Dans cet article, nous illustrons comment utiliser la fonctionnalité OFFSET FETCH comme solution pour charger de grands volumes de données à partir d’une base de données relationnelle en utilisant une machine avec une mémoire limitée et en évitant une exception de mémoire insuffisante. Nous décrivons comment charger des données par lots pour éviter de placer une grande quantité de données en mémoire.
Cet article est le premier de la série de conseils et d’astuces SSIS qui vise à illustrer certaines bonnes pratiques.
Introduction
Lorsque vous recherchez en ligne des problèmes liés à l’importation de données SSIS, vous trouverez des solutions utilisables dans des environnements optimaux ou des tutoriels pour traiter une petite quantité de données. Malheureusement, ces solutions s’avèrent inadaptées dans un environnement réel.
En réalité, les petites entreprises ne peuvent pas toujours adopter de nouveaux équipements de stockage, de traitement et de nouvelles technologies alors qu’elles doivent toujours traiter une quantité croissante de données. Cela est particulièrement vrai pour l’analyse des médias sociaux puisqu’elles doivent analyser le comportement de leur public cible (clients).
De même, toutes les entreprises ne peuvent pas télécharger leurs données dans le cloud en raison du coût élevé ainsi que des problèmes de confidentialité des données.
Fonction OFFSET FETCH
OFFSET FETCH est une fonction ajoutée à la clause ORDER BY à partir de l’édition 2012 de SQL Server. Elle peut être utilisée pour extraire un nombre spécifique de lignes à partir d’un index spécifique. A titre d’exemple, nous avons une requête qui renvoie 40 lignes et nous avons besoin d’extraire 10 lignes à partir de la 10e ligne :
|
1
2
3
4
5
|
SELECT *
FROM Table
ORDER BY ID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY
|
Dans la requête ci-dessus, OFFSET 10 est utilisé pour sauter 10 lignes et FETCH 10 ROWS ONLY est utilisé pour extraire seulement 10 lignes.
Pour obtenir des informations supplémentaires sur la clause ORDER BY et la fonctionnalité OFFSET FETCH, consultez la documentation officielle : Utilisation de OFFSET et FETCH pour limiter les lignes renvoyées.
Utilisation de OFFSET FETCH pour charger des données par morceaux (pagination)
L’un des principaux objectifs de l’utilisation de la fonctionnalité OFFSET FETCH est de charger des données par morceaux. Imaginons que nous avons une application qui exécute une requête SQL et qui a besoin d’afficher les résultats sur plusieurs pages où chaque page ne contient que 10 résultats (similaire au moteur de recherche Google).
La requête suivante peut être utilisée comme une requête de pagination où @PageSize est le nombre de lignes que vous devez montrer dans chaque chunk et @PageNumber est le numéro d’itération (page) :
|
1
2
3
4
5
|
SELECT <certaines colonnes>
FROM <table name>
ORDER BY <some columns>
OFFSET @PageSize * @PageNumber ROWS
FETCH NEXT @PageSize ROWS ONLY ;
|
Cet article n’a pas pour but d’illustrer tous les cas d’utilisation de la fonctionnalité OFFSET FETCH, ni de discuter des meilleures pratiques. Il existe de nombreux articles en ligne auxquels vous pouvez vous référer pour plus d’informations :
- Pagination avec OFFSET / FETCH : Une meilleure façon
- Pagination dans SQL Server en utilisant OFFSET / FETCH
Mise en œuvre de la fonctionnalité OFFSET FETCH dans SSIS pour charger un grand volume de données par morceaux
On nous a souvent demandé de construire un package SSIS qui charge une énorme quantité de données à partir de SQL Server avec des ressources machine limitées. Le chargement des données à l’aide de la source OLE DB en utilisant le mode d’accès aux données Table ou View provoquait une exception d’absence de mémoire.
L’une des solutions les plus simples consiste à utiliser la fonctionnalité OFFSET FETCH pour charger les données par morceaux afin d’éviter les erreurs d’absence de mémoire. Dans cette section, nous fournissons un guide étape par étape sur la mise en œuvre de cette logique dans un package SSIS.
