tutoriale pentru manipularea unei cantități mici de date. Din păcate, aceste soluții se dovedesc a fi nepotrivite într-un mediu real.
În realitate, companiile mai mici nu pot adopta întotdeauna noi echipamente și tehnologii de stocare, de procesare, deși trebuie să gestioneze o cantitate tot mai mare de date. Acest lucru este valabil mai ales în cazul analizei social media, deoarece acestea trebuie să analizeze comportamentul publicului lor țintă (clienți).
În mod similar, nu toate companiile își pot încărca datele în cloud din cauza costurilor ridicate, împreună cu problemele legate de confidențialitatea și confidențialitatea datelor.
Caracteristica OFFSET FETCH
OFFSET FETCH este o caracteristică adăugată la clauza ORDER BY începând cu ediția SQL Server 2012. Aceasta poate fi utilizată pentru a extrage un anumit număr de rânduri pornind de la un anumit index. Ca exemplu, avem o interogare care returnează 40 de rânduri și trebuie să extragem 10 rânduri de la al 10-lea rând:
|
1
2
3
4
5
|
SELECT *
. FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
În interogarea de mai sus, OFFSET 10 este utilizată pentru a sări 10 rânduri și FETCH 10 ROWS ONLY este utilizată pentru a extrage doar 10 rânduri.
Pentru a obține informații suplimentare despre clauza ORDER BY și caracteristica OFFSET FETCH, consultați documentația oficială: Utilizarea OFFSET și FETCH pentru a limita rândurile returnate.
Utilizarea OFFSET FETCH pentru a încărca datele în bucăți (paginare)
Unul dintre scopurile principale ale utilizării funcției OFFSET FETCH este încărcarea datelor în bucăți. Să ne imaginăm că avem o aplicație care execută o interogare SQL și trebuie să afișeze rezultatele pe mai multe pagini în care fiecare pagină conține doar 10 rezultate (similar cu motorul de căutare Google).
Următoarea interogare poate fi utilizată ca o interogare de paginare în care @PageSize este numărul de rânduri pe care trebuie să le afișați în fiecare bucată, iar @PageNumber este numărul iterației (paginii):
|
1
2
3
4
5
|
SELECT <anumite coloane>.
FROM <table name>
ORDER BY <unele coloane>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Acest articol nu are scopul de a ilustra toate cazurile de utilizare a funcției OFFSET FETCH și nici nu discută cele mai bune practici. Există multe articole online la care vă puteți referi pentru mai multe informații:
- Paginare cu OFFSET / FETCH : O modalitate mai bună
- Paginare în SQL Server folosind OFFSET / FETCH
Implementarea caracteristicii OFFSET FETCH în cadrul SSIS pentru a încărca un volum mare de date în bucăți
Ni s-a cerut adesea să construim un pachet SSIS care să încarce un volum mare de date din SQL Server cu resurse limitate ale mașinii. Încărcarea datelor cu ajutorul sursei OLE DB folosind modul de acces la date Table sau View provoca o excepție de lipsă de memorie.
Una dintre cele mai simple soluții este utilizarea funcției OFFSET FETCH pentru a încărca datele în bucăți pentru a preveni erorile de lipsă de memorie. În această secțiune, oferim un ghid pas cu pas pentru implementarea acestei logici în cadrul unui pachet SSIS.
Mai întâi, trebuie să creăm un nou pachet Integration Services, apoi să declarăm patru variabile după cum urmează:
- RowCount (Int32): Stochează numărul total de rânduri din tabelul sursă
- IncrementValue (Int32): Stochează numărul de rânduri pe care trebuie să le specificăm în clauza OFFSET (similar cu @PageSize * @PageNumber din exemplul de mai sus)
- RowsInChunk (Int32): Specifică numărul de rânduri din fiecare bucată de date (Similar cu @PageSize în exemplul de mai sus)
- SourceQuery (String): Stochează comanda SQL sursă utilizată pentru a prelua datele
După declararea variabilelor, atribuim o valoare implicită pentru variabila RowsInChunk; în acest exemplu, o vom seta la 1000. În plus, trebuie să setăm expresia Source Query, după cum urmează:
|
1
2
3
4
5
|
„SELECT *
FROM ….
