Când comparăm prețul unei camere de hotel între diferite site-uri web, trebuie să ne asigurăm că comparăm mere cu mere
În informatică, fuzzy string matching este tehnica de a găsi șiruri de caractere care se potrivesc aproximativ (mai degrabă decât exact) cu un model. Într-un alt cuvânt, fuzzy string matching este un tip de căutare care va găsi corespondențe chiar și atunci când utilizatorii scriu greșit cuvintele sau introduc doar cuvinte parțiale pentru căutare. Este cunoscută și sub denumirea de potrivire aproximativă a șirurilor de caractere.
Cercetarea fuzzy a șirurilor de caractere poate fi utilizată în diverse aplicații, cum ar fi:
- Un verificator ortografic și un corector de greșeli de ortografie, de greșeli de tipar. De exemplu, un utilizator tastează „Missisaga” în Google, o listă de rezultate este returnată împreună cu „Afișarea rezultatelor pentru mississauga”. Adică, interogarea de căutare returnează rezultate chiar dacă introducerea utilizatorului conține caractere suplimentare sau lipsă, sau alte tipuri de greșeli de ortografie.
- Un software poate fi folosit pentru a verifica dacă există înregistrări duplicate. De exemplu, în cazul în care un client este listat de mai multe ori cu achiziții diferite în baza de date din cauza ortografiei diferite a numelui său (de exemplu, Abigail Martin vs. Abigail Martinez), a unei adrese noi sau a unui număr de telefon introdus din greșeală.
Vorbind de deduplicare, s-ar putea să nu fie atât de ușor pe cât pare, în special dacă aveți sute de mii de înregistrări. Nici măcar Expedia nu reușește să o facă 100% corect:
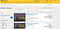
Acest post va explica ce este fuzzy string matching împreună cu cazurile sale de utilizare și va da exemple folosind biblioteca Fuzzywuzzy din Python.
Care hotel are propria nomenclatură pentru a-și denumi camerele, același scenariu este valabil și pentru agențiile de turism online (OTA). De exemplu, o cameră din același hotel, pe care Expedia o numește „Studio, 1 King Bed with Sofa bed, Corner”, Booking.com s-ar putea să se simtă în siguranță afișând camera pur și simplu ca fiind „Corner King Studio”.
Nu este nimic în neregulă aici, dar ar putea duce la confuzie atunci când vrem să comparăm tariful camerei între OTA-uri, sau când o OTA vrea să se asigure că o altă OTA respectă acordul de paritate a tarifelor. Cu alte cuvinte, pentru a putea compara prețul, trebuie să ne asigurăm că comparăm mere cu mere.
Una dintre problemele cele mai constant frustrante pentru site-urile și aplicațiile de comparare a prețurilor este încercarea de a ne da seama dacă două articole (sau camere de hotel) sunt pentru același lucru, în mod automat.
Fuzzywuzzy este o bibliotecă Python care utilizează distanța Levenshtein pentru a calcula diferențele dintre secvențe într-un pachet simplu de utilizat.
Pentru a demonstra, îmi creez propriul set de date, adică, pentru aceeași proprietate hotelieră, iau un tip de cameră de la Expedia, să spunem „Suite, 1 King Bed (Parlor)”, apoi îl compar cu un tip de cameră din Booking.com care este „King Parlor Suite”. Cu puțină experiență, majoritatea oamenilor ar ști că este vorba de același lucru. Urmând această metodologie, am creat un mic set de date cu peste 100 de perechi de tipuri de camere, care poate fi găsit pe Github.
Utilizând acest set de date, vom testa cum gândește Fuzzywuzzy. Cu alte cuvinte, vom folosi Fuzzywuzzy pentru a potrivi înregistrări între două surse de date.
import pandas as pddf = pd.read_csv('room_type.csv')
df.head(10)

Setul de date a fost creat de mine, deci, este foarte curat.
Există mai multe moduri de a compara două șiruri de caractere în Fuzzywuzzy, să le încercăm pe rând.
-
ratio, compară întreaga similaritate a șirurilor, în ordine.
from fuzzywuzzy import fuzz
fuzz.ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
Aceasta ne spune că perechea „Deluxe Room, 1 King Bed” și „Deluxe King Room” se aseamănă în proporție de aproximativ 62%.
fuzz.ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
Partea „Traditional Double Room, 2 Double Beds” și „Double Room with Two Double Beds” se aseamănă în proporție de aproximativ 69%.
fuzz.ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Paroada „Cameră, 2 paturi duble (de la etajul 19 la etajul 25)” și perechea „Cameră cu două paturi duble – cameră cu locație (de la etajul 19 la etajul 25)” sunt aproximativ 74% la fel.
Sunt dezamăgit de acestea. Se pare că abordarea naivă este mult prea sensibilă la diferențele minore în ordinea cuvintelor, la cuvintele lipsă sau în plus și la alte probleme de acest gen.
-
partial_ratio, compară similaritatea parțială a șirurilor de caractere.
Utilizăm în continuare aceleași perechi de date.
fuzz.partial_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.partial_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.partial_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Pentru setul meu de date, compararea parțială a șirurilor de caractere nu aduce rezultate mai bune în general. Să continuăm.
-
token_sort_ratio, ignoră ordinea cuvintelor.
fuzz.token_sort_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.token_sort_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.token_sort_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Cel mai bun până acum.
-
token_set_ratio, ignoră cuvintele duplicate. Este similar cu raportul de sortare a jetoanelor, dar un pic mai flexibil.
fuzz.token_set_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.token_set_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.token_set_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Se pare că token_set_ratio este cel mai potrivit pentru datele mele. În funcție de această descoperire, am decis să aplic token_set_ratio la întregul meu set de date.
.