この記事では、メモリの限られたマシンを使用してリレーショナルデータベースから大量のデータをロードしてメモリ不足例外を防止するソリューションとして、OFFSET FETCH 機能を使用する方法を説明します。 大量のデータをメモリに配置しないように、データをバッチでロードする方法を説明します。
この記事は、いくつかのベスト プラクティスを説明することを目的とした SSIS Tips and Tricks シリーズの最初の記事です。
Introduction
SSIS データ インポートに関する問題をオンラインで検索すると、最適環境で使用できるソリューションや少量のデータを処理するチュートリアルが見つかるでしょう。
現実には、中小企業は増え続けるデータを処理しなければならないにもかかわらず、新しいストレージや処理装置、技術を導入できないことが多いのです。 同様に、データのプライバシーや機密性の問題に加え、コストが高いため、すべての企業がデータをクラウドにアップロードできるわけではありません。
OFFSET FETCH 機能
OFFSET FETCH は、SQL Server 2012 版から ORDER BY 句に追加された機能です。 特定のインデックスを起点として、特定の行数を抽出するために使用することができます。 例として、40行を返すクエリがあり、10行目から10行を抽出する必要がある場合について説明します。
|
1
2
3
4
5
|
select *
FROM テーブル
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
上のクエリの中で、「FETCH 10 ROWS」は「FETCH NEXT 10」です。 OFFSET 10は10行をスキップするために、FETCH 10 ROWS ONLYは10行だけを抽出するために使用されます。
ORDER BY句とOFFSET FETCH機能に関する追加情報を得るには、公式ドキュメントを参照してください。 OFFSETおよびFETCHを使用して返される行を制限する」
Using OFFSET FETCH to load data in chunks (pagination)
OFFSET FETCH機能を使用する主な目的の1つは、データを塊で読み込むことです。 SQL クエリを実行し、各ページが 10 件の結果のみを含む複数のページに結果を表示する必要があるアプリケーションがあるとします (Google 検索エンジンに似ています)。
次のクエリはページング クエリとして使用できます。@PageSize は各チャンクで表示する必要がある行数で、@PageNumber は反復(ページ)番号です。
