Ebben a cikkben bemutatjuk, hogyan használhatjuk az OFFSET FETCH funkciót, mint megoldást nagy mennyiségű adat relációs adatbázisból történő betöltésére egy korlátozott memóriával rendelkező gépen, és hogyan akadályozhatjuk meg, hogy a memória elfogyjon. Leírjuk, hogyan tölthetünk be adatokat kötegekben, hogy elkerüljük a nagy mennyiségű adat memóriába helyezését.
Ez a cikk az első az SSIS Tippek és trükkök sorozatában, amelynek célja néhány bevált gyakorlat bemutatása.
Bevezetés
Amikor az interneten az SSIS adatimporttal kapcsolatos problémákra keresünk, találunk optimális környezetben használható megoldásokat vagy kis mennyiségű adat kezelésére szolgáló oktatóanyagokat. Sajnos ezek a megoldások valós környezetben alkalmatlannak bizonyulnak.
A valóságban a kisebb vállalatok nem mindig tudnak új tároló-, feldolgozóeszközöket és technológiákat bevezetni, pedig egyre nagyobb mennyiségű adatot kell kezelniük. Ez különösen igaz a közösségi médiaelemzésre, mivel elemezniük kell a célközönségük (ügyfeleik) viselkedését.
Hasonlóképpen, nem minden vállalat töltheti fel az adatait a felhőbe a magas költségek miatt, valamint az adatvédelmi és titoktartási kérdések miatt.
OFFSET FETCH funkció
Az OFFSET FETCH az SQL Server 2012 kiadásától kezdve az ORDER BY záradékhoz hozzáadott funkció. Egy adott indexből kiindulva meghatározott számú sor kinyerésére használható. Példának okáért van egy lekérdezésünk, amely 40 sort ad vissza, és a 10. sorból 10 sort kell kinyernünk:
|
1
2
3
4
5
|
SELECT *
. FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
A fenti lekérdezésben, OFFSET 10 10 sor kihagyására, FETCH 10 ROWS ONLY pedig csak 10 sor kinyerésére szolgál.
Az ORDER BY záradékkal és az OFFSET FETCH funkcióval kapcsolatos további információkért olvassa el a hivatalos dokumentációt: OFFSET és FETCH használata a visszaküldött sorok korlátozásához.
Az OFFSET FETCH használata az adatok darabos betöltéséhez (oldalszámozás)
Az OFFSET FETCH funkció használatának egyik fő célja az adatok darabos betöltése. Képzeljük el, hogy van egy alkalmazásunk, amely SQL-lekérdezést hajt végre, és az eredményeket több oldalon kell megjelenítenie, ahol minden oldal csak 10 találatot tartalmaz (hasonlóan a Google keresőmotorjához).
A következő lekérdezés használható lapozási lekérdezésként, ahol a @PageSize az egyes darabokban megjelenítendő sorok száma, a @PageNumber pedig az iteráció (oldal) száma:
|
1
2
3
4
5
|
SELECT <some columns>
FROM <table name>
ORDER BY <some columns>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY;
|
Ennek a cikknek nem célja az OFFSET FETCH funkció összes felhasználási esetének bemutatása, és nem tárgyalja a legjobb gyakorlatokat sem. Az interneten számos olyan cikk található, amelyből további információkat szerezhet:
- Pagination with OFFSET / FETCH : A better way
- Pagination in SQL Server using OFFSET / FETCH
Implementing the OFFSET FETCH feature within SSIS to load a large volume of data in chunks
Gyakran kérik tőlünk, hogy készítsünk olyan SSIS csomagot, amely korlátozott gépi erőforrások mellett nagy mennyiségű adatot tölt be az SQL Serverről. Az adatok betöltése az OLE DB Forrás segítségével Table vagy View adatelérési móddal memóriahiányos kivételt okozott.
Az egyik legegyszerűbb megoldás az OFFSET FETCH funkció használata az adatok darabokban történő betöltéséhez, hogy megelőzzük a memóriahiányos hibákat. Ebben a részben lépésről lépésre bemutatjuk, hogyan lehet ezt a logikát egy SSIS csomagban megvalósítani.
