Struttura dei virus
I virus non sono piante, animali o batteri, ma sono i parassiti per eccellenza dei regni viventi. Anche se possono sembrare organismi viventi a causa delle loro prodigiose capacità riproduttive, i virus non sono organismi viventi nel senso stretto della parola.
Senza una cellula ospite, i virus non possono svolgere le loro funzioni vitali o riprodursi. Non possono sintetizzare proteine, perché mancano di ribosomi e devono usare i ribosomi delle loro cellule ospiti per tradurre l’RNA messaggero virale in proteine virali. I virus non possono generare o immagazzinare energia sotto forma di adenosina trifosfato (ATP), ma devono ricavare la loro energia, e tutte le altre funzioni metaboliche, dalla cellula ospite. Inoltre, parassitano la cellula per i materiali di costruzione di base, come aminoacidi, nucleotidi e lipidi (grassi). Anche se i virus sono stati ipotizzati come una forma di protolife, la loro incapacità di sopravvivere senza organismi viventi rende altamente improbabile che abbiano preceduto la vita cellulare durante la prima evoluzione della Terra. Alcuni scienziati ipotizzano che i virus siano nati come segmenti canaglia del codice genetico che si sono adattati a un’esistenza parassitaria.
Tutti i virus contengono acido nucleico, DNA o RNA (ma non entrambi), e un mantello proteico, che racchiude l’acido nucleico. Alcuni virus sono anche racchiusi da un involucro di molecole di grasso e proteine. Nella sua forma infettiva, al di fuori della cellula, una particella virale è chiamata virione. Ogni virione contiene almeno una proteina unica sintetizzata da geni specifici nel suo acido nucleico. I viroidi (che significa “simili ai virus”) sono organismi che causano malattie che contengono solo acido nucleico e non hanno proteine strutturali. Altre particelle simili a virus chiamate prioni sono composte principalmente da una proteina strettamente integrata con una piccola molecola di acido nucleico.
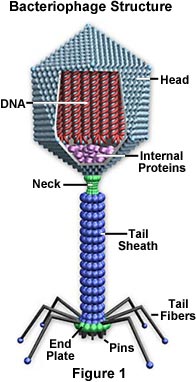
I virus sono generalmente classificati in base agli organismi che infettano, animali, piante o batteri. Poiché i virus non possono penetrare le pareti cellulari delle piante, praticamente tutti i virus delle piante sono trasmessi da insetti o altri organismi che si nutrono di piante. Alcuni virus batterici, come il batteriofago T4, hanno evoluto un elaborato processo di infezione. Il virus ha una “coda” che si attacca alla superficie del batterio per mezzo di “spine” proteiche. La coda si contrae e la spina della coda penetra la parete cellulare e la membrana sottostante, iniettando gli acidi nucleici virali nella cellula. I virus sono ulteriormente classificati in famiglie e generi sulla base di tre considerazioni strutturali: 1) il tipo e la dimensione del loro acido nucleico, 2) la dimensione e la forma del capside, e 3) se hanno un involucro lipidico che circonda il nucleocapside (l’acido nucleico racchiuso nel capside).
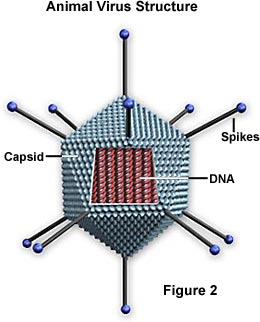
Ci sono principalmente due tipi di forme trovate tra i virus: aste, o filamenti, e sfere. La forma a bastoncino è dovuta alla disposizione lineare dell’acido nucleico e delle subunità proteiche che compongono il capside. La forma a sfera è in realtà un poligono a 20 lati (icosaedro).
La natura dei virus non è stata compresa fino al ventesimo secolo, ma i loro effetti sono stati osservati per secoli. Il medico britannico Edward Jenner scoprì addirittura il principio dell’inoculazione alla fine del XVIII secolo, dopo aver osservato che le persone che avevano contratto la lieve malattia del vaiolo bovino erano generalmente immuni alla più mortale malattia del vaiolo. Alla fine del diciannovesimo secolo, gli scienziati sapevano che qualche agente stava causando una malattia delle piante di tabacco, ma non sarebbe cresciuto su un mezzo artificiale (come i batteri) ed era troppo piccolo per essere visto attraverso un microscopio ottico. I progressi nella coltura di cellule vive e nella microscopia nel ventesimo secolo hanno infine permesso agli scienziati di identificare i virus. I progressi nella genetica migliorarono drasticamente il processo di identificazione.
