Kiedy porównujemy cenę pokoju hotelowego na różnych stronach internetowych, musimy mieć pewność, że porównujemy jabłka z jabłkami
W informatyce, rozmyte dopasowywanie ciągów znaków jest techniką znajdowania ciągów znaków, które pasują do wzorca w przybliżeniu (a nie dokładnie). Innym słowem, rozmyte dopasowywanie ciągów jest rodzajem wyszukiwania, które znajdzie dopasowania, nawet jeśli użytkownicy błędnie wpisują słowa lub wprowadzają tylko częściowe słowa do wyszukiwania. Jest również znany jako przybliżone dopasowanie ciągów.
Fuzzy wyszukiwanie ciągów może być używany w różnych aplikacjach, takich jak:
- Sprawdzanie pisowni i błąd pisowni, korektor literówek. Na przykład, użytkownik wpisuje „Missisaga” do Google, lista trafień jest zwracana wraz z „Showing results for mississauga”. Oznacza to, że zapytanie wyszukiwania zwraca wyniki, nawet jeśli dane wejściowe użytkownika zawierają dodatkowe lub brakujące znaki, lub inne rodzaje błędów ortograficznych.
- Program może być używany do sprawdzania duplikatów rekordów. Na przykład, jeśli klient jest wymieniony wiele razy z różnych zakupów w bazie danych z powodu różnych pisowni ich nazwy (np. Abigail Martin vs. Abigail Martinez) nowy adres, lub błędnie wprowadzony numer telefonu.
Mówiąc o dedupe, może nie być tak proste, jak to brzmi, w szczególności, jeśli masz setki tysięcy rekordów. Nawet Expedia nie robi tego w 100% poprawnie:
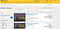
W tym poście wyjaśnię, czym jest fuzzy string matching wraz z jego przypadkami użycia oraz podam przykłady z wykorzystaniem biblioteki Pythona Fuzzywuzzy.
Każdy hotel ma swoją własną nomenklaturę do nazywania swoich pokoi, ten sam scenariusz dotyczy Online Travel Agency (OTA). Na przykład, jeden pokój w tym samym hotelu, Expedia nazywa „Studio, 1 King Bed with Sofa bed, Corner”, Booking.com może znaleźć bezpieczne w pokazując pokój po prostu jako „Corner King Studio”.
Nie ma nic złego tutaj, ale może to prowadzić do zamieszania, gdy chcemy porównać stawkę pokoju między OTAs, lub jeden OTA chce się upewnić, że inny OTA następuje parytet stawki umowy. Innym słowem, aby móc porównać cenę, musimy upewnić się, że porównujemy jabłka z jabłkami.
Jedną z najbardziej konsekwentnie frustrujących kwestii dla stron internetowych i aplikacji porównujących ceny jest próba ustalenia, czy dwa przedmioty (lub pokoje hotelowe) są za tę samą rzecz, automatycznie.
Fuzzywuzzy to biblioteka Python używa Levenshtein Distance do obliczania różnic między sekwencjami w prostym do użycia package.
W celu zademonstrowania, tworzę własny zestaw danych, to znaczy, dla tej samej nieruchomości hotelowej, biorę typ pokoju z Expedia, powiedzmy „Suite, 1 King Bed (Parlor)”, a następnie dopasowuję go do typu pokoju w Booking.com, który jest „King Parlor Suite”. Z odrobiną doświadczenia, większość ludzi będzie wiedział, że są one takie same rzeczy. Postępuj zgodnie z tą metodologią, tworzę mały zestaw danych z ponad 100 parami typów pokoi, które można znaleźć na Github.
Używając tego zestawu danych, zamierzamy przetestować, jak myśli Fuzzywuzzy. Innymi słowy, używamy Fuzzywuzzy do dopasowania rekordów między dwoma źródłami danych.
import pandas as pddf = pd.read_csv('room_type.csv')
df.head(10)

Zestaw danych został stworzony przeze mnie, więc jest bardzo czysty.
W Fuzzywuzzy istnieje kilka sposobów na porównanie dwóch ciągów znaków, wypróbujmy je po kolei.
-
ratio, porównuje podobieństwo całego ciągu znaków, w kolejności.
from fuzzywuzzy import fuzz
fuzz.ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
To mówi nam, że para „Deluxe Room, 1 King Bed” i „Deluxe King Room” są w około 62% takie same.
fuzz.ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
Para „Traditional Double Room, 2 Double Beds” i „Double Room with Two Double Beds” są w około 69% takie same.
fuzz.ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
The „Room, 2 Double Beds (19th to 25th Floors)” and „Two Double Beds – Location Room (19th to 25th Floors)” pair are about 74% the same.
I am disappointed with these. Okazuje się, że naiwne podejście jest zbyt wrażliwe na drobne różnice w kolejności słów, brakujące lub dodatkowe słowa i inne tego typu problemy.
-
partial_ratio, porównuje częściowe podobieństwo ciągów.
Wciąż używamy tych samych par danych.
fuzz.partial_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.partial_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.partial_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
W przypadku mojego zestawu danych porównywanie częściowych ciągów nie przynosi ogólnie lepszych wyników. Kontynuujmy.
-
token_sort_ratio, ignoruje kolejność słów.
fuzz.token_sort_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.token_sort_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.token_sort_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Najlepszy jak dotąd.
-
token_set_ratio, ignoruje zduplikowane słowa. Jest podobny ze współczynnikiem sortowania tokenów, ale nieco bardziej elastyczny.
fuzz.token_set_ratio('Deluxe Room, 1 King Bed', 'Deluxe King Room')
fuzz.token_set_ratio('Traditional Double Room, 2 Double Beds', 'Double Room with Two Double Beds')
fuzz.token_set_ratio('Room, 2 Double Beds (19th to 25th Floors)', 'Two Double Beds - Location Room (19th to 25th Floors)')
Wygląda na to, że token_set_ratio jest najlepiej dopasowany do moich danych. Zgodnie z tym odkryciem, zdecydowałem się zastosować token_set_ratio do całego mojego zestawu danych.
.