Először is létre kell hoznunk egy új Integration Services csomagot, majd négy változót kell deklarálnunk a következőképpen:
- RowCount (Int32):
- IncrementValue (Int32): Az OFFSET záradékban megadandó sorok számát tárolja (hasonlóan a fenti példában szereplő @PageSize * @PageNumber értékhez)
- RowsInChunk (Int32): Megadja az egyes adatdarabokban lévő sorok számát (Hasonlóan a fenti példában szereplő @PageSize-hoz)
- SourceQuery (String): Az adatok lekérdezéséhez használt SQL-forrásparancsot tárolja
A változók deklarálása után a RowsInChunk változóhoz alapértelmezett értéket rendelünk; ebben a példában 1000-re állítjuk. Továbbá meg kell adnunk a Source Query kifejezést, a következőképpen:
|
1
2
3
4
5
|
“SELECT *
FROM …
ORDER BY
OFFSET ” + (DT_WSTR,50)@ + ” ROWS
FETCH NEXT ” + (DT_WSTR,50) @ + ” ROWS ONLY”
|
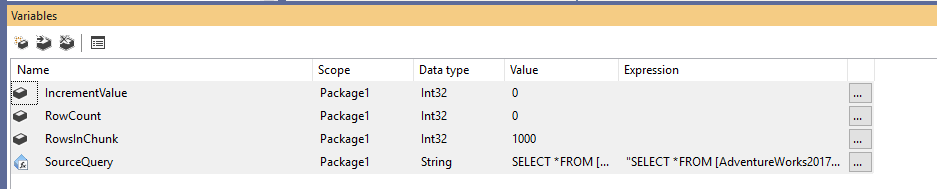
1. ábra – Változók hozzáadása
Ezután hozzáadunk egy Execute SQL Tasket, hogy megkapjuk a forrás táblában lévő sorok teljes számát. Ebben a példában az AdventureWorks2017 adatbázisban tárolt Person táblát használjuk. Az Execute SQL Taskben a következő SQL utasítást használtuk:
|
1
|
SELECT COUNT(*) FROM …
|
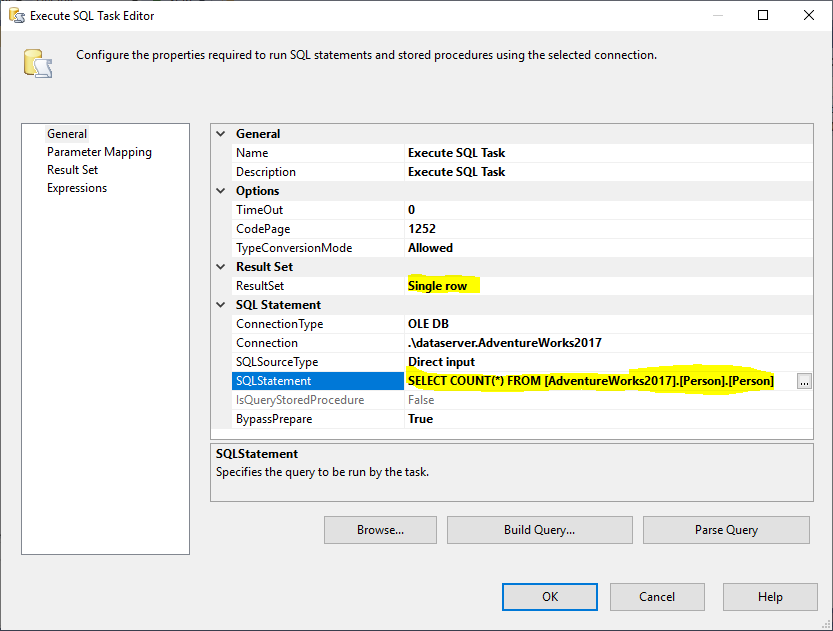
2. ábra – Execute SQL Task
beállítása És, meg kell változtatnunk a Result Set tulajdonságot Single Row-ra. Ezután a Result Set fülön kiválasztjuk a RowCount változót az eredményhalmaz tárolásához, ahogy az alábbi képen látható:
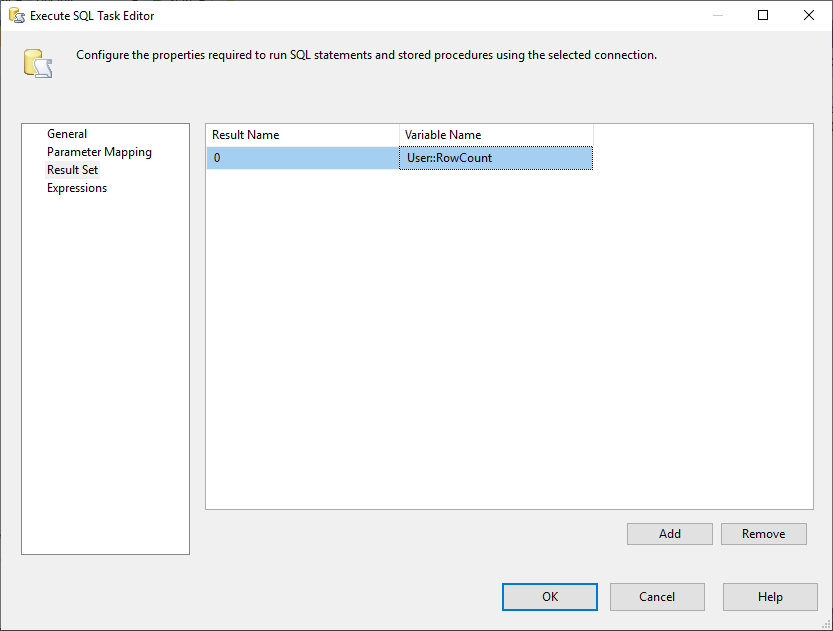
3. ábra – Az eredményhalmaz leképezése változóra
Az Execute SQL Task beállítása után hozzáadunk egy For Loop Container-t, a következő specifikációkkal:
- InitExpression:
- EvalExpression: @IncrementValue = 0
- EvalExpression:
- AssignExpression: @IncrementValue <= @RowCount
- AssignExpression:
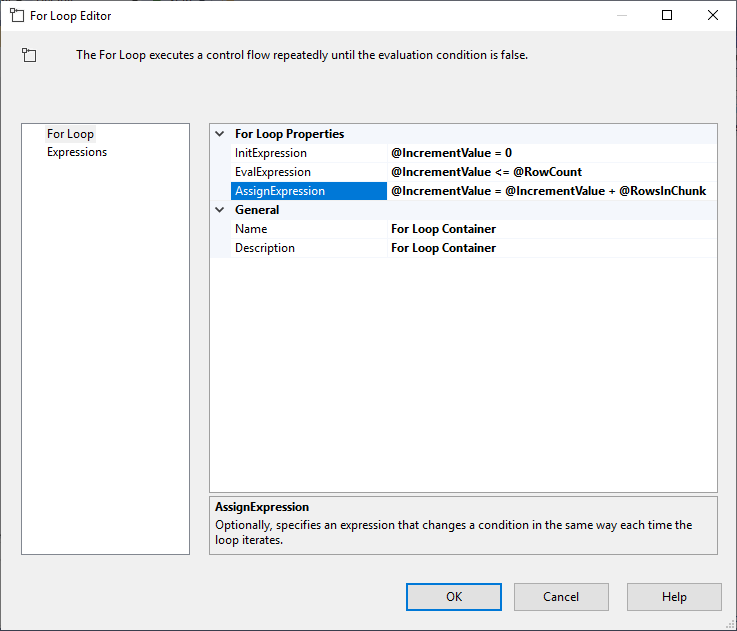
4. ábra – For Loop konténer konfigurálása
A For Loop konténer konfigurálása után hozzáadunk egy adatáramlási feladatot. Ezután az adatáramlási feladaton belül hozzáadunk egy OLE DB forrást és egy OLE DB célt.
Az OLE DB forrásban a változó adatelérési módból kiválasztjuk az SQL parancsot, forrásként pedig a @User::SourceQuery változót.
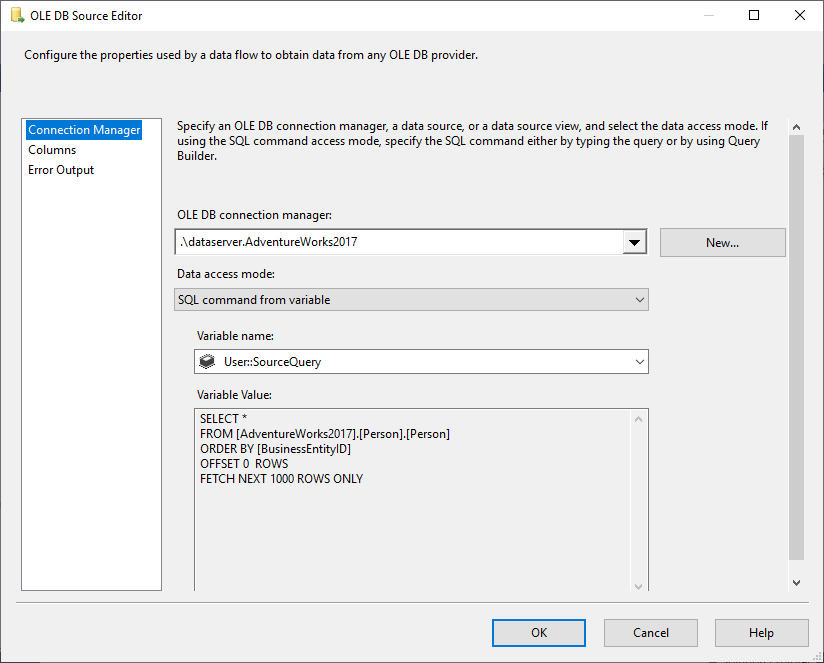
5. ábra – OLE DB forrás konfigurálása
Az OLE DB cél komponensben megadjuk a céltáblát:
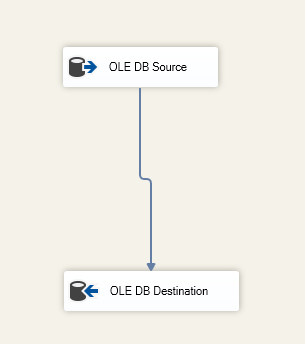
6. ábra – Adatáramlási feladat képernyőkép
A csomag vezérlési folyamata a következőképpen kell kinézzen:
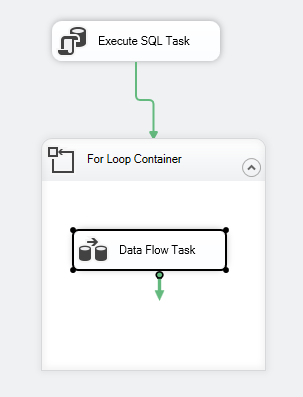
7. ábra – Vezérlési folyamat képernyőkép
Korlátozások
Miután bemutattuk, hogyan tölthetünk be adatokat darabokban az SSIS OFFSET FETCH funkciójának használatával, megjegyezzük, hogy ennek a logikának vannak bizonyos korlátai:
- Mindig szükség van néhány oszlopra, amelyet az ORDER BY záradékban kell használni (az azonosság vagy az elsődleges kulcs előnyös), mivel az OFFSET FETCH az ORDER BY záradék egyik jellemzője, és nem lehet külön megvalósítani
- Ha az adatok betöltése során hiba lép fel, a célállomásra exportált összes adat lekötésre kerül, és csak az aktuális adatfoszlányt görgetjük vissza. Ez a csomag újbóli futtatásakor további lépéseket igényelhet az adatok duplikálódásának megakadályozására
OFFSET FETCH más adatbázis-szolgáltatók használatával
A következő részben röviden kitérünk a többi adatbázis-szolgáltató által használt szintaxisra:
Oracle
Az Oracle esetében az SQL Serverrel megegyező szintaxis használható. További információért tekintse meg az alábbi linket: Oracle FETCH
