In questo articolo, illustriamo come usare la funzione OFFSET FETCH come soluzione per caricare grandi volumi di dati da un database relazionale usando una macchina con memoria limitata ed evitando un’eccezione per esaurimento della memoria. Descriviamo come caricare i dati in batch per evitare di mettere in memoria una grande quantità di dati.
Questo articolo è il primo della serie SSIS Tips and Tricks che ha lo scopo di illustrare alcune best practices.
Introduzione
Quando si cercano online problemi relativi all’importazione di dati SSIS, si trovano soluzioni che possono essere usate in ambienti ottimali o tutorial per gestire una piccola quantità di dati. Sfortunatamente, queste soluzioni si rivelano inadatte in un ambiente reale.
In realtà, le aziende più piccole non possono sempre adottare nuove attrezzature di archiviazione, elaborazione e tecnologie, anche se devono comunque gestire una quantità crescente di dati. Questo è particolarmente vero per l’analisi dei social media poiché devono analizzare il comportamento del loro pubblico di riferimento (clienti).
Allo stesso modo, non tutte le aziende possono caricare i loro dati nel cloud a causa del costo elevato insieme ai problemi di privacy e riservatezza dei dati.
Funzione OFFSET FETCH
OFFSET FETCH è una funzione aggiunta alla clausola ORDER BY a partire dall’edizione 2012 di SQL Server. Può essere utilizzata per estrarre un numero specifico di righe a partire da un indice specifico. Come esempio, abbiamo una query che restituisce 40 righe e abbiamo bisogno di estrarre 10 righe dalla decima riga:
|
1
2
3
4
5
|
SELECT *
FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
Nella query sopra, OFFSET 10 è usato per saltare 10 righe e FETCH 10 ROWS ONLY è usato per estrarre solo 10 righe.
Per ottenere ulteriori informazioni sulla clausola ORDER BY e sulla funzione OFFSET FETCH, fare riferimento alla documentazione ufficiale: Using OFFSET and FETCH to limit the rows returned.
Using OFFSET FETCH to load data in chunks (pagination)
Uno degli scopi principali dell’utilizzo della funzione OFFSET FETCH è quello di caricare i dati in chunks. Immaginiamo di avere un’applicazione che esegue una query SQL e ha bisogno di mostrare i risultati su diverse pagine dove ogni pagina contiene solo 10 risultati (simile al motore di ricerca Google).
La seguente query può essere usata come query di paginazione dove @PageSize è il numero di righe da mostrare in ogni chunk e @PageNumber è il numero di iterazione (pagina):
|
1
2
3
4
5
|
SELECT <alcune colonne>
FROM <nome tabella>
ORDER BY <alcune colonne>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Questo articolo non intende illustrare tutti i casi d’uso della funzione OFFSET FETCH, né discutere le migliori pratiche. Ci sono molti articoli online a cui puoi fare riferimento per maggiori informazioni:
- Paginazione con OFFSET / FETCH : Un modo migliore
- Paginazione in SQL Server usando OFFSET / FETCH
Implementazione della funzione OFFSET FETCH all’interno di SSIS per caricare un grande volume di dati in pezzi
Ci è stato spesso chiesto di costruire un pacchetto SSIS che carica una grande quantità di dati da SQL Server con risorse limitate della macchina. Il caricamento dei dati tramite OLE DB Source utilizzando la modalità di accesso ai dati Table o View causava un’eccezione per esaurimento della memoria.
Una delle soluzioni più semplici è quella di utilizzare la funzione OFFSET FETCH per caricare i dati in chunks per evitare errori di esaurimento della memoria. In questa sezione, forniamo una guida passo-passo sull’implementazione di questa logica all’interno di un pacchetto SSIS.
Innanzitutto, dobbiamo creare un nuovo pacchetto Integration Services, quindi dichiarare quattro variabili come segue:
- RowCount (Int32): Memorizza il numero totale di righe nella tabella sorgente
- IncrementValue (Int32): Memorizza il numero di righe che dobbiamo specificare nella clausola OFFSET (simile a @PageSize * @PageNumber nell’esempio precedente)
- RowsInChunk (Int32): Specifica il numero di righe in ogni chunk di dati (simile a @PageSize nell’esempio sopra)
- SourceQuery (String): Memorizza il comando SQL di origine usato per recuperare i dati
Dopo aver dichiarato le variabili, assegniamo un valore predefinito per la variabile RowsInChunk; in questo esempio, lo impostiamo a 1000. Inoltre, dobbiamo impostare l’espressione Source Query, come segue:
|
1
2
3
4
5
|
“SELECT *
FROM ..