Tout d’abord, nous devons créer un nouveau package Integration Services, puis déclarer quatre variables comme suit :
- RowCount (Int32) : Stocke le nombre total de lignes dans la table source
- IncrementValue (Int32) : Stocke le nombre de lignes que nous devons spécifier dans la clause OFFSET (similaire à @PageSize * @PageNumber dans l’exemple ci-dessus)
- RowsInChunk (Int32) : Spécifie le nombre de lignes dans chaque chunk de données (similaire à @PageSize dans l’exemple ci-dessus)
- SourceQuery (String) : Stocke la commande SQL source utilisée pour récupérer les données
Après avoir déclaré les variables, nous attribuons une valeur par défaut pour la variable RowsInChunk ; dans cet exemple, nous la définirons à 1000. De plus, nous devons définir l’expression de la requête source, comme suit :
|
1
2
3
4
5
|
« SELECT *
FROM …
ORDER BY
OFFSET » + (DT_WSTR,50)@ + » ROWS
FETCH NEXT » + (DT_WSTR,50) @ + » ROWS ONLY »
|
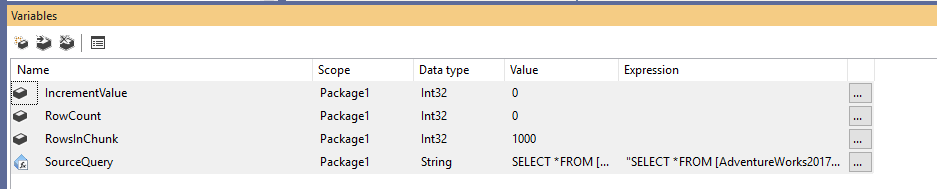
Figure 1 – Ajout de variables
Ensuite, nous ajoutons une tâche SQL Execute pour obtenir le nombre total de lignes dans la table source. Dans cet exemple, nous utilisons la table Personne stockée dans la base de données AdventureWorks2017. Dans la tâche SQL d’exécution, nous avons utilisé l’instruction SQL suivante:
|
1
|
SELECT COUNT(*) FROM …
|
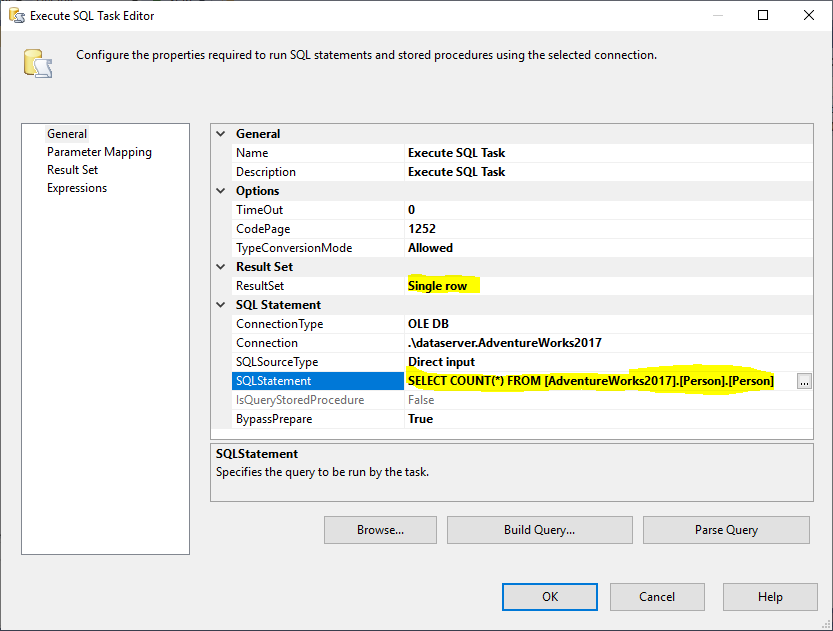
Figure 2 – Configuration de la tâche d’exécution SQL
Et, nous devons changer la propriété Result Set à Single Row. Ensuite, dans l’onglet Result Set, nous sélectionnons la variable RowCount pour stocker l’ensemble de résultats, comme le montre l’image ci-dessous:
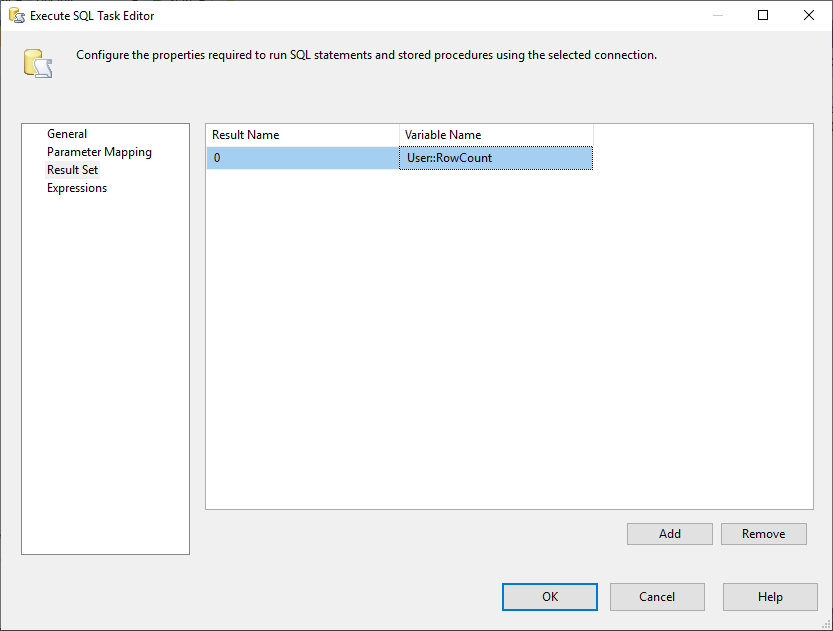
Figure 3 – Mappage de l’ensemble de résultats à la variable
Après avoir configuré la tâche Execute SQL, nous ajoutons un conteneur For Loop, avec les spécifications suivantes:
- InitExpression : @IncrementValue = 0
- EvalExpression : @IncrementValue <= @RowCount
