Statistiques descriptives
Pour ce tutoriel, nous allons utiliser le jeu de données auto livré avec Stata. Pour charger ces données, tapez
sysuse auto, clearLe jeu de données auto a les variables suivantes.
describe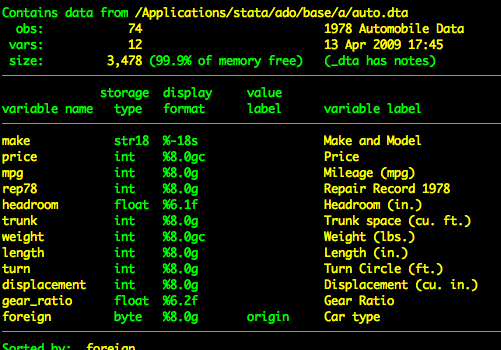
Supposons que nous voulions obtenir des statistiques résumées pour le prix, comme la moyenne, l’écart type et l’étendue. Nous utiliserons la commande summarize.
summarize price
Maintenant, ajoutons l’option detail à summarize. Cela nous donnera beaucoup plus d’informations, notamment la médiane et les autres percentiles.
summarize price, detail
Multiples variables à la fois
Pour obtenir les descriptifs de plusieurs variables à la fois, il suffit d’ajouter les noms des variables après summarize.
summarize price mpg
Ajouter l’option detail.
summarize price mpg, detail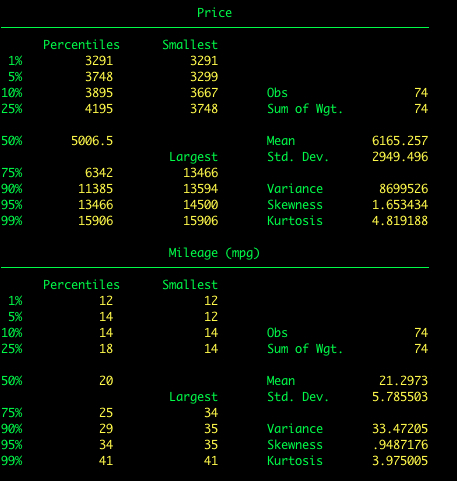
Utiliser par traitement
Supposons que nous voulions obtenir les statistiques descriptives du prix par type de voiture (étrangère vs nationale). Nous pouvons utiliser ce que l’on appelle le bytraitement.
by foreign: summarize price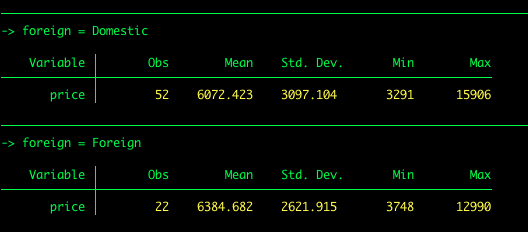
Lorsque l’on utilise la commande by, la variable d’intérêt doit être triée dans l’ensemble de données. Par exemple, dans l’exemple précédent, la variable « étranger » est déjà triée dans notre ensemble de données. Si nous voulions examiner le prix en fonction du kilométrage, nous devrions trier les miles par gallon. Une façon de trier les données est d’utiliser une simple commande de tri suivie du nom de la variable. Par défaut, Stata triera les données par ordre croissant.
sort mpgAprès avoir trié les données, nous pouvons ensuite utiliser la commande standard by mpg :. Dans le traitement by, nous pouvons également trier les données et exécuter la commande by en même temps en utilisant la commande bysort:
bysort mpg: summarize priceLa commande by peut également être utilisée dans d’autres commandes, comme la création de graphiques. Par exemple, si nous voulions examiner les histogrammes de mpg en fonction de la marque de la voiture, nous utiliserions la commande by en option. La marque de la voiture n’a pas besoin d’être triée pour cette commande.
histogram(mpg), by(foreign)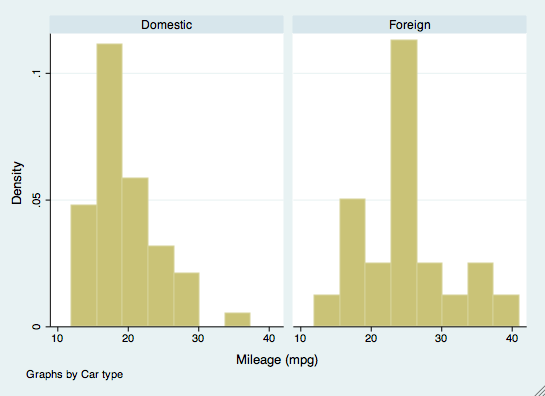
Utiliser if
L’instruction by nous donnera des descriptifs pour tous les niveaux de la variable by (c’est-à-dire à la fois étrangers et nationaux). Supposons que nous ne voulons que les descriptions d’un seul niveau de la variable by. Nous pouvons utiliser l’instruction if pour cela. Pour les voitures étrangères (c’est-à-dire foreign == 1):
summarize price if foreign == 1
Pour les voitures nationales (c’est-à-dire, foreign == 0)
summarize price if foreign == 0
Ce tableau est destiné à aider à déterminer comment spécifier les niveaux de la variable que vous voulez utiliser.
Symbole |
Message |
| == | est ou est égal à |
| != ou ~= | n’est pas ou n’est pas égal à |
| > | est supérieur à |
| >= | est supérieur ou égale à |
| < | est inférieure à |
| <= | est inférieure ou égale à |
| *Depuis pg. 74 de A Gentle Introduction to Stata par Alan Acock | |
Utilisation dans
Le qualificateur in spécifie un sous-ensemble particulier de cas basé sur leur ordre dans l’ensemble de données. Par exemple, si nous voulons examiner le mpg dans les 10 voitures les moins chères, nous utiliserons la commande in.
sort pricesummarize mpg in 1/10
Comme indication utile pour l’un de ces processus, si vos variables sont étiquetées (montrant l’étiquette au lieu de la valeur numérique) et que vous devez trouver les valeurs numériques pour examiner les niveaux de la variable, vous pouvez utiliser l’option nolabel.
browse, nolabelCeci vous montrera les valeurs numériques des variables. Vous pouvez également trouver ces valeurs en double-cliquant dessus dans le navigateur de données.