W tym artykule ilustrujemy, jak używać funkcji OFFSET FETCH jako rozwiązania do ładowania dużych ilości danych z relacyjnej bazy danych przy użyciu maszyny z ograniczoną ilością pamięci i zapobiegania wyjątkom braku pamięci. Opisujemy, jak ładować dane partiami, aby uniknąć umieszczania dużej ilości danych w pamięci.
Ten artykuł jest pierwszym z serii SSIS Tips and Tricks, której celem jest zilustrowanie kilku najlepszych praktyk.
Wprowadzenie
Szukając w Internecie problemów związanych z importem danych SSIS, można znaleźć rozwiązania, które można zastosować w optymalnych środowiskach lub samouczki do obsługi niewielkiej ilości danych. Niestety, rozwiązania te okazują się nieprzydatne w rzeczywistym środowisku.
W rzeczywistości mniejsze firmy nie zawsze mogą przyjąć nowe urządzenia do przechowywania, przetwarzania i technologie, chociaż nadal muszą obsługiwać coraz większą ilość danych. Jest to szczególnie prawdziwe w przypadku analizy mediów społecznościowych, ponieważ muszą analizować zachowania swoich docelowych odbiorców (klientów).
Podobnie, nie wszystkie firmy mogą przesyłać swoje dane do chmury ze względu na wysokie koszty wraz z kwestiami prywatności i poufności danych.
Funkcja OFFSET FETCH
OFFSET FETCH to funkcja dodana do klauzuli ORDER BY począwszy od edycji SQL Server 2012. Może być ona użyta do wyodrębnienia określonej liczby wierszy począwszy od określonego indeksu. Na przykład, mamy zapytanie, które zwraca 40 wierszy i musimy wyodrębnić 10 wierszy od 10 wiersza:
|
1
2
3
4
5
|
SELECT *
. FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
W powyższym zapytaniu, OFFSET 10 jest używany do pominięcia 10 wierszy, a FETCH 10 ROWS ONLY jest używany do wyodrębnienia tylko 10 wierszy.
Aby uzyskać dodatkowe informacje na temat klauzuli ORDER BY i funkcji OFFSET FETCH, zapoznaj się z oficjalną dokumentacją: Using OFFSET and FETCH to limit the rows returned.
Używanie funkcji OFFSET FETCH do ładowania danych w kawałkach (paginacja)
Jednym z głównych celów używania funkcji OFFSET FETCH jest ładowanie danych w kawałkach. Wyobraźmy sobie, że mamy aplikację, która wykonuje zapytanie SQL i potrzebuje wyświetlić wyniki na kilku stronach, gdzie każda strona zawiera tylko 10 wyników (podobnie jak w wyszukiwarce Google).
Następujące zapytanie może być użyte jako zapytanie stronicujące, gdzie @PageSize jest liczbą wierszy, które musisz pokazać w każdym chunk’u, a @PageNumber jest numerem iteracji (strony):
|
1
2
3
4
5
|
SELECT <some kolumny>.
FROM <tabela nazwa>
ORDER BY <some columns>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Ten artykuł nie ma na celu zilustrowania wszystkich przypadków użycia funkcji OFFSET FETCH, ani nie omawia najlepszych praktyk. Istnieje wiele artykułów online, do których można się odnieść, aby uzyskać więcej informacji:
- Paginacja z OFFSET / FETCH : A better way
- Paginacja w SQL Server przy użyciu OFFSET / FETCH
Implementing the OFFSET FETCH feature within SSIS to load a large volume of data in chunks
Często byliśmy proszeni o zbudowanie pakietu SSIS, który ładuje ogromną ilość danych z SQL Server przy ograniczonych zasobach maszynowych. Ładowanie danych przy użyciu OLE DB Source w trybie dostępu do danych Table lub View powodowało wyjątek braku pamięci.
Jednym z najprostszych rozwiązań jest użycie funkcji OFFSET FETCH do ładowania danych w kawałkach, aby zapobiec błędom braku pamięci. W tej sekcji przedstawiamy przewodnik krok po kroku dotyczący implementacji tej logiki w ramach pakietu SSIS.