- AssignExpression : @IncrementValue = @IncrementValue + @RowsInChunk
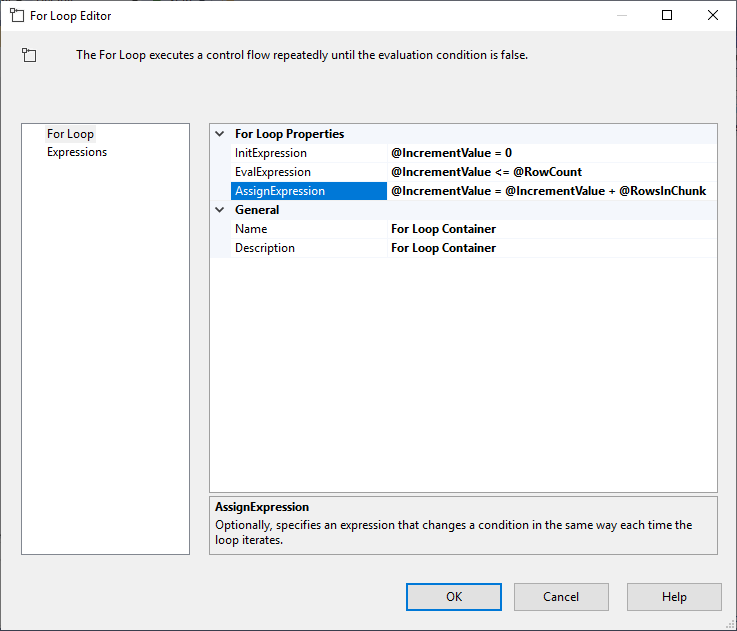
Figure 4 – Configuration du conteneur For Loop
Après avoir configuré le conteneur For Loop, nous ajoutons une tâche de flux de données à l’intérieur de celui-ci. Ensuite, à l’intérieur de la tâche de flux de données, nous ajoutons une source OLE DB et une destination OLE DB.
Dans la source OLE DB, nous sélectionnons la commande SQL à partir du mode d’accès aux données variables, et nous sélectionnons la variable @User::SourceQuery comme source.
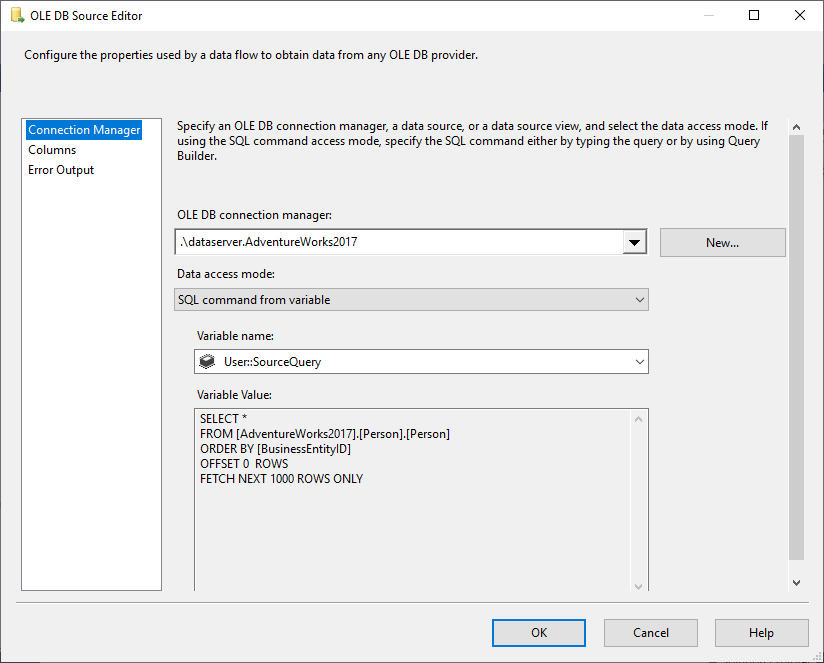
Figure 5 – Configuration de la source OLE DB
Nous spécifions la table de destination dans le composant OLE DB Destination:
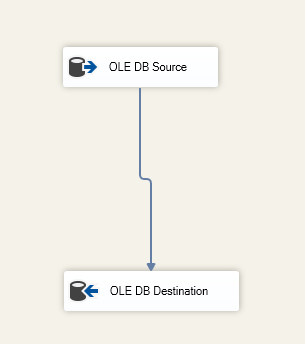
Figure 6 – Capture d’écran de la tâche de flux de données
Le flux de contrôle du paquet devrait ressembler à ce qui suit :
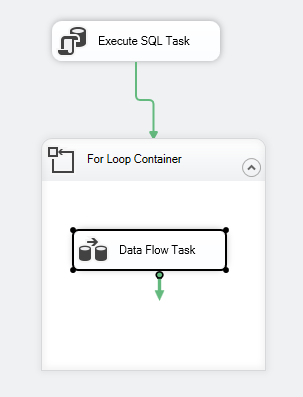
Figure 7 – Capture d’écran du flux de contrôle
Limitations
Après avoir illustré la manière de charger des données par morceaux à l’aide de la fonctionnalité OFFSET FETCH de SSIS, nous noterons que cette logique présente certaines limites :
- Vous avez toujours besoin de certaines colonnes à utiliser dans la clause ORDER BY (l’identité ou la clé primaire est préférable), puisque OFFSET FETCH est une fonctionnalité de la clause ORDER BY et qu’elle ne peut pas être implémentée séparément
- Si une erreur se produit lors du chargement des données, toutes les données exportées vers la destination sont validées et seul le chunk de données actuel est annulé. Cela peut nécessiter des étapes supplémentaires pour éviter la duplication des données lors d’une nouvelle exécution du package
OFFSET FETCH en utilisant d’autres fournisseurs de bases de données
Dans la section suivante, nous couvrons brièvement la syntaxe utilisée par d’autres fournisseurs de bases de données :
Oracle
Avec Oracle, vous pouvez utiliser la même syntaxe que SQL Server. Reportez-vous au lien suivant pour plus d’informations : Oracle FETCH
