Statistiche descrittive
Per questo tutorial useremo il auto dataset fornito con Stata. Per caricare questo tipo di dati
sysuse auto, clearIl dataset automatico ha le seguenti variabili.
describe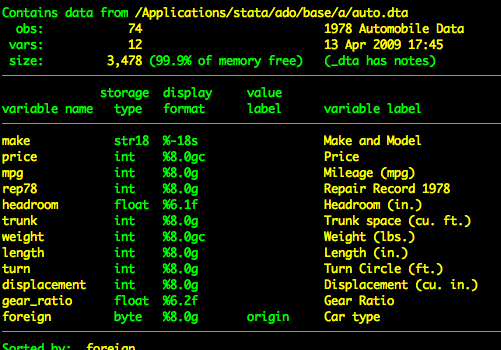
Supponiamo di voler ottenere alcune statistiche riassuntive per il prezzo come la media, la deviazione standard e il range. Useremo il comando summarize.
summarize price
Ora aggiungiamo l’opzione detail a summarize. Questo ci darà molte più informazioni, inclusa la mediana e altri percentili.
summarize price, detail
Variabili multiple in una volta
Per ottenere descrizioni per variabili multiple in una volta basta aggiungere i nomi delle variabili dopo summarize.
summarize price mpg
Aggiungi l’opzione detail.
summarize price mpg, detail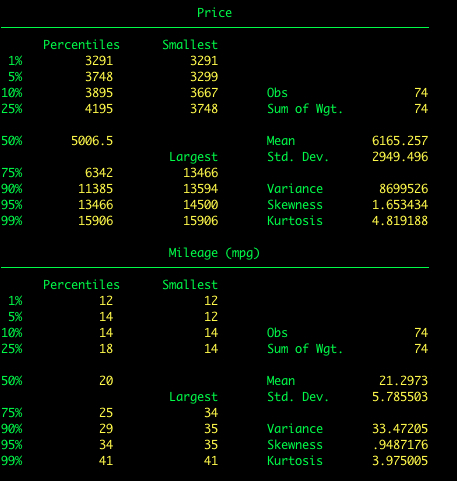
Utilizzando per elaborazione
Supponiamo di voler ottenere le statistiche descrittive per il prezzo per tipo di auto (straniera vs nazionale). Possiamo usare quella che viene chiamata byelaborazione.
by foreign: summarize price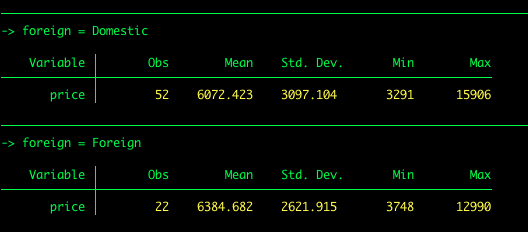
Quando si usa il comando by, la variabile di interesse deve essere ordinata nell’insieme dei dati. Per esempio, nell’esempio precedente la variabile “estero” è già ordinata nel nostro set di dati. Se volessimo esaminare il prezzo per mpg, avremmo bisogno di ordinare le miglia per gallone. Un modo per ordinare i dati è usare un semplice comando sort seguito dal nome della variabile. Stata ordinerà i dati in ordine crescente per default.
sort mpgDopo aver ordinato i dati, possiamo usare il comando standard by mpg:. Nell’elaborazione by, possiamo anche ordinare i dati ed eseguire il comando by allo stesso tempo usando il comando bysort:
bysort mpg: summarize priceIl comando by può anche essere usato in altri comandi, come la creazione di grafici. Per esempio, se volessimo esaminare gli istogrammi di mpg in base alla marca dell’auto, useremmo il comando by come opzione. La marca dell’auto non deve essere ordinata per questo comando.
histogram(mpg), by(foreign)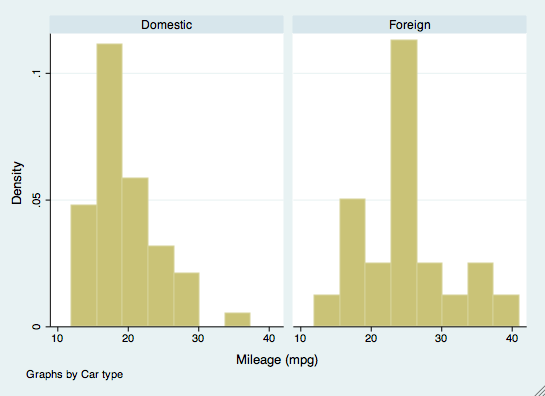
Usando if
La dichiarazione by ci darà le descrizioni per tutti i livelli della variabile by (cioè, sia stranieri che nazionali). Supponiamo di volere solo le descrizioni per un livello della variabile by. Possiamo usare la dichiarazione if per questo. Per le auto straniere (cioè foreign == 1):
summarize price if foreign == 1
Per le auto nazionali (cioè, foreign == 0)
summarize price if foreign == 0
Questa tabella serve a determinare come specificare quali livelli della variabile volete usare.
Simbolo |
Significato |
| == | è o è uguale a |
| != o ~= | non è o non è uguale a |
| > | è maggiore di |
| >= | è maggiore o uguale a |
| < | è minore di |
| <= | è minore o uguale a |
| *Da pag. 74 di A Gentle Introduction to Stata di Alan Acock | |
Usando in
Il qualificatore in specifica un particolare sottoinsieme di casi basato sul loro ordine nel dataset. Per esempio, se vogliamo esaminare il mpg nelle 10 auto meno costose, useremo il comando in.
sort pricesummarize mpg in 1/10
Come utile suggerimento per ognuno di questi processi, se le vostre variabili sono etichettate (mostrando l’etichetta invece del valore numerico) e avete bisogno di trovare i valori numerici per esaminare i livelli della variabile, potete usare l’opzione nolabel.
browse, nolabelQuesto vi mostrerà i valori numerici delle variabili. Puoi anche trovare quei valori facendo doppio clic su di essi nel navigatore di dati.
browse, nolabelQuesto ti mostrerà i valori numerici delle variabili.