|
1
2
3
4
5
|
SELECT <some columns>
FROM <table name>
ORDER BY <some columns>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY.FETCH
ORIGINAL
FETCH NEXT @PageSize ROWS ONLY;
|
この記事は、OFFSET FETCH 機能のすべての使用例を説明するものではありませんし、ベスト プラクティスについて説明するものではありません。 詳細については、オンラインに多くの記事があるので、それを参照してください:
- OFFSET / FETCH によるページネーション : A better way
- OFFSET / FETCH を使用した SQL Server のページネーション
OFFSET FETCH 機能を SSIS に実装して大量のデータを塊でロード
限られたマシンリソースで SQL Server から大量にデータをロードする SSIS パッケージを構築するように、よく依頼されることがあります。 テーブルまたはビューデータアクセスモードを使用してOLE DBソースを使用してデータをロードすると、メモリ不足の例外が発生しました。
最も簡単な解決策の1つは、OFFSET FETCH機能を使用して、メモリ不足のエラーを防ぐためにデータをチャンクにロードすることです。 このセクションでは、SSIS パッケージ内でこのロジックを実装する手順を説明します。
まず、新しい Integration Services パッケージを作成し、次のように 4 つの変数を宣言する必要があります。 ソース テーブルの総行数を格納
変数を宣言した後、RowsInChunk 変数にデフォルト値を代入します(この例では 1000 に設定します)。 さらに、ソース クエリ式を次のように設定する必要があります:
|
1
2
3
4
5
|
“SELECT *
FROM …”
order by
offset ” + (dt_wstr,50)@ + ” rows
fetch next ” + (dt_wstr.)” “次の行を取得します。50) @ + ” ROWS ONLY”
|
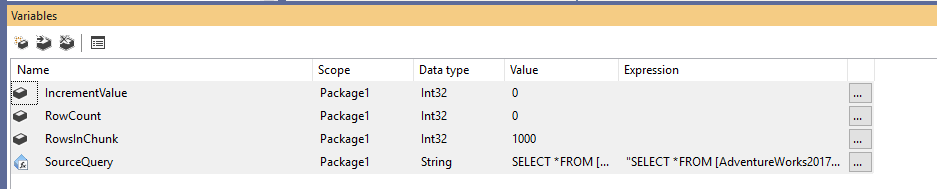
Figure 1 – Adding variables
Next, add a Execute SQL Task to get total number of rows in source table. この例では、AdventureWorks2017データベースに格納されているPersonテーブルを使用します。 実行 SQL タスクでは、次の SQL 文を使用しました:
|
1
|
SELECT COUNT(*) FROM … 続きを読む
|
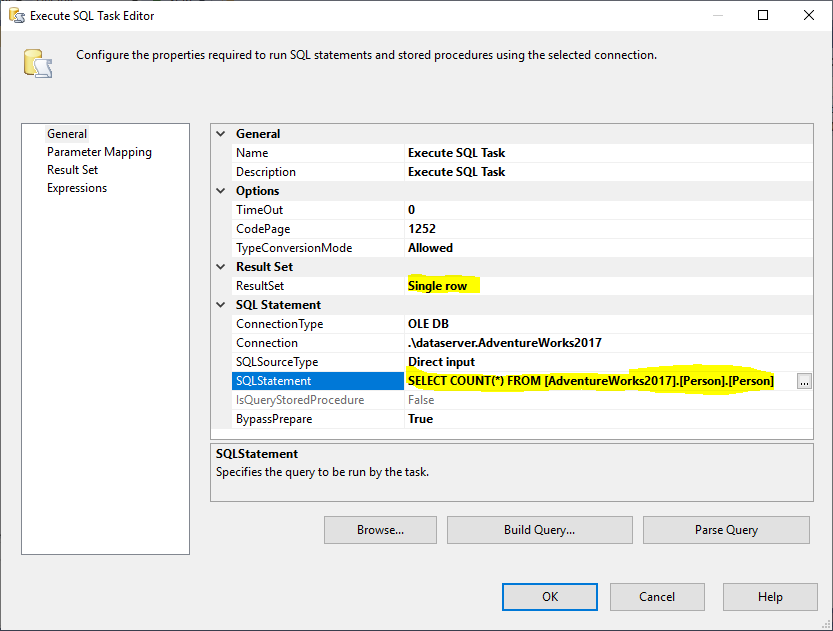
図2-SQL実行タスク設定
また、結果セット・プロパティは単一行に変更する必要があります。
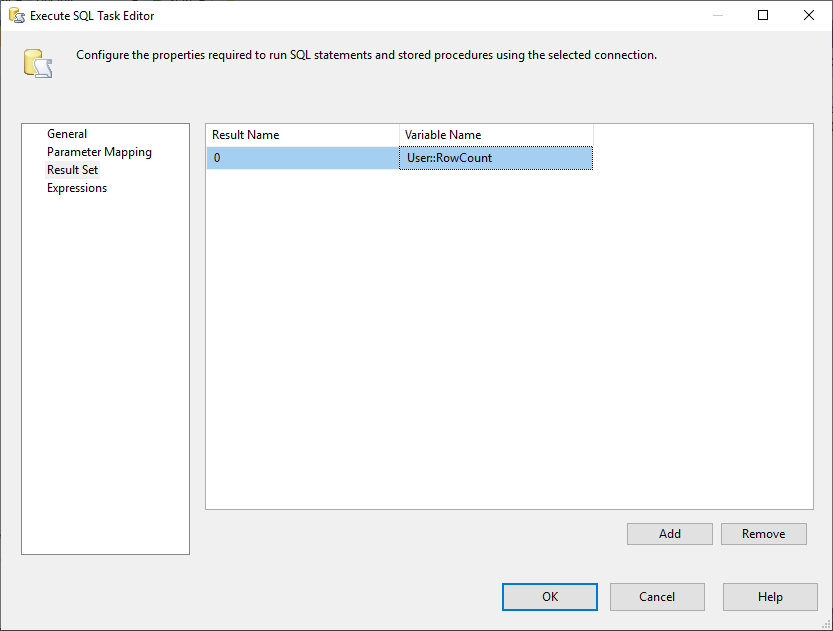
Figure 3 – Mapping result set to variable
Execute SQL Taskを構成したら、次の仕様でFor Loop Containerを追加します:
- InitExpression.RowCount ROWCount変数に結果を格納します。 IncrementValue = 0
- EvalExpression: IncrementValue <= @RowCount
- AssignExpression: @IncrementValue <= @RowCount
- AssignExpression: 7658>
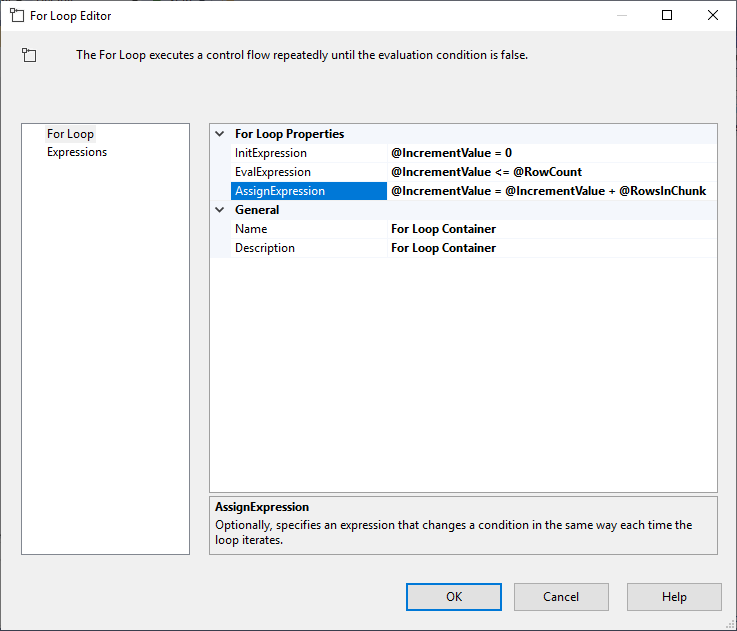
図4-ループコンテナの設定
ループコンテナを設定した後、その中にデータフロータスクを追加しています。 OLE DBソースでは、変数データアクセスモードからSQLコマンドを選択し、ソースとして@User::SourceQuery変数を選択します。
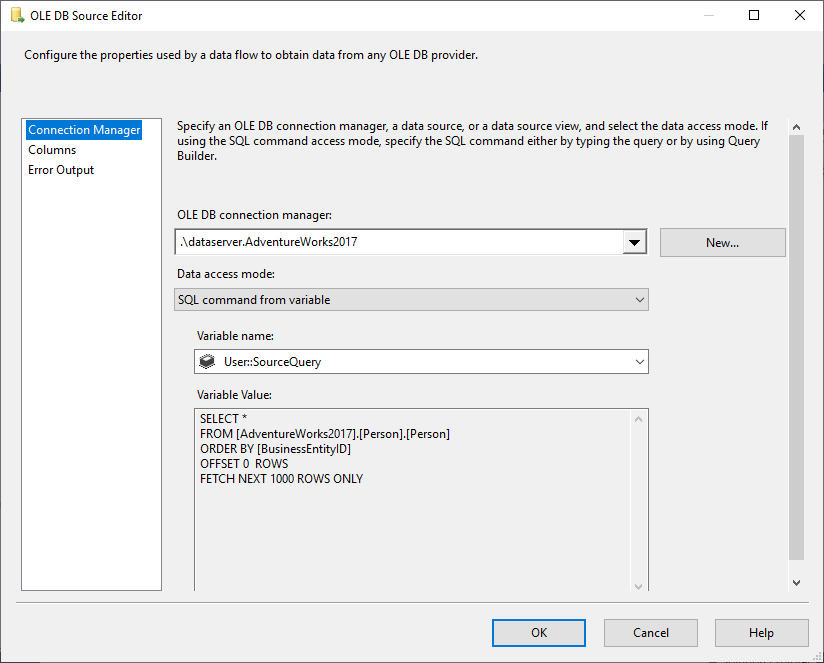
図5 – OLE DBソースの設定
OLE DB Destinationコンポーネントで宛先テーブルを指定します:
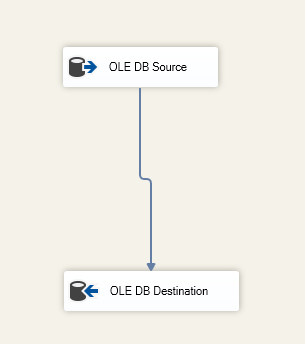
図6 – データフロータスク画面
パッケージ制御フローは次のようなものでなければならないでしょう。
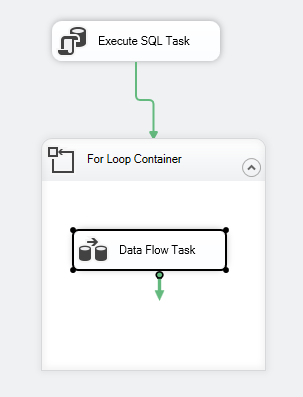
Figure 7 – Control flow screenshot
Limitations
SSISでOFFSET FETCH機能を使ってデータを塊でロードする方法を示した後で、この論理には制限があることに注意しましょう。
- OFFSET FETCH は ORDER BY 句の機能であり、個別に実装できないため、必ず ORDER BY 句で使用する列が必要です (Identity または Primary key が望ましい)