SQLite
Avec SQLite, la syntaxe est différente de celle de SQL Server, puisque vous utilisez la fonctionnalité LIMIT OFFSET comme mentionné ci-dessous :
|
1
2
3
|
SELECT * FROM MYTABLE ORDER BY ID_COLUMN
LIMIT 50
OFFSET 10
|
MySQL
Dans MySQL, la syntaxe est similaire à celle de SQLite, puisque vous utilisez LIMIT OFFSET au lieu de OFFSET Fetch.
DB2
Dans DB2, la syntaxe est similaire à SQLite, puisque vous utilisez LIMIT OFFSET au lieu de OFFSET FETCH.
Conclusion
Dans cet article, nous avons décrit la fonctionnalité OFFSET FETCH présente dans SQL Server 2012 et plus. Nous avons illustré comment utiliser cette fonctionnalité pour créer une requête de pagination, puis nous avons fourni un guide étape par étape sur la façon de charger des données par morceaux pour permettre l’extraction de grandes quantités de données à l’aide d’une machine aux ressources limitées. Enfin, nous avons mentionné certaines des limitations et des différences de syntaxe avec d’autres fournisseurs de bases de données.
- Auteur
- Postages récents

En plus de travailler avec SQL Server, il a travaillé avec différentes technologies de données telles que les bases de données NoSQL, Hadoop, Apache Spark. Il est un professionnel certifié Neo4j et ArangoDB.
Au niveau académique, Hadi détient deux maîtrises en informatique et en informatique de gestion. Actuellement, il est candidat au doctorat en science des données en se concentrant sur les techniques d’évaluation de la qualité des Big Data.
Hadi aime vraiment apprendre de nouvelles choses tous les jours et partager ses connaissances. Vous pouvez le joindre sur son site web personnel.
Voir tous les messages de Hadi Fadlallah
- Construire des cubes OLAP SSAS en utilisant Biml – 16 mars, 2021
- Migration des bases de données graphiques SQL Server vers Neo4j – 9 mars 2021
- Démarrer avec la base de données graphique Neo4j – 5 février 2021
.