Najpierw musimy utworzyć nowy pakiet Integration Services, a następnie zadeklarować cztery zmienne w następujący sposób:
- RowCount (Int32): Przechowuje całkowitą liczbę wierszy w tabeli źródłowej
- IncrementValue (Int32): Przechowuje liczbę wierszy, którą musimy określić w klauzuli OFFSET (podobnie jak @PageSize * @PageNumber w powyższym przykładzie)
- RowsInChunk (Int32): Określa liczbę wierszy w każdym chunk of data (Podobne do @PageSize w powyższym przykładzie)
- SourceQuery (String): Przechowuje źródłowe polecenie SQL użyte do pobrania danych
Po zadeklarowaniu zmiennych, przypisujemy domyślną wartość dla zmiennej RowsInChunk; w tym przykładzie ustawimy ją na 1000. Ponadto musimy ustawić wyrażenie Source Query, jak poniżej:
|
1
2
3
4
5
|
„SELECT *
FROM …
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
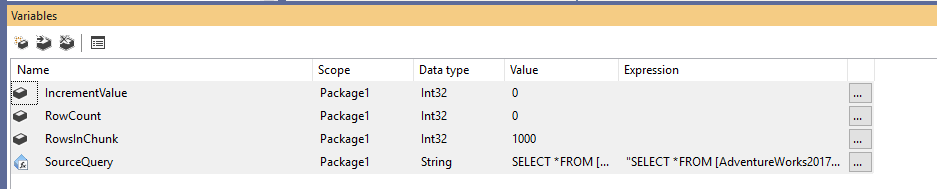
Rysunek 1 – Dodawanie zmiennych
Następnie dodajemy zadanie Execute SQL Task, aby uzyskać całkowitą liczbę wierszy w tabeli źródłowej. W tym przykładzie używamy tabeli Person przechowywanej w bazie danych AdventureWorks2017. W zadaniu Execute SQL Task użyliśmy następującej instrukcji SQL:
|
1
|
SELECT COUNT(*) FROM …
|
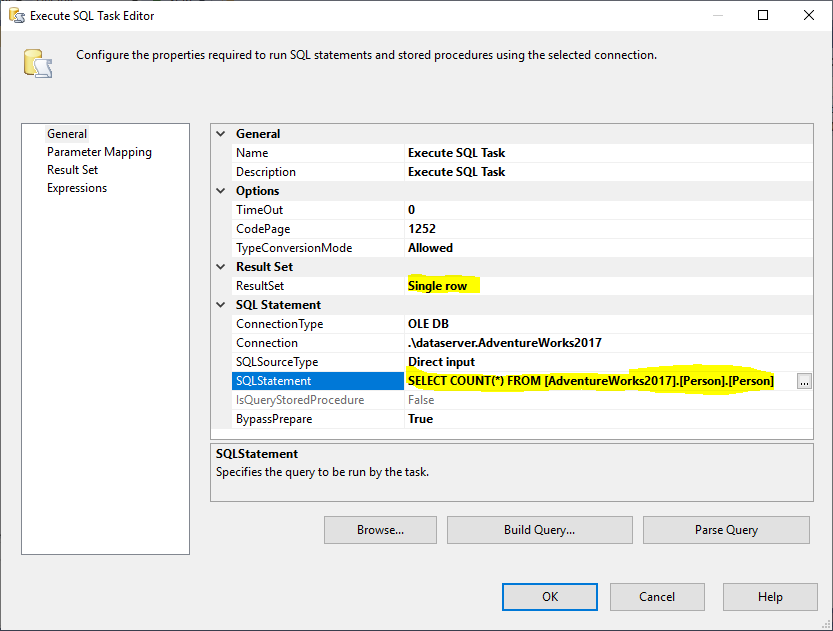
Rysunek 2 – Ustawienie Execute SQL Task
I, musimy zmienić właściwość Result Set na Single Row. Następnie, w zakładce Result Set, wybieramy zmienną RowCount do przechowywania zestawu wyników, jak pokazano na poniższym obrazku:
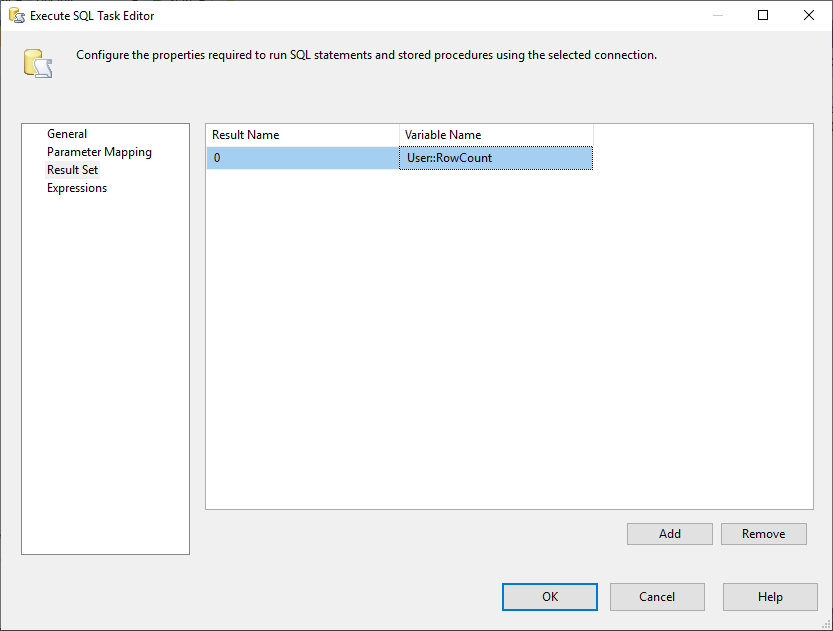
Rysunek 3 – Mapowanie zestawu wyników do zmiennej
Po skonfigurowaniu Execute SQL Task, dodajemy kontener For Loop, z następującą specyfikacją:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
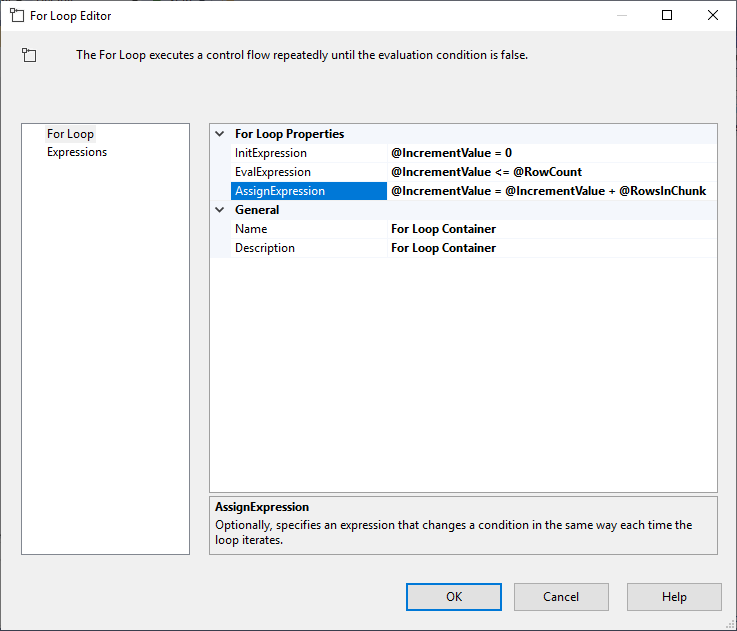
Rysunek 4 – Konfiguracja kontenera For Loop
Po skonfigurowaniu kontenera For Loop, dodajemy wewnątrz niego zadanie Data Flow Task. Następnie, w ramach zadania przepływu danych, dodajemy źródło OLE DB oraz miejsce docelowe OLE DB.
W źródle OLE DB wybieramy polecenie SQL z trybu dostępu do danych zmiennych oraz wybieramy zmienną @User::SourceQuery jako źródło.