SQLite
Az SQLite esetében a szintaxis eltér az SQL Serverétől, mivel az alábbiakban említett LIMIT OFFSET funkciót használja:
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
A MySQL, a szintaxis hasonló az SQLite-hoz, mivel az OFFSET Fetch helyett a LIMIT OFFSET-et használjuk.
DB2
A DB2-ben a szintaxis hasonló az SQLite-hoz, mivel az OFFSET FETCH helyett a LIMIT OFFSET-et használja.
Következtetés
Ebben a cikkben az SQL Server 2012 és újabb verziókban található OFFSET FETCH funkciót ismertettük. Bemutattuk, hogyan használhatjuk ezt a funkciót egy lapozó lekérdezés létrehozásához, majd lépésről lépésre ismertettük, hogyan tölthetjük be az adatokat darabokban, hogy lehetővé tegyük nagy mennyiségű adat kinyerését egy korlátozott erőforrásokkal rendelkező gép segítségével. Végül megemlítettünk néhány korlátozást és a más adatbázis-szolgáltatókkal szembeni szintaktikai különbségeket.
- Author
- Recent Posts

Az SQL Serverrel való munka mellett különböző adattechnológiákkal is dolgozott, mint például NoSQL adatbázisok, Hadoop, Apache Spark. Neo4j és ArangoDB tanúsítvánnyal rendelkezik.
Akadémiai szinten Hadi két mesterdiplomával rendelkezik informatikából és üzleti számítástechnikából. Jelenleg az adattudományok területén doktorál, és a Big Data minőségértékelési technikákra összpontosít.
Hadi nagyon élvezi, hogy minden nap új dolgokat tanulhat és megoszthatja a tudását. Személyes weboldalán érhető el.
Hadi Fadlallah összes bejegyzése
- SSAS OLAP kockák építése Biml segítségével – március 16, 2021
- SQL Server grafikus adatbázisok migrálása a Neo4j-be – 2021. március 9.
- Kezdő lépések a Neo4j grafikus adatbázissal – 2021. február 5.