-
Capside – Il capside è il guscio proteico che racchiude l’acido nucleico; con il suo acido nucleico racchiuso, è chiamato nucleocapside. Questo guscio è composto da proteine organizzate in subunità note come capsomeri. Essi sono strettamente associati all’acido nucleico e riflettono la sua configurazione, un’elica a forma di bastone o una sfera a forma di poligono. Il capside ha tre funzioni: 1) protegge l’acido nucleico dalla digestione degli enzimi, 2) contiene siti speciali sulla sua superficie che permettono al virione di attaccarsi a una cellula ospite, e 3) fornisce proteine che permettono al virione di penetrare la membrana della cellula ospite e, in alcuni casi, di iniettare l’acido nucleico infettivo nel citoplasma della cellula. Nelle giuste condizioni, l’RNA virale in una sospensione liquida di molecole proteiche si auto-assembla un capside per diventare un virus funzionale e infettivo.
-
Involucro – Molti tipi di virus hanno un involucro glicoproteico che circonda il nucleocapside. L’involucro è composto da due strati lipidici intervallati da molecole proteiche (bilayer lipoproteico) e può contenere materiale della membrana di una cellula ospite così come quello di origine virale. Il virus ottiene le molecole lipidiche dalla membrana cellulare durante il processo di gemmazione virale. Tuttavia, il virus sostituisce le proteine della membrana cellulare con le proprie proteine, creando una struttura ibrida di lipidi di origine cellulare e proteine di origine virale. Molti virus sviluppano anche punte fatte di glicoproteine sui loro involucri che li aiutano ad attaccarsi a specifiche superfici cellulari.
-
Acido nucleico – Proprio come nelle cellule, l’acido nucleico di ogni virus codifica le informazioni genetiche per la sintesi di tutte le proteine. Mentre il DNA a doppio filamento è responsabile di questo nelle cellule procariotiche ed eucariotiche, solo alcuni gruppi di virus usano il DNA. La maggior parte dei virus mantengono tutte le loro informazioni genetiche con l’RNA a singolo filamento. Ci sono due tipi di virus basati sull’RNA. Nella maggior parte, l’RNA genomico è definito un filamento positivo perché agisce come RNA messaggero per la sintesi diretta (traduzione) della proteina virale. Alcuni, tuttavia, hanno filamenti negativi di RNA. In questi casi, il virione ha un enzima, chiamato RNA polimerasi RNA-dipendente (trascrittasi), che deve prima catalizzare la produzione di RNA messaggero complementare dall’RNA genomico del virione prima che la sintesi della proteina virale possa avvenire.
Il virus dell’influenza – Dopo il comune raffreddore, l’influenza o “l’influenza” è forse l’infezione respiratoria più familiare al mondo. Solo negli Stati Uniti, circa 25-50 milioni di persone contraggono l’influenza ogni anno. I sintomi dell’influenza sono simili a quelli del comune raffreddore, ma tendono ad essere più gravi. Febbre, mal di testa, affaticamento, debolezza e dolore muscolare, mal di gola, tosse secca e naso chiuso o che cola sono comuni e possono svilupparsi rapidamente. I sintomi gastrointestinali associati all’influenza sono a volte sperimentati dai bambini, ma per la maggior parte degli adulti, le malattie che si manifestano con diarrea, nausea e vomito non sono causate dal virus dell’influenza, anche se spesso vengono definite in modo inesatto “influenza intestinale”. Un certo numero di complicazioni, come l’insorgenza di bronchite e polmonite, possono anche verificarsi in associazione con l’influenza e sono particolarmente comuni tra gli anziani, i bambini piccoli e chiunque abbia un sistema immunitario soppresso.
Il virus dell’immunodeficienza umana (HIV) – Il virus responsabile dell’HIV fu isolato per la prima volta nel 1983 da Robert Gallo degli Stati Uniti e dallo scienziato francese Luc Montagnier. Da allora, è stata condotta un’enorme quantità di ricerche sull’agente causale dell’AIDS e si è imparato molto sulla struttura del virus e sul suo tipico corso d’azione. L’HIV fa parte di un gruppo di virus atipici chiamati retrovirus che mantengono le loro informazioni genetiche sotto forma di acido ribonucleico (RNA). Attraverso l’uso di un enzima noto come trascrittasi inversa, l’HIV e altri retrovirus sono in grado di produrre acido desossiribonucleico (DNA) da RNA, mentre la maggior parte delle cellule svolge il processo opposto, trascrivendo il materiale genetico del DNA in RNA. L’attività dell’enzima permette all’informazione genetica dell’HIV di integrarsi in modo permanente nel genoma (cromosomi) di una cellula ospite.
Torna alla HOME STRUTTURA CELLULARE
Domande o commenti? Inviaci un’e-mail.
© 1995-2021 di Michael W. Davidson e della Florida State University. Tutti i diritti riservati. Nessuna immagine, grafica, software, script o applet può essere riprodotta o utilizzata in qualsiasi modo senza il permesso dei detentori del copyright. L’uso di questo sito web implica l’accettazione di tutti i termini e le condizioni legali stabilite dai proprietari.
Questo sito web è mantenuto dal nostro
Graphics & Web Programming Team
in collaborazione con Optical Microscopy at the
National High Magnetic Field Laboratory.
L’ultima modifica: Friday, Nov 13, 2015 at 02:18 PM
Access Count Since October 1, 2000: 1951931
Microscopi forniti da:
![]()
![]()