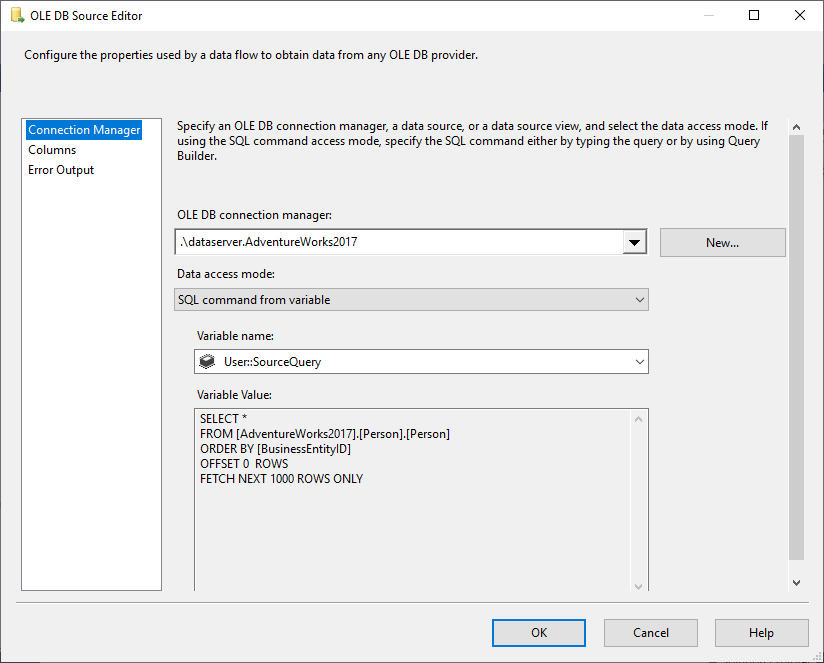
Rysunek 5 – Konfiguracja źródła OLE DB
W komponencie OLE DB Destination określamy tabelę docelową:
Rysunek 6 – Zrzut ekranu zadania przepływu danych
Przepływ sterowania pakietem powinien wyglądać jak poniżej:
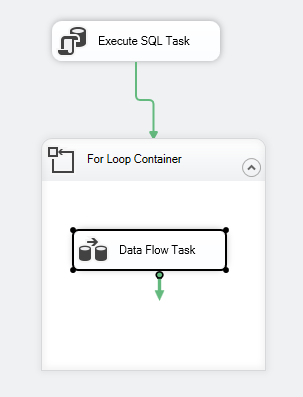
Rysunek 7 – Zrzut ekranu przepływu sterowania
Ograniczenia
Po zilustrowaniu sposobu ładowania danych w chunkach za pomocą funkcji OFFSET FETCH w SSIS zauważymy, że ta logika ma pewne ograniczenia:
- Zawsze trzeba użyć pewnych kolumn w klauzuli ORDER BY (preferowany jest klucz identyczności lub klucz podstawowy), ponieważ OFFSET FETCH jest cechą klauzuli ORDER BY i nie można jej zaimplementować osobno
- Jeśli podczas ładowania danych wystąpi błąd, wszystkie dane wyeksportowane do miejsca docelowego są commitowane, a tylko bieżący chunk danych jest rolowany wstecz. Może to wymagać dodatkowych kroków, aby zapobiec duplikacji danych podczas ponownego uruchomienia pakietu
OFFSET FETCH przy użyciu innych dostawców baz danych
W poniższej sekcji pokrótce omówimy składnię używaną przez innych dostawców baz danych:
Oracle
W przypadku Oracle można użyć tej samej składni, co w przypadku SQL Server. Aby uzyskać więcej informacji, zapoznaj się z poniższym linkiem: Oracle FETCH
SQLite
W SQLite składnia różni się od SQL Server, ponieważ używasz funkcji LIMIT OFFSET, jak wspomniano poniżej:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
W MySQL, składnia jest podobna do SQLite, ponieważ używasz LIMIT OFFSET zamiast OFFSET Fetch.
DB2
W DB2 składnia jest podobna do SQLite, ponieważ używasz LIMIT OFFSET zamiast OFFSET FETCH.
Zakończenie
W tym artykule opisaliśmy funkcję OFFSET FETCH dostępną w SQL Server 2012 i nowszych wersjach. Zilustrowaliśmy jak użyć tej funkcji do stworzenia zapytania stronicującego, a następnie przedstawiliśmy krok po kroku jak załadować dane w kawałkach, aby umożliwić wydobycie dużej ilości danych na maszynie z ograniczonymi zasobami. Na koniec wspomnieliśmy o niektórych ograniczeniach i różnicach w składni z innymi dostawcami baz danych.
- Autor
- Recent Posts

Poza pracą z SQL Server, pracował z różnymi technologiami danych, takimi jak bazy danych NoSQL, Hadoop, Apache Spark. Jest certyfikowanym profesjonalistą Neo4j i ArangoDB.
Na poziomie akademickim, Hadi posiada dwa tytuły magistra w dziedzinie informatyki i informatyki biznesowej. Obecnie jest doktorantem w dziedzinie nauki o danych, koncentrując się na technikach oceny jakości Big Data.
Hadi naprawdę lubi uczyć się nowych rzeczy każdego dnia i dzielić się swoją wiedzą. Możesz skontaktować się z nim na jego osobistej stronie internetowej.
View all posts by Hadi Fadlallah
- Building SSAS OLAP cubes using Biml – March 16, 2021
- Migrowanie baz danych grafów SQL Server do Neo4j – 9 marca 2021
- Rozpoczęcie pracy z bazą danych grafów Neo4j – 5 lutego 2021
.