- データのロード中にエラーが発生すると、宛先にエクスポートしたすべてのデータはコミットされ、現在のデータのチャンクのみがロールバックされます。 このため、パッケージを再度実行する際にデータの重複を防ぐための追加手順が必要になる場合があります
OFFSET FETCH using other database providers
次のセクションでは、他のデータベース プロバイダーで使用される構文を簡単に説明します:
Oracle
Oracle では、SQL Server と同じ構文で使用することが可能です。 詳細については、次のリンクを参照してください。 Oracle FETCH
SQLite
SQLiteでは、下記のようにLIMIT OFFSETの機能を使用するので、SQL Serverとは構文が異なります。
|
1
2
3
|
select * from mytable ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
MySQLでは、以下のようになります。 の代わりに LIMIT OFFSET を使用するため、構文は SQLite と似ています。
DB2
DB2 では、OFFSET FETCH の代わりに LIMIT OFFSET を使用するので、構文は SQLite と同様です。
Conclusion
この記事では、SQL Server 2012 以上で見つかった OFFSET FETCH 機能を解説してきました。 この機能を使用してページング クエリを作成する方法を説明し、次に、リソースの限られたマシンを使用して大量のデータを抽出できるように、データをチャンクでロードする方法をステップバイステップで説明しました。 最後に、いくつかの制限事項と他のデータベース プロバイダーとの構文の違いについて言及しました。
- 著者
- 最近の投稿

SQL Serverでの作業に加えて、彼はNoSQLデータベース、Hadoop、Apache Sparkなどの異なるデータ技術で作業していました。
学術レベルでは、コンピュータサイエンスとビジネスコンピューティングで2つの修士号を取得しています。 現在、彼はビッグデータの品質評価技術に焦点を当てたデータサイエンスの博士号候補です。
Hadiは、毎日新しいことを学び、自分の知識を共有することをとても楽しんでいます。 彼の個人的なウェブサイトにアクセスすることができます。
Hadi Fadlallahの投稿をすべて表示
- Bimlを使ってSSAS OLAPキューブを構築 – 3月16日。 2021年
- SQL ServerグラフデータベースをNeo4jに移行する – 2021年3月9日
- Neo4jグラフデータベースを始める – 2021年2月5日