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
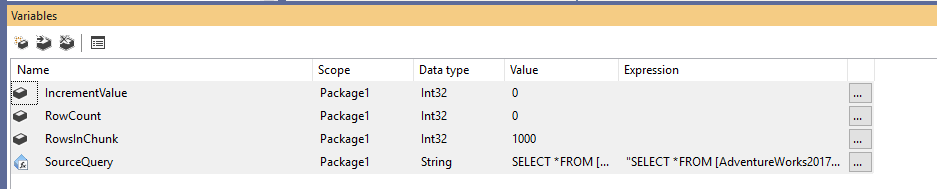
Figura 1 – Aggiunta di variabili
Successivamente, aggiungiamo un Execute SQL Task per ottenere il numero totale di righe nella tabella sorgente. In questo esempio, usiamo la tabella Person memorizzata nel database AdventureWorks2017. Nell’Execute SQL Task, abbiamo usato il seguente statement SQL:
|
1
|
SELECT COUNT(*) FROM ..
|
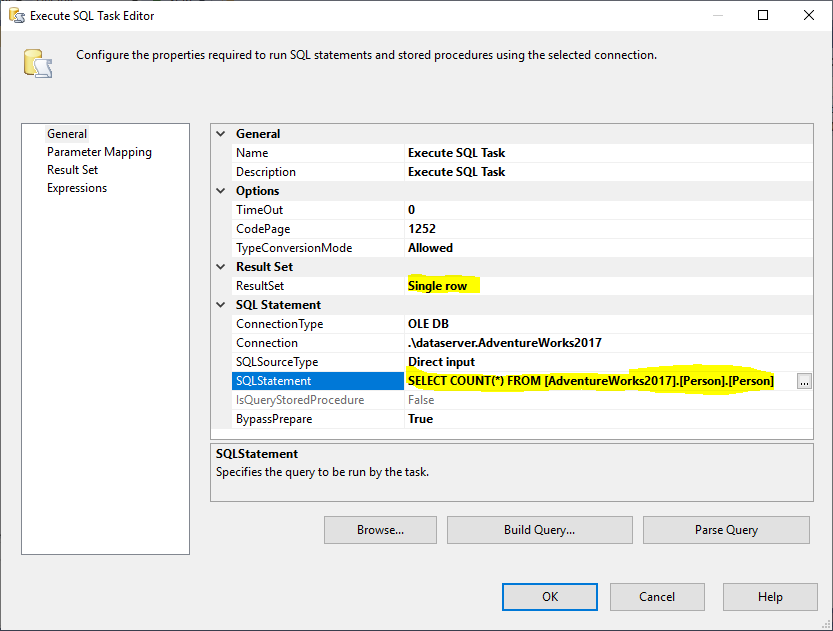
Figura 2 – Impostare Execute SQL Task
E, dobbiamo cambiare la proprietà Result Set in Single Row. Poi, nella scheda Result Set, selezioniamo la variabile RowCount per memorizzare il set di risultati come mostrato nell’immagine sottostante:
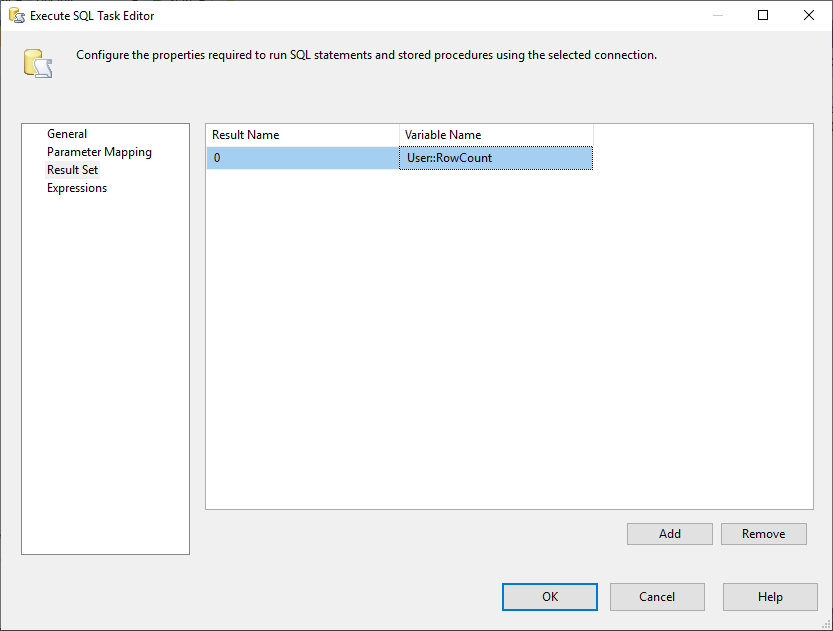
Figura 3 – Mappatura del set di risultati alla variabile
Dopo aver configurato Execute SQL Task, aggiungiamo un contenitore For Loop, con le seguenti specifiche:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
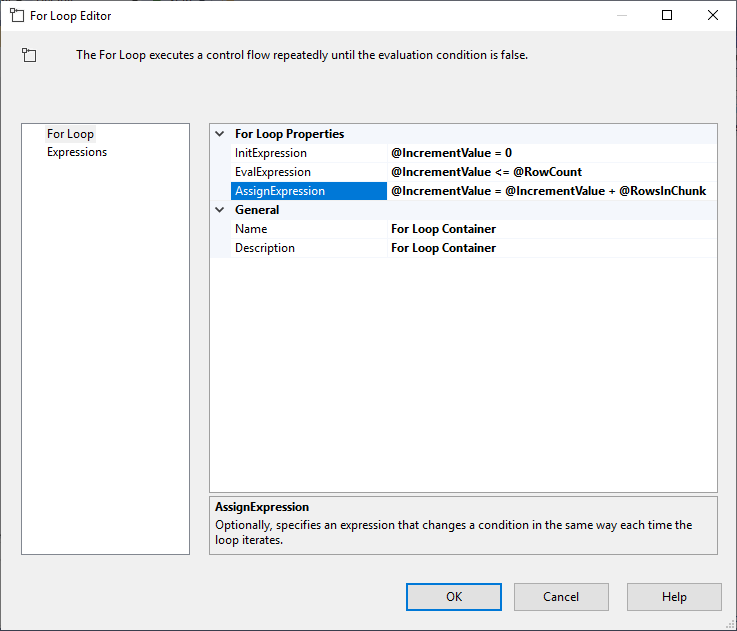
Figura 4 – Configurazione del contenitore For Loop
Dopo aver configurato il contenitore For Loop, aggiungiamo un Data Flow Task al suo interno. Poi, all’interno del Data Flow Task, aggiungiamo un OLE DB Source e OLE DB Destination.
Nel OLE DB Source selezioniamo SQL Command dalla modalità di accesso ai dati variabili, e selezioniamo la variabile @User::SourceQuery come sorgente.
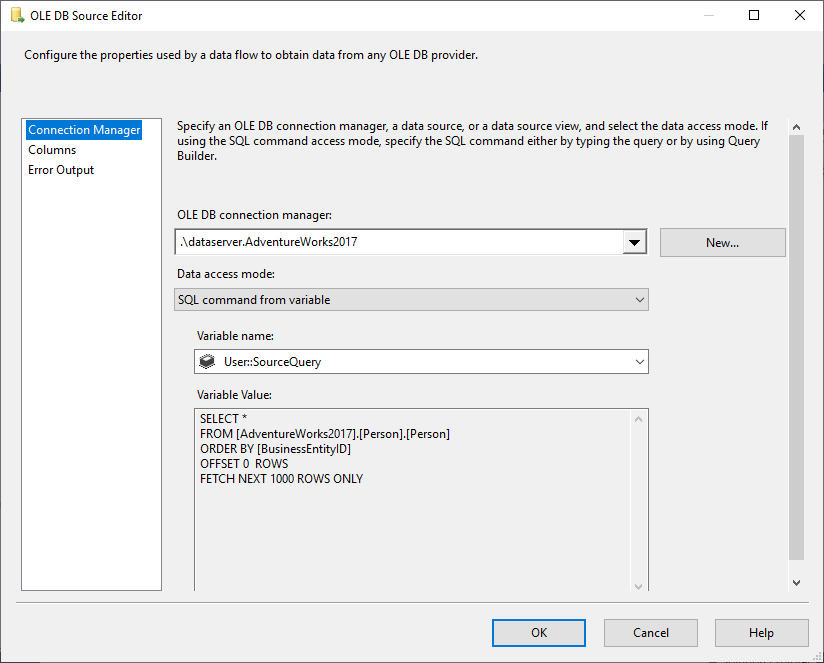
Figura 5 – Configurazione della sorgente OLE DB
Specifichiamo la tabella di destinazione all’interno del componente OLE DB Destination:
Figura 6 – Schermata del task flusso dati
Il flusso di controllo del pacchetto dovrebbe essere come il seguente:
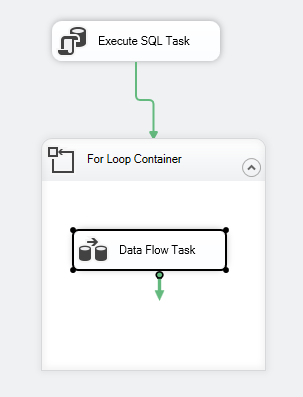
Figura 7 – Schermata del flusso di controllo
Limitazioni
Dopo aver illustrato come caricare i dati in blocchi usando la funzione OFFSET FETCH in SSIS, noteremo che questa logica ha alcune limitazioni:
- Avete sempre bisogno di alcune colonne da usare nella clausola ORDER BY (è preferibile una chiave di identità o primaria), poiché OFFSET FETCH è una caratteristica della clausola ORDER BY e non può essere implementata separatamente
- Se si verifica un errore durante il caricamento dei dati, tutti i dati esportati verso la destinazione vengono impegnati e solo il pezzo di dati corrente viene riportato indietro. Questo può richiedere ulteriori passi per prevenire la duplicazione dei dati quando si esegue nuovamente il pacchetto
OFFSET FETCH usando altri provider di database
Nella sezione seguente, trattiamo brevemente la sintassi usata da altri provider di database:
Oracle
Con Oracle, puoi usare la stessa sintassi di SQL Server. Fate riferimento al seguente link per maggiori informazioni: Oracle FETCH
SQLite
In SQLite, la sintassi è diversa da quella di SQL Server, poiché si usa la funzione LIMIT OFFSET come menzionato di seguito:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
In MySQL, la sintassi è simile a quella di SQLite, poiché si usa LIMIT OFFSET invece di OFFSET Fetch.
DB2
In DB2, la sintassi è simile a SQLite, poiché si usa LIMIT OFFSET invece di OFFSET FETCH.
Conclusione
In questo articolo, abbiamo descritto la funzione OFFSET FETCH presente in SQL Server 2012 e superiori. Abbiamo illustrato come utilizzare questa funzione per creare una query di paginazione, poi abbiamo fornito una guida passo dopo passo su come caricare i dati in blocchi per consentire l’estrazione di grandi quantità di dati utilizzando una macchina con risorse limitate. Infine, abbiamo menzionato alcune limitazioni e le differenze di sintassi con altri fornitori di database.
- Autore
- Postate recenti

Oltre a lavorare con SQL Server, ha lavorato con diverse tecnologie di dati come i database NoSQL, Hadoop, Apache Spark. È un professionista certificato Neo4j e ArangoDB.
A livello accademico, Hadi ha due master in informatica e business computing. Attualmente, è un candidato al dottorato in scienza dei dati che si concentra sulle tecniche di valutazione della qualità dei Big Data.
Hadi ama davvero imparare cose nuove ogni giorno e condividere le sue conoscenze. Potete raggiungerlo sul suo sito web personale.
Vedi tutti i post di Hadi Fadlallah
- Building SSAS OLAP cubes using Biml – March 16, 2021
- Migrare i database grafici di SQL Server a Neo4j – 9 marzo 2021
- Iniziare con il database grafico Neo4j – 5 febbraio 2021