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
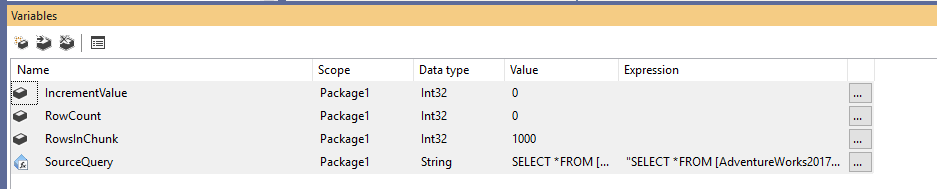
Figura 1 – Adăugarea variabilelor
În continuare, adăugăm un Execute SQL Task pentru a obține numărul total de rânduri din tabelul sursă. În acest exemplu, folosim tabelul Person (Persoană) stocat în baza de date AdventureWorks2017. În Execute SQL Task, am utilizat următoarea instrucțiune SQL:
|
1
|
SELECT COUNT(*) FROM …
|
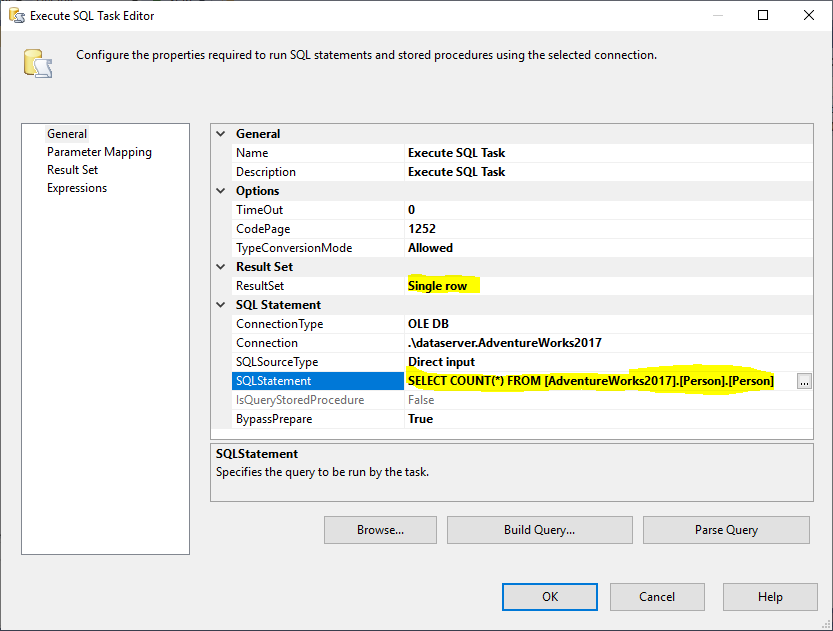
Figura 2 – Setarea Execute SQL Task
Și, trebuie să schimbăm proprietatea Result Set (Set de rezultate) în Single Row (Un singur rând). Apoi, în fila Result Set, selectăm variabila RowCount pentru a stoca setul de rezultate, așa cum se arată în imaginea de mai jos:
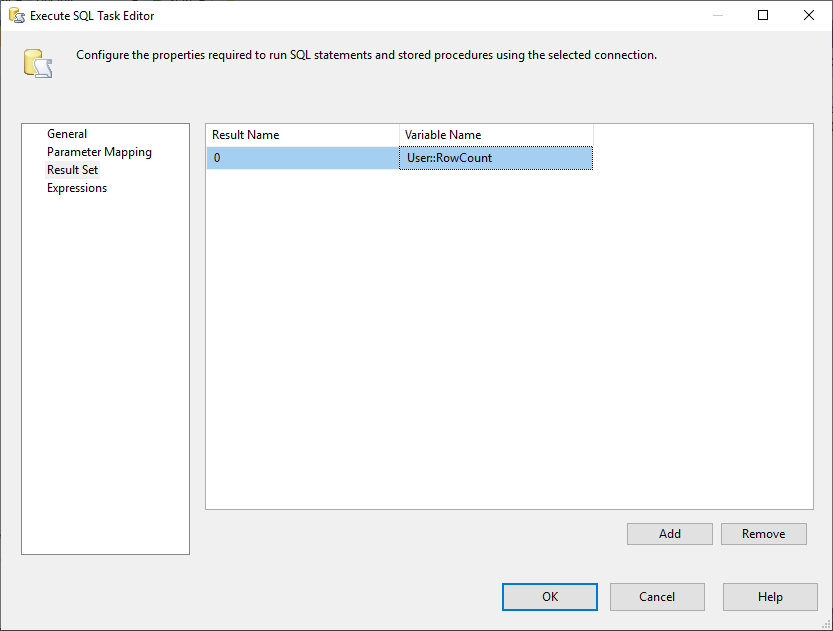
Figura 3 – Maparea setului de rezultate către variabila
După ce configurăm Execute SQL Task, adăugăm un container For Loop, cu următoarele specificații:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
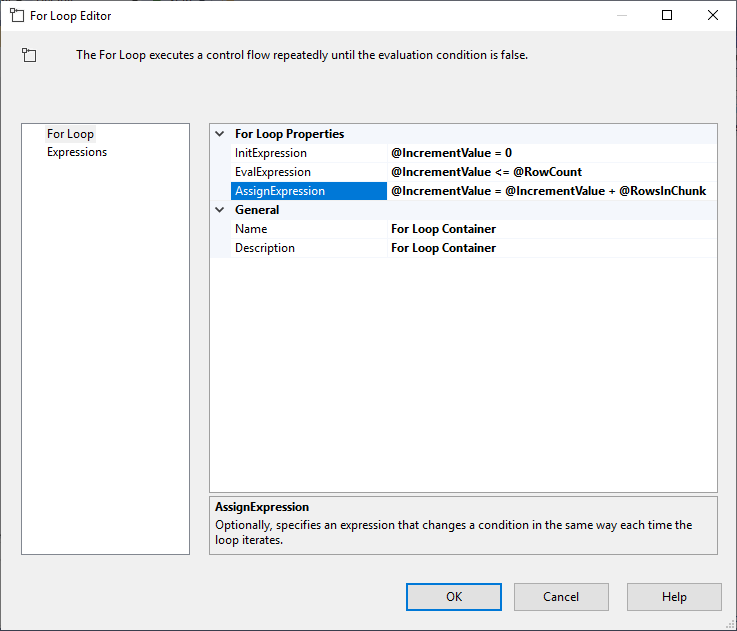
Figura 4 – Configurarea containerului For Loop
După ce am configurat containerul For Loop, adăugăm o sarcină de flux de date în interiorul acestuia. Apoi, în cadrul Data Flow Task, adăugăm o sursă OLE DB și o destinație OLE DB.
În OLE DB Source selectăm SQL Command din modul de acces la date variabile și selectăm variabila @User::SourceQuery ca sursă.
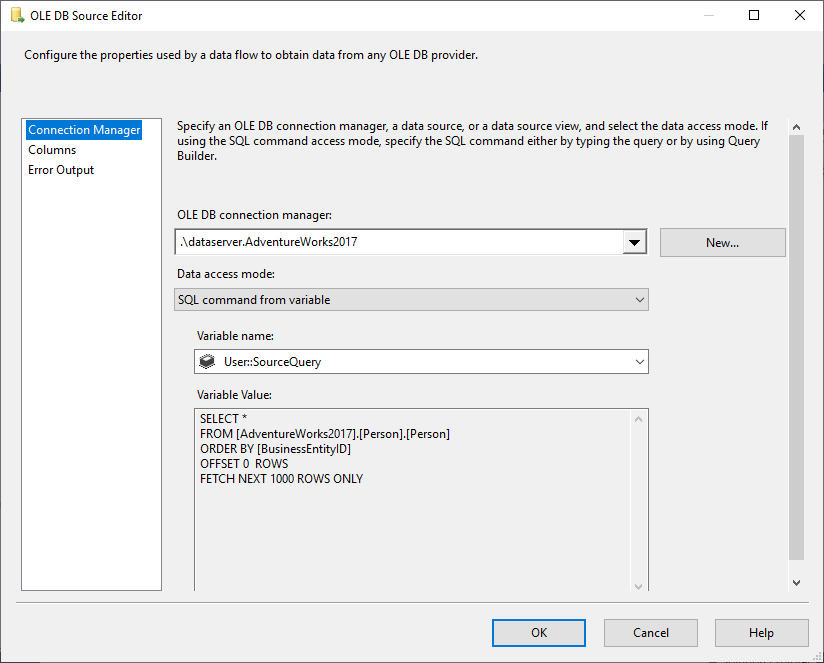
Figura 5 – Configurarea sursei OLE DB
Specificăm tabelul de destinație în cadrul componentei OLE DB Destination:
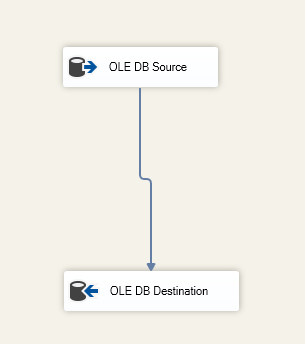
Figura 6 – Captură de ecran a sarcinii de flux de date
Fluxul de control al pachetului ar trebui să arate după cum urmează:
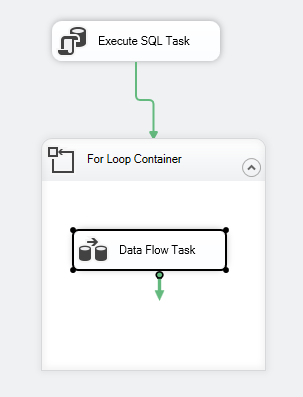
Figura 7 – Captură de ecran a fluxului de control
Limitări
După ce am ilustrat modul de încărcare a datelor în bucăți folosind funcția OFFSET FETCH din SSIS, vom observa că această logică are unele limitări:
- Aveți întotdeauna nevoie de anumite coloane care să fie utilizate în clauza ORDER BY (este de preferat Identity sau Primary key), deoarece OFFSET FETCH este o caracteristică a clauzei ORDER BY și nu poate fi implementată separat
- În cazul în care apare o eroare în timpul încărcării datelor, toate datele exportate la destinație sunt confirmate și numai bucata curentă de date este reluată. Acest lucru poate necesita pași suplimentari pentru a preveni duplicarea datelor atunci când se execută din nou pachetul
OFFSET FETCH utilizând alți furnizori de baze de date
În secțiunea următoare, vom acoperi pe scurt sintaxa utilizată de alți furnizori de baze de date:
Oracle
Cu Oracle, puteți utiliza aceeași sintaxă ca și SQL Server. Consultați următorul link pentru mai multe informații: Oracle FETCH
SQLite
În SQLite, sintaxa este diferită de cea din SQL Server, deoarece se utilizează caracteristica LIMIT OFFSET, așa cum se menționează mai jos:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
În MySQL, sintaxa este similară cu cea din SQLite, deoarece se utilizează LIMIT OFFSET în loc de OFFSET Fetch.
DB2
În DB2, sintaxa este similară cu cea din SQLite, deoarece se utilizează LIMIT OFFSET în loc de OFFSET FETCH.
Concluzie
În acest articol, am descris caracteristica OFFSET FETCH care se găsește în SQL Server 2012 și versiunile ulterioare. Am ilustrat modul de utilizare a acestei caracteristici pentru a crea o interogare de paginare, apoi am oferit un ghid pas cu pas privind modul de încărcare a datelor în bucăți pentru a permite extragerea unor cantități mari de date utilizând o mașină cu resurse limitate. În cele din urmă, am menționat unele dintre limitările și diferențele de sintaxă cu alți furnizori de baze de date.
- Autor
- Recent Posts

În afară de lucrul cu SQL Server, a lucrat cu diferite tehnologii de date, cum ar fi bazele de date NoSQL, Hadoop, Apache Spark. Este un profesionist certificat Neo4j și ArangoDB.
La nivel academic, Hadi deține două diplome de master în informatică și informatică de afaceri. În prezent, este doctorand în știința datelor, concentrându-se pe tehnicile de evaluare a calității Big Data.
Lui Hadi îi place foarte mult să învețe lucruri noi în fiecare zi și să își împărtășească cunoștințele. Îl puteți contacta pe site-ul său personal.
Vezi toate postările lui Hadi Fadlallah
- Construirea cuburilor SSAS OLAP folosind Biml – 16 martie, 2021
- Migrarea bazelor de date grafice SQL Server la Neo4j – 9 martie 2021
- Noțiuni de bază cu baza de date grafice Neo4j – 5 